对于音乐制作人和声音设计师而言,AI 生成音乐往往面临“不可控”的痛点:节奏对不上网格、调性混乱、音色难以精确描述。
- GitHub:https://github.com/Saganaki22/ComfyUI-Foundation-1
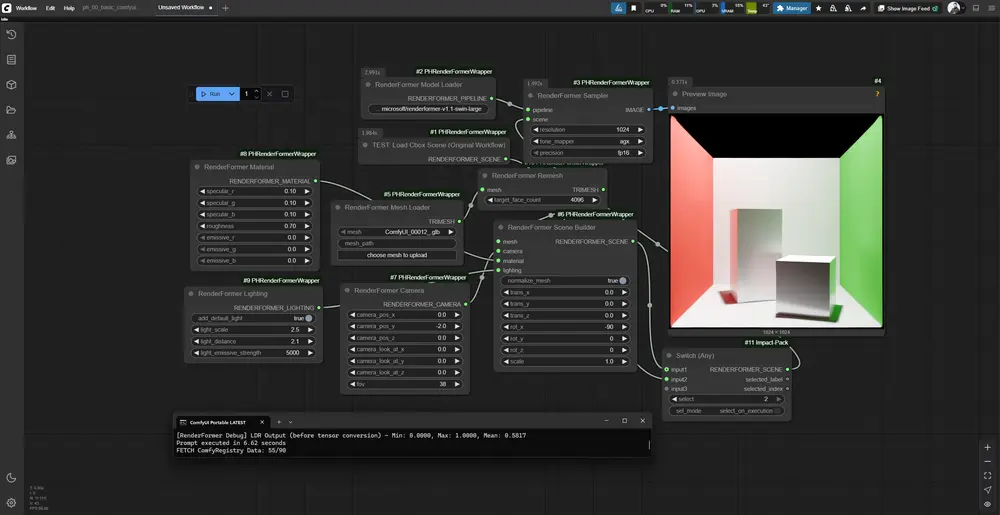
ComfyUI-Foundation-1 是 Foundation-1 模型在 ComfyUI 中的原生封装节点。它将 Foundation-1 强大的结构化文本到采样能力无缝集成到 ComfyUI 的工作流中,让你能够像调整图像生成参数一样,精确控制音乐的 BPM、小节数、调性、乐器配置、音色纹理及效果器链。生成的音频直接以 AUDIO 格式输出,可立即接入 ComfyUI 的其他音频节点进行后续处理、混合或视频合成。
核心亮点:为制作人而生的精准控制
1. 结构化提示词系统
不再依赖模糊的自然语言描述。本节点支持 Foundation-1 独有的分层标签体系:
- 乐器 (Instrument):
Synth Lead,Grand Piano,Acoustic Guitar - 音色 (Timbre):
Warm,Bright,Glassy,Punchy - 效果器 (FX):
Reverb,Delay,Distortion,Bitcrush - 记谱/行为 (Notation):
Arp,Chord Progression,Rolling Bassline - 独立参数控制: BPM, 小节数 (Bars), 调性 (Key) 通过专用下拉菜单控制,确保绝对精准。
2. 节奏与调性完美同步
- 自动时长计算: 根据输入的 BPM 和 小节数 (4 或 8 小节),自动计算并生成严格对齐网格的音频片段,无需后期手动裁剪。
- 全调性支持: 内置 24 种 西方音乐调性(大调/小调),确保生成的旋律和和声始终和谐。
3. 音频变体 (Audio-to-Audio)
支持 图生图 (Img2Img) 式的音乐工作流:
- 输入一段现有的音频(如哼唱的旋律或简单的节奏)。
- 设置
init_noise_level(重绘幅度)。 - 结合新的提示词,让 AI 基于原音频的结构重新演绎,生成风格迥异但节奏一致的变体。
4. 极致性能优化
- 注意力机制自选: 支持
sdpa,flash_attention_2,sageattention,显著提升生成速度。 - 显存管理: 支持生成后自动卸载模型 (
unload_after_generate),节省宝贵显存供其他节点使用。 - 原生进度条: 实时显示扩散生成进度,支持随时中断。
安装指南
方法一:ComfyUI Manager (推荐)
- 打开 ComfyUI Manager。
- 搜索
Foundation-1。 - 点击 Install。
- 重启 ComfyUI。
方法二:手动安装
cd ComfyUI/custom_nodes
git clone https://github.com/saganaki22/ComfyUI-Foundation-1.git
cd ComfyUI-Foundation-1
python install.py
提示: 推荐安装
sageattention以获得最佳速度:pip install sageattention
快速开始:构建你的第一个音乐工作流
1. 加载模型
添加 Foundation-1 Model Loader 节点:
- model: 选择
Foundation-1(首次运行会自动从 HuggingFace 下载约 3GB 权重)。 - attention: 选择
auto或手动指定sageattention(若已安装)。
2. 生成音乐
添加 Foundation-1 Generate 节点并连接模型:
- tags: 输入结构化标签,例如:
Synth Lead, Warm, Wide, Bright, Arp, Reverb- (注意:不要在 tags 中写 BPM 或调性,使用下方独立参数)
- bpm: 选择
128(或其他 100-150 之间的值)。 - bars: 选择
8 Bars(生成 8 小节循环)。 - key: 选择
C Minor(或其他调性)。 - steps:
250(高质量) 或100(快速预览)。 - cfg_scale:
7.0。 - seed: 固定种子以复现结果,或随机探索。
3. 输出与后续
- 节点输出
audio信号。 - 连接
Save Audio节点保存 WAV 文件。 - 或者连接
VHS_VideoCombine节点,直接将生成的音乐配乐到视频中!
高级玩法:音频变体工作流
想要 remix 一段现有的鼓点或旋律?
- 使用
Load Audio节点加载本地音频文件。 - 将其连接到
Foundation-1 Generate节点的audio输入端。 - 调整
init_noise_level:0.3 - 0.5: 保留大部分原曲结构,仅改变音色。0.6 - 0.8: 大幅重构,保留节奏骨架但改变旋律和配器。> 0.9: 几乎完全重新生成,仅参考原曲氛围。
- 修改
tags为你想要的新风格(如从Piano改为Synth Wave),点击生成即可得到完美卡点的 Remix 版本。
系统要求与注意事项
- GPU: 必须为 NVIDIA GPU (CUDA 11.8+),最低 8GB 显存。
- 不支持 CPU 或 Apple MPS (Mac),因为模型强依赖 Flash Attention。
- 显存占用: 生成时约 7GB。若显存紧张,请勾选
unload_after_generate。 - 首次运行: 需要联网下载 T5 编码器 (
900MB) 和模型权重 (3GB)。后续可离线使用。 - 时长限制: 单次生成最大支持 20 秒 (通常为 8 小节 @ 100 BPM)。
许可证说明
本项目遵循 Stability AI Community License:
- ✅ 个人/非商业用途: 完全免费。
- ✅ 小型商业实体: 年收入 < $100 万美元,可免费用于商业项目。
- ⚠️ 大型商业实体: 年收入 > $100 万美元,需联系获取商业授权。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





