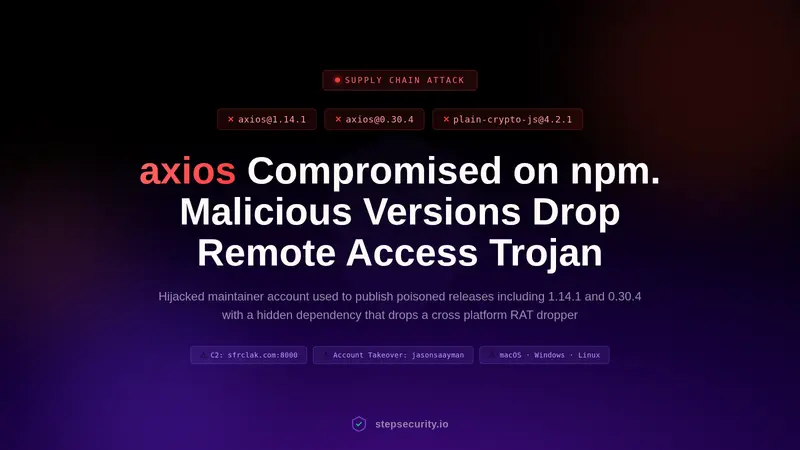
Andrej Karpathy 又给“氛围编程”爱好者送礼物了。
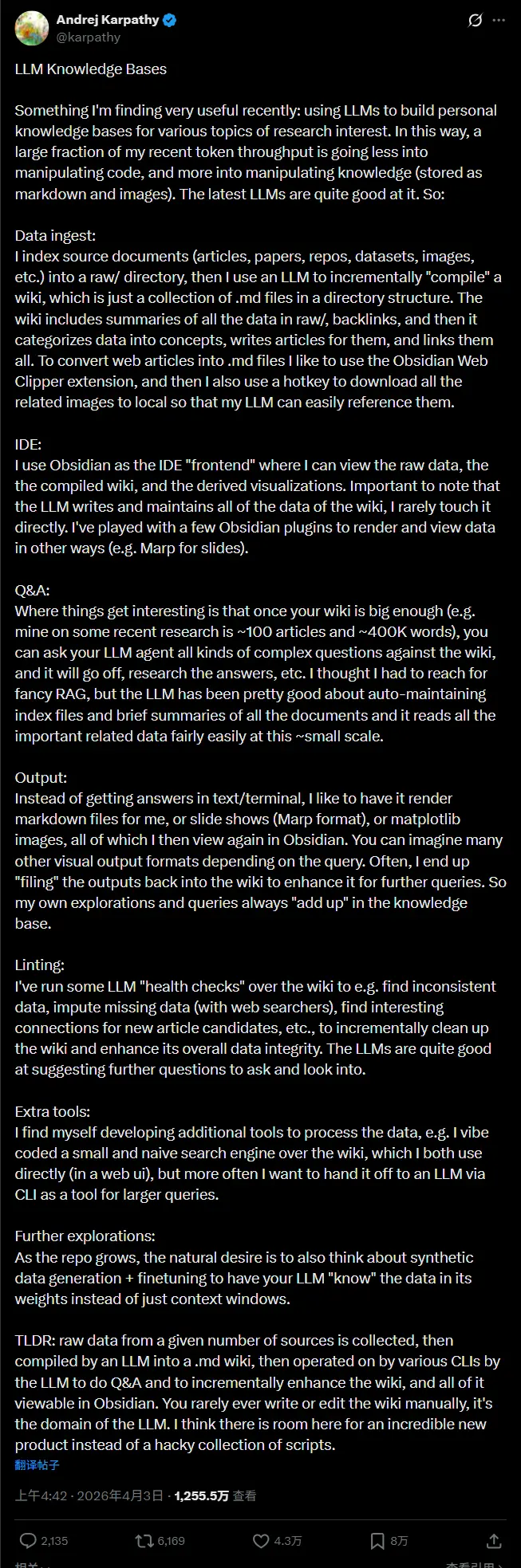
这位特斯拉前 AI 总监、OpenAI 联合创始人,最近在 X 上分享了他正在使用的一套“LLM 知识库”架构。核心思路很简单,却极具颠覆性:与其依赖复杂的向量数据库和 RAG(检索增强生成),不如让 LLM 自己当一名“图书管理员”,维护一个基于 Markdown 的、不断进化的知识库。
为什么我们要绕过 RAG?
过去三年,让 AI 访问私有数据的主流方案是 RAG:把文档切成碎片,变成数学向量,存进数据库。问问题时,系统去搜相似的片段,再扔给 AI。
但这套流程有个大问题:它是“无状态”的。
每次会话结束,AI 就“失忆”了。下次你再问,它得重新去向量库里捞碎片,拼凑上下文。这不仅慢,而且容易出错——你很难知道 AI 引用的那个片段到底在说什么,因为它只是数学上的“相似”,而非逻辑上的“关联”。
Karpathy 的方案,拒绝了这种黑盒。
- 地址:https://x.com/karpathy/status/2039805659525644595
三层架构:从原始数据到活体维基
他的系统分为三个阶段,完全基于人类可读的 Markdown 文件:
- 数据摄入(Raw):
所有原始材料——论文、GitHub 代码、网页文章——都被丢进raw/目录。Karpathy 用 Obsidian Web Clipper 把网页转成 Markdown,连图片也本地保存。这一步,只做存储,不做处理。 - 编译步骤(Compile):
这是核心创新。LLM 读取raw/里的内容,主动“编译”出一个结构化的维基。
它不只是简单摘要,而是像写百科全书一样:提炼关键概念,撰写条目,并在相关想法之间建立反向链接。比如,提到“Transformer”时,它会自动链接到之前写过的“注意力机制”条目。 - 主动维护(Maintain):
知识库不是死的。LLM 会定期运行“健康检查”,扫描维基里的不一致、缺失数据或新出现的连接。如果发现两篇文章讲的是同一件事但没关联,它会主动补上链接。正如社区成员所说,这是一个“能自我修复”的知识库。
好处显而易见:
- 可审计:AI 说的每句话,都能追溯到具体的 .md 文件。你可以直接打开文件查看、编辑或删除。
- 可复合:知识不再是孤立的碎片,而是通过链接形成网络。随着时间推移,这个网络越来越密,AI 的理解也越来越深。
- 简单高效:对于个人研究者或小团队(几百篇文章规模),这套基于文本搜索(grep/FTS5)的方案,比维护庞大的向量集群要轻量得多,延迟也更低。
从个人工具到企业机会
Karpathy 承认,他现在用的只是一堆“粗糙脚本”。但这背后蕴藏着巨大的产品机会。
企业家 Vamshi Reddy 指出:“每个企业都有一个 raw/ 目录(Slack 记录、PDF 报告、内部 Wiki),但从来没人‘编译’过它。这就是产品。”
想象一下,一个企业级的“Karpathy 风格”层:它不只是搜索文档,而是主动撰写一份实时更新的“公司圣经”。新员工入职,不用翻遍几千条 Slack 消息,直接问 AI,它给出的答案来自经过整理、验证、链接的知识库,而非随机抽取的片段。
目前,已有初创公司如 Secondmate 在探索多智能体编排下的“集群知识库”,引入专门的“质量门”模型(如 Hermes)来验证 AI 生成的条目,防止幻觉污染整个库。
文件优于应用
Karpathy 的选择也体现了一种理念:数据主权。
他选用 Markdown,因为它是开放标准。哪怕 Obsidian 明天倒闭,他的文件依然能用任何文本编辑器打开。他选用本地优先的工具,因为数据掌握在自己手里,AI 只是一个高级编辑器,而非数据的拥有者。
这与 Notion 或 Google Docs 等 SaaS 模式形成鲜明对比。在后者的世界里,你的知识被困在平台里;而在 Karpathy 的世界里,你拥有知识,AI 只是帮你打理它的管家。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...