ComfyUI-OmniVoice-TTS 是将小米团队开源的 OmniVoice 模型集成到 ComfyUI 的强大自定义节点。它支持 600+ 种语言 的零样本文本转语音(TTS),具备业界领先的音质、极速的推理速度(RTF 0.025)以及强大的语音克隆和声音设计能力。
- GitHub:https://github.com/Saganaki22/ComfyUI-OmniVoice-TTS
无论是制作多语言有声书、克隆特定音色,还是生成带有情感的非语言表达(如笑声、叹息),该节点都能在你的本地 ComfyUI 工作流中轻松实现。
核心特性
- 600+ 语言覆盖:目前零样本 TTS 模型中语言支持最广泛的,完美支持中文方言及全球小语种。
- 高保真语音克隆:仅需 3-15 秒 的参考音频,即可精准复刻说话人的音色、语调和情感。
- 声音设计 (Voice Design):无需参考音频,通过文本描述(如“年轻女性,高音调,英国口音”)直接合成全新声音。
- 多说话人对话:支持在一段文本中通过
[Speaker_N]:标签定义多个角色,自动生成自然的多角色对话音频。 - 极速推理:优化后的架构使 RTF 低至 0.025(比实时快 40 倍),适合批量生成。
- 非语言表达:内联支持
[laughter],[sigh],[sniff]等标签,让语音充满情感和生命力。 - 显存优化:支持自动 CPU 卸载、Bfloat16 量化模型,并集成 SageAttention (CUDA SM80+) 进一步加速。
- 智能缓存:自动缓存 Whisper ASR 模型和 TTS 主模型,避免重复加载,提升工作流效率。
安装指南
方法一:ComfyUI Manager(推荐)
- 打开 ComfyUI Manager。
- 搜索
OmniVoice。 - 点击安装并重启 ComfyUI。
方法二:手动安装
cd ComfyUI/custom_nodes
git clone https://github.com/saganaki22/ComfyUI-OmniVoice-TTS.git
cd ComfyUI-OmniVoice-TTS
python install.py
⚠️ 重要提示:安装脚本使用了
--no-deps参数来安装omnivoice包,这是为了防止其依赖项强制降级你的 PyTorch 版本(特别是避免降级为 CPU 版),从而破坏 ComfyUI 的 GPU 加速功能。如果遇到问题,请检查 PyTorch 版本兼容性。
节点详解
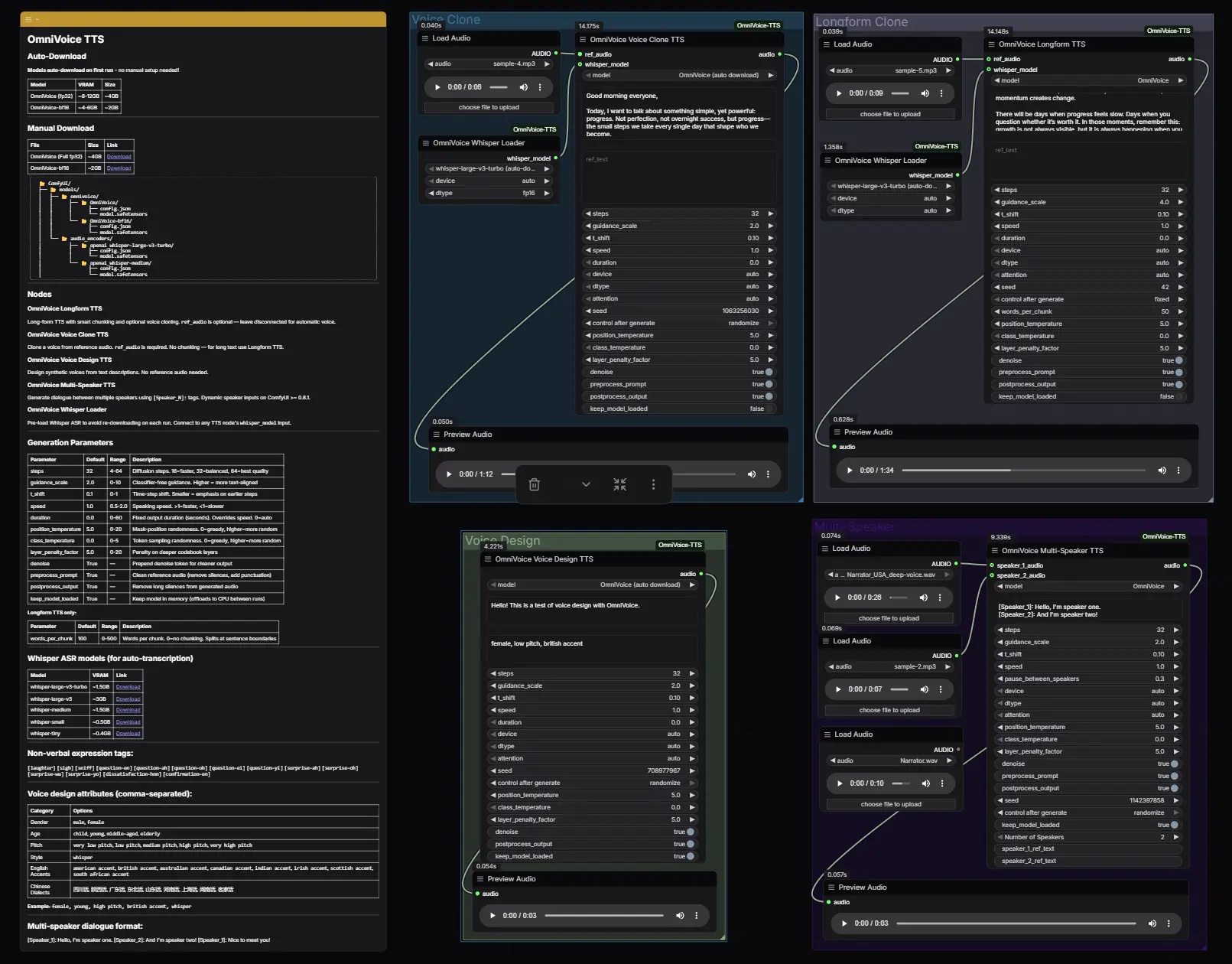
1. OmniVoice Longform TTS (长文本合成)
适用于长篇内容,内置智能分块逻辑,避免显存溢出。
- 关键参数:
words_per_chunk: 每块词数(默认 100,设为 0 不分块)。ref_audio: 可选,用于语音克隆。denoise: 开启可添加去噪令牌,提升音质纯净度。
2. OmniVoice Voice Clone TTS (语音克隆)
专注于从参考音频中提取音色特征。
- 输入:
ref_audio: 3-15 秒的清晰人声(必需)。ref_text: 参考音频的文本(留空则自动调用 Whisper 转录)。
- 技巧:参考音频越清晰、情感越符合目标,克隆效果越好。
3. OmniVoice Voice Design TTS (声音设计)
无需参考音频,完全通过文本指令创造声音。
- 输入:
voice_instruct: 逗号分隔的属性描述。- 示例:
"female, young, high pitch, british accent, whisper"(女性,年轻,高音调,英音,耳语)。 - 支持属性:性别、年龄、音调、风格(耳语)、英语口音、汉语方言(四川话、粤语等)。
4. OmniVoice Multi-Speaker TTS (多角色对话)
生成多人对话场景,自动处理角色切换和停顿。
- 文本格式:
[Speaker_1]: 你好,今天天气不错。 [Speaker_2]: 是啊,适合出去走走。 [Speaker_1]: 那我们出发吧! - 动态输入:根据
num_speakers设置,动态显示speaker_1_audio到speaker_N_audio输入端口,可为每个角色单独指定参考音频。 - pause_between_speakers: 控制角色对话间的静音时长(默认 0.3 秒)。
5. OmniVoice Whisper Loader (Whisper 预加载)
用于预加载 Whisper ASR 模型,避免每次生成时重复下载或加载。
- 用法:将其输出连接到其他节点的
whisper_model输入端。 - 模型选择:支持
tiny,small,medium,large-v3,large-v3-turbo(推荐)。
高级参数调优指南
| 参数 | 作用 | 推荐设置 |
|---|---|---|
| steps | 扩散去噪步数 | 32 (平衡); 16 (快速测试); 64 (最高质量) |
| guidance_scale | 文本遵循度 | 2.0 (默认); 过高可能导致声音僵硬 |
| speed | 语速因子 | 1.0 (正常); >1.0 加速; <1.0 减速 |
| position_temperature | 掩码位置随机性 | 5.0 (默认); 0=确定性贪婪解码 |
| class_temperature | Token 采样随机性 | 0.0 (默认); >0 增加声音变化性 |
| attention | 注意力后端 | auto; 若显卡支持 (SM80+) 可选 sage_attention 提速 |
| dtype | 精度 | bf16 (推荐,省显存且质量好); fp32 (最大兼容) |
🚀 SageAttention 加速
如果你的显卡是 NVIDIA Ampere (RTX 30 系列) 或更新架构 (SM80+),安装 sageattention 并在节点中选择 sage_attention 模式,可显著提升推理速度并降低显存占用。
pip install sageattention
常见问题与故障排除
- 模型下载失败 (国内用户):
在启动 ComfyUI 前设置镜像环境变量:export HF_ENDPOINT="https://hf-mirror.com" - 显存不足 (OOM):
- 将
dtype设置为bf16或fp16。 - 开启
keep_model_loaded = False(牺牲速度换空间)。 - 使用
device = cpu(仅作为最后手段,速度较慢)。
- 将
- Whisper 重复下载:
务必使用OmniVoice Whisper Loader节点预加载模型,并连接到主节点的whisper_model输入。 - FFmpeg 错误 (Windows):
确保系统 PATH 中包含 FFmpeg,或在 ComfyUI 启动脚本中配置 PATH 环境变量,或直接输出 WAV 格式避开编码问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
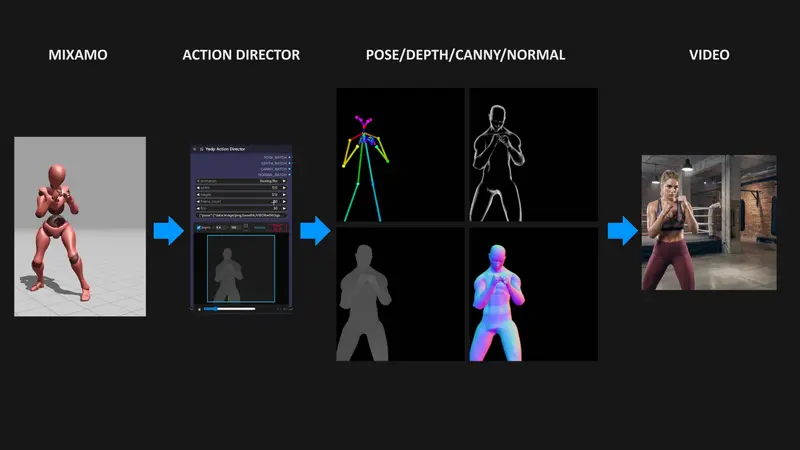
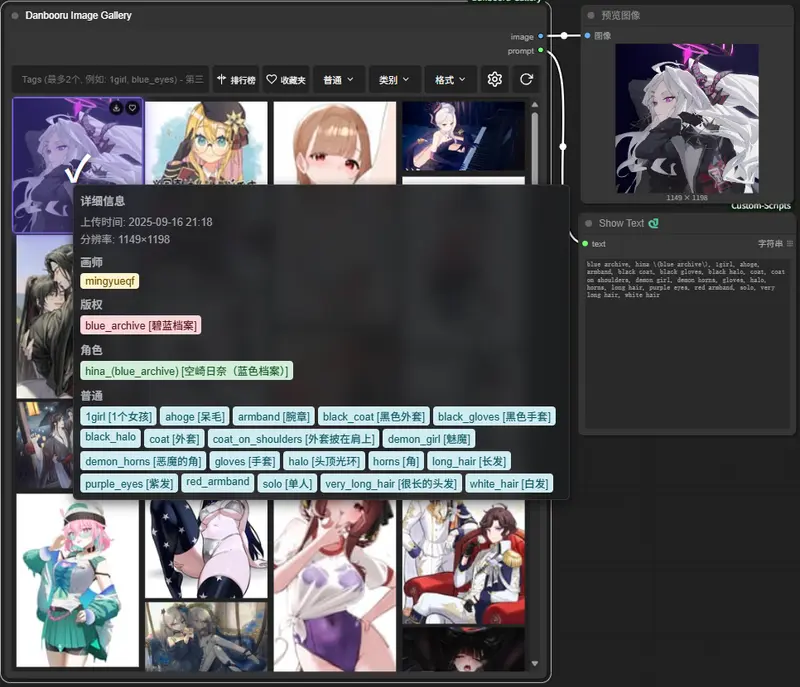

暂无评论...