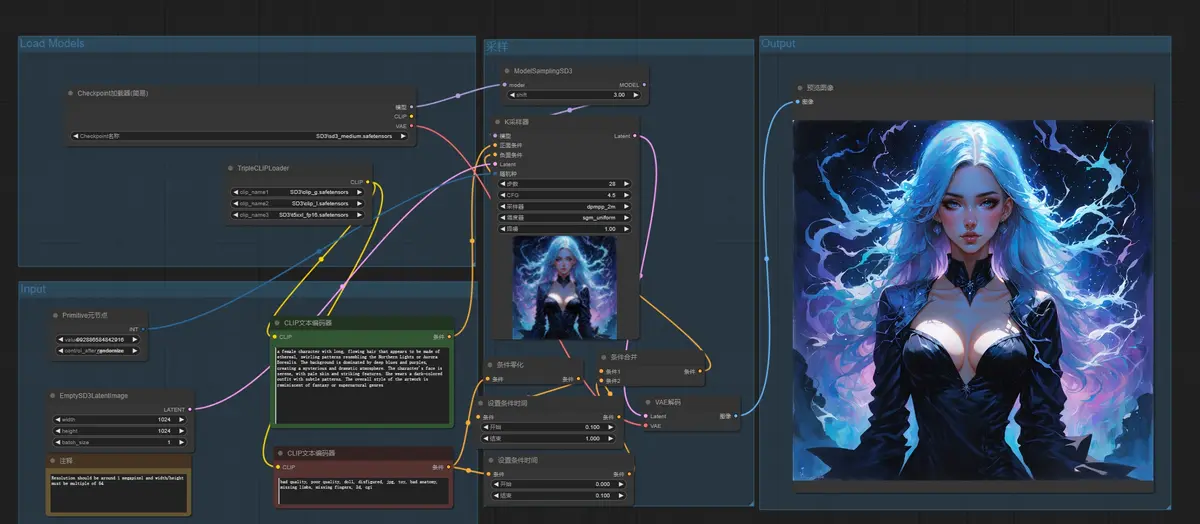
Stability AI释出Stable Diffusion 3 Medium模型,8G显存显卡即可使用Stability AI终于在6月12日释出了万众期待的Stable Diffusion 3模型,不过此次释出的仅是 20 亿个参数的Stable Diffusion 3 Medium 模型,该型号尺...图像模型# SD3模型# Stability AI# Stable Diffusion 3 Medium1年前05,0910
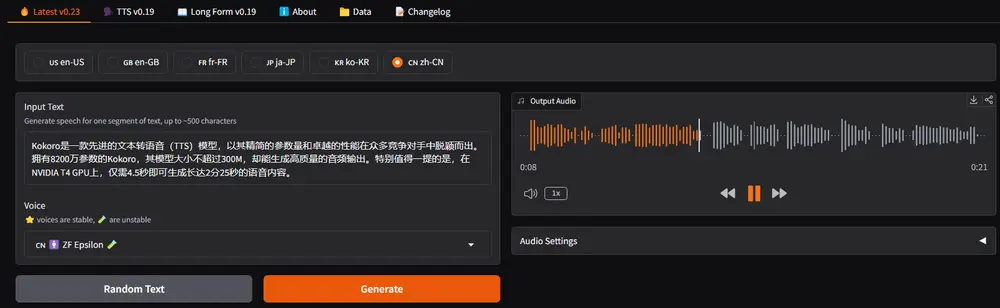
文本转语音模型Kokoro-82M:8200万参数,支持多语言和多声音选项Kokoro是一款先进的文本转语音(TTS)模型,以其精简的参数量和卓越的性能在众多竞争对手中脱颖而出。拥有8200万参数的Kokoro,其模型大小不超过300M,却能生成高质量的音频输出。特别值得一...语音模型# Kokoro-82M# TTS1年前03,5340
Illustrious XL v2.0正式发布,支持1024x1536原生分辨率生成在开源AI绘画模型领域,Flux模型是众多衍生开发的基础。然而,在二次元领域,尤其是日式风格方面,情况有所不同。目前,大量用户依然以SDXL模型为基础进行衍生开发。在开源社区中,Pony、Illust...图像模型# Illustrious XL v2.0# SDXL# 二次元1年前02,6860
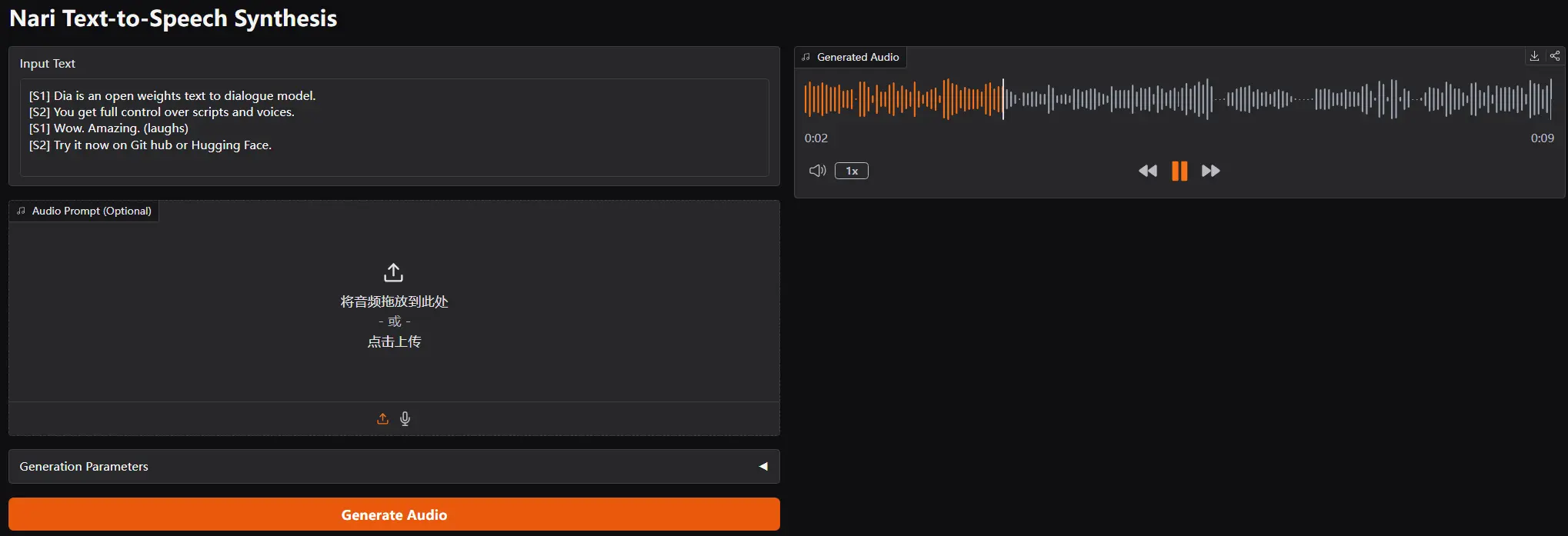
Nari Labs开源TTS模型Dia-1.6B:生成自然对话与非语言表达,支持声音克隆Nari Labs在今天开源了一个拥有16亿参数的文本转语音模型Dia-1.6B。这个模型的最大亮点在于它能够生成高度逼真的对话,并且加入了自然人声元素,比如笑声、咳嗽、清喉咙等,让语音合成更加生动自...语音模型# Dia-1.6B# Nari Labs# TTS模型11个月前02,2400
AWPortraitCN:专门针对中国人长相特征及审美进行了优化的FLUX LoRA模型AWPortraitCN 是由 DynamicWang 基于FLUX.1-dev模型开发的一款LoRA模型,专门针对中国人长相特征及审美进行了优化。该模型使用了包含室内、室外人像、时尚、棚拍写真等多类...Flux衍生# AWPortraitCN# LoRA模型1年前01,4530
FLUX.1-dev-ControlNet-Union-Pro-2.0:Shakker Labs发布的新一代ControlNet,功能升级,性能优化!Shakker Labs近期发布了FLUX.1-dev-ControlNet-Union-Pro-2.0,这是FLUX.1-dev模型的升级版统一ControlNet。该版本在功能和性能上都进行了显著...Flux衍生# controlnet# FLUX.1-dev-ControlNet-Union-Pro-2.0# Shakker Labs11个月前01,3810
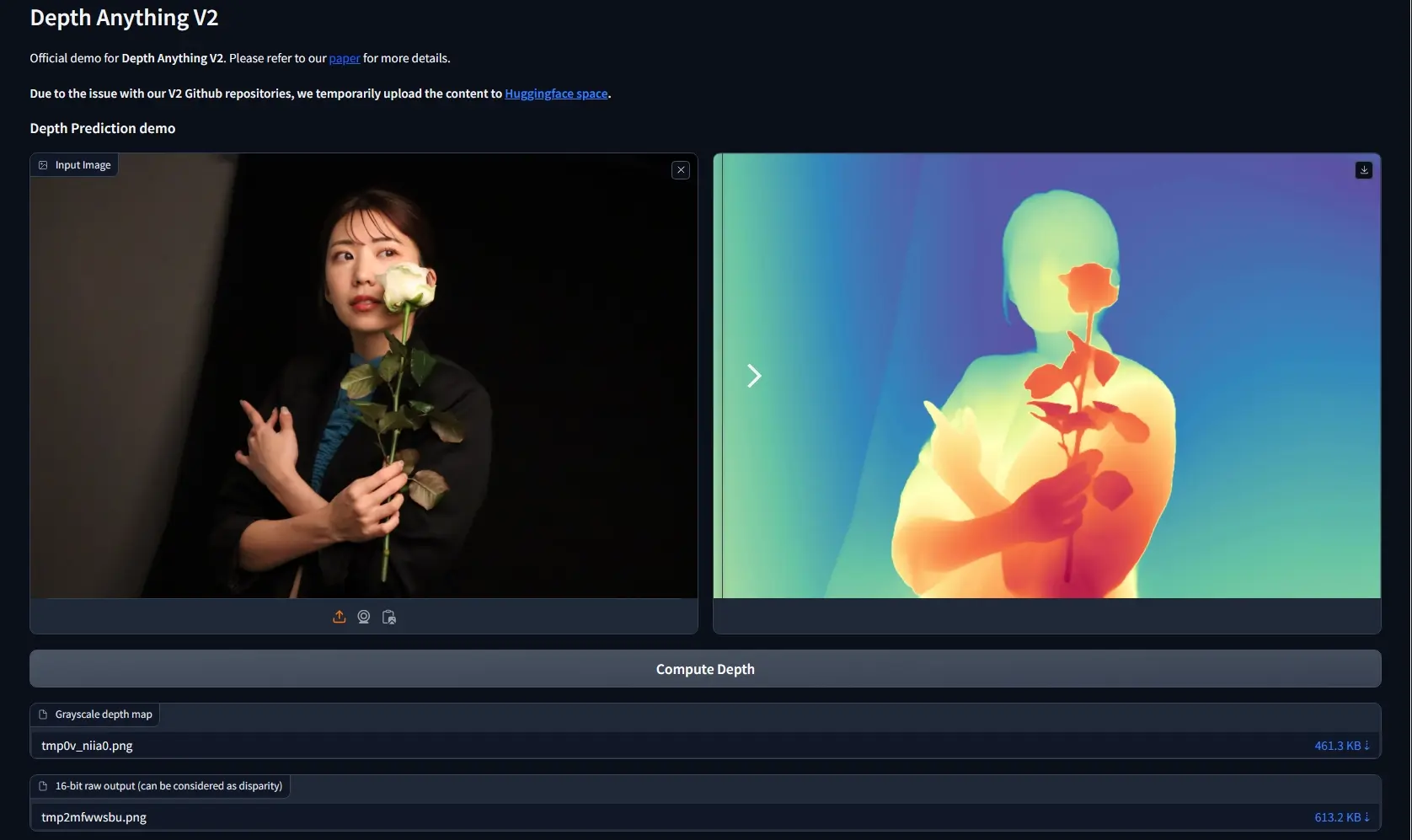
单目深度估算模型Depth Anything V2:通过分析单张图片来预测物体距离来自香港大学和TikTok的研究人员推出单目深度估算模型Depth Anything的升级版Depth Anything V2,让计算机通过分析单张图片来预测物体距离的技术,这在自动驾驶、3D建模和虚...图像模型# Depth Anything V2# 单目深度估算模型1年前01,2560
高级插图模型Illustrious:专门针对插画和动画任务进行了优化,主要用于生成动漫风格的图像OnomaAI 研究小组推出一个高级插图模型Illustrious,它主要用于生成动漫风格的图像。Illustrious XL是一个基于SDXL的模型,专门针对插画和动画任务进行了优化。它是基于 Ko...图像模型# Illustrious# Illustrious XL# 插图模型1年前01,2400
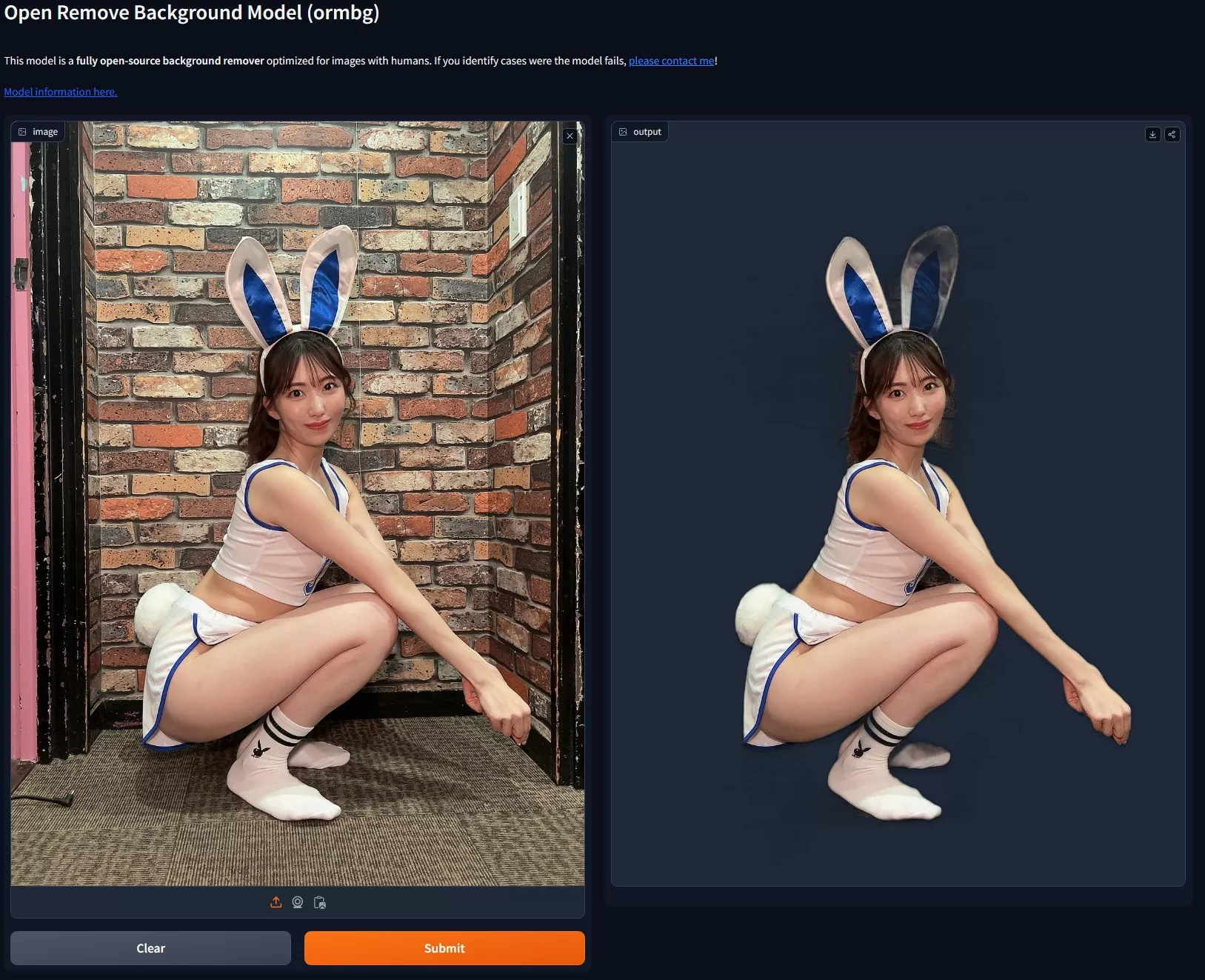
全新开源背景移除模型ormbg:专门针对含有人物的图像进行了优化ormbg是一个基于基于高度准确的二分类图像分割(DIS)的全新开源背景移除模型,它专门针对含有人物的图像进行了优化,此模型类似于 RMBG-1.4,但提供了开放的训练数据和流程,且商业使用免费。它提...图像模型# DIS# ormbg# 背景移除模型1年前01,2090
字节跳动推出新型蒸馏模型Hyper-SD:基于SD1.5和SDXL1.0基础模型提炼字节跳动在推出文生图模型SDXL-Lightning后,又推出了新的蒸馏模型Hyper-SD,它有效地结合了ODE轨迹保留和重构的优点,同时在步骤压缩过程中保持了接近无损的性能。与SDXL-Light...图像模型# Hyper-SD# 字节跳动# 蒸馏模型1年前01,1920
图像编辑框架ByteEdit:提升基于扩散模型的生成性图像编辑任务的性能字节跳动推出图像编辑框架ByteEdit,这是一个精心设计的创新反馈学习框架,旨在增强生成图像编辑任务的效果、提升遵从度,并加速处理速度。它专门用于提升基于扩散模型的生成性图像编辑任务的性能。Byte...图像模型# ByteEdit# 图像编辑框架1年前01,1620
虚拟服装试穿Magic Clothing:根据特定的服装和文本提示来生成穿着这些服装的定制化角色图像小i研究院发布了OOTDiffusion的分支版本Magic Clothing,它能够根据特定的服装和文本提示来生成穿着这些服装的定制化角色图像。这项技术的核心在于高度的图像可控性,即在生成的图像中保...图像模型# Magic Clothing# 虚拟服装试穿1年前01,1580