智谱 AI 开源视频生成模型 CogVideoX-5B ,RTX 3060 显卡可运行之前已经给大家分享了《智谱AI推出视频生成模型CogVideoX:与“清影”同源,单张 4090 显卡可推理》,之前推出的是CogVideoX-2B模型,智谱 AI又开源了CogVideoX-5B,相...视频模型# CogVideoX-5B# 智谱 AI1年前01,1510
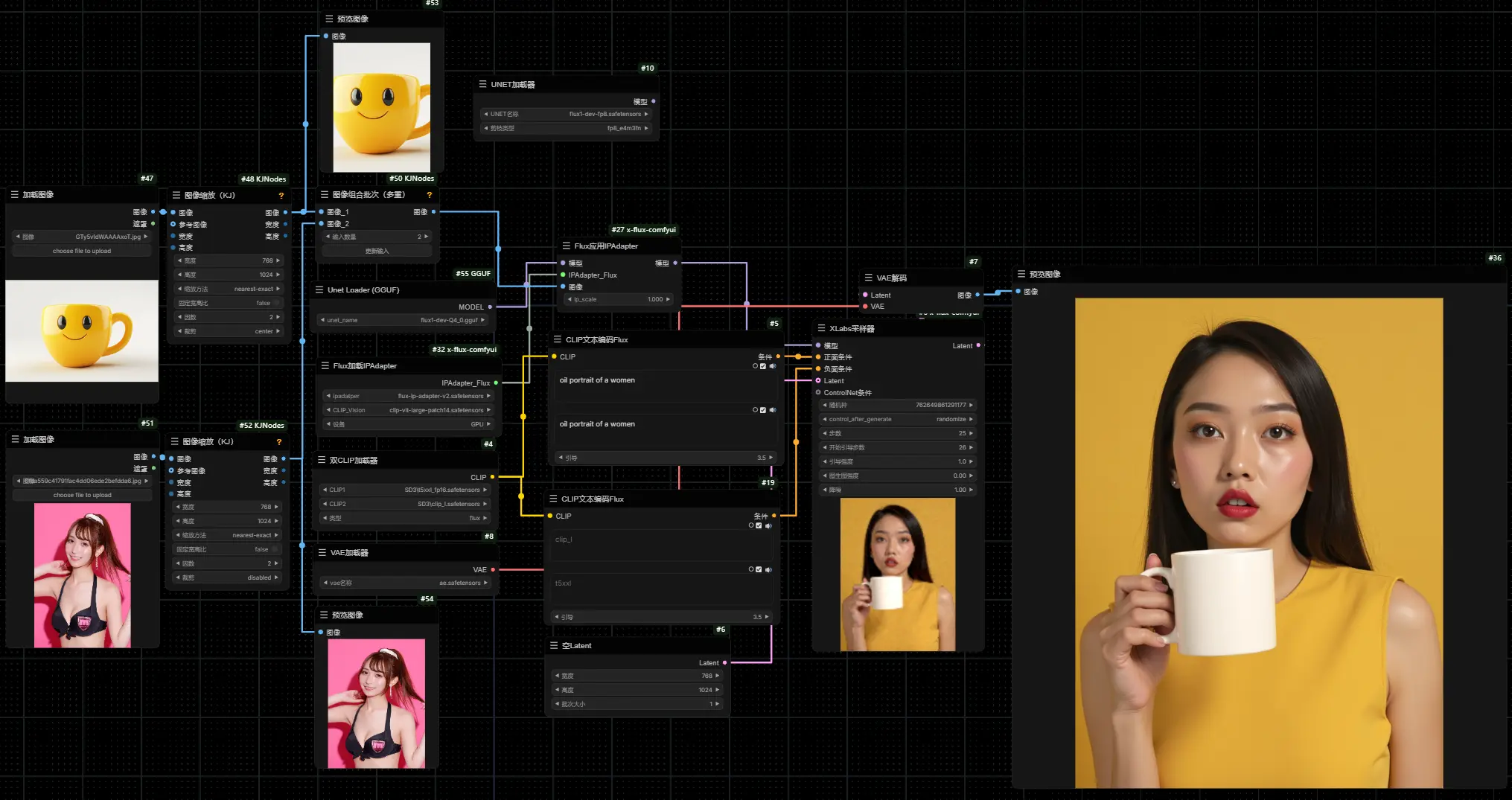
flux-ip-adapter-v2:基于FLUX.1-dev的风格迁移IP-Adapter 模型XLabs-AI推出了很多基于FLUX.1-dev 模型的ControlNet模型,近期XLabs-AI又推出了基于FLUX.1-dev的IP-Adapter 模型,支持支持 512 和 1024 分...Flux衍生插件# flux-ip-adapter-v2# FLUX.1-dev 模型# IP-Adapter 模型1年前01,1500
Chroma 模型家族正式发布:基于 FLUX.1-schnell,8.9亿参数开源无限制,4大分支适配不同需求开发者 lodestones 近期宣布,基于 FLUX.1-schnell 构建的 8.9 亿参数生成模型 Chroma 已完成全部基础训练,正式开放供开发者与研究者使用。作为完全遵循 Apache ...图像模型# Chroma# FLUX.1 [schnell]7个月前01,1490
新型文生图模型CoMat:更好地理解和执行文本描述,提高了文本到图像生成的质量和准确性来自香港中文大学、商汤科技和上海人工智能实验室的研究人员推出新型文生图模型CoMat,这是一种具有图像到文本概念匹配机制的端到端扩散模型微调策略。开发团队借助图像字幕模型来评估图像与文本的对齐程度,并...图像模型# CoMat# 文生图模型1年前01,1340
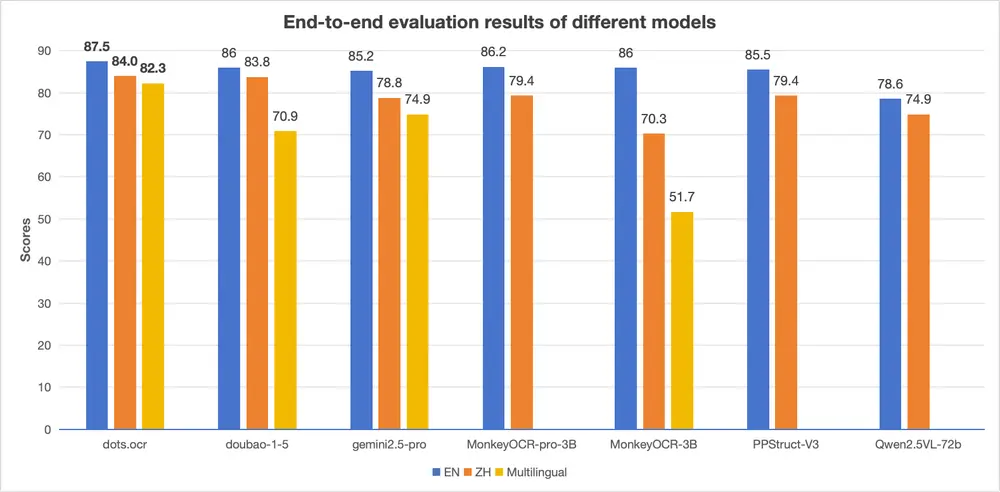
小红书 hi lab 推出 dots.ocr:一个更高效、更统一的文档解析方案小红书 hi lab 团队近期发布了一款名为 dots.ocr 的多语言文档解析模型。它不是传统OCR工具的简单升级,而是一次架构层面的重构——将布局检测与内容识别统一在一个视觉-语言模型(VLM)中...多模态模型# dots.ocr# 小红书7个月前01,1220
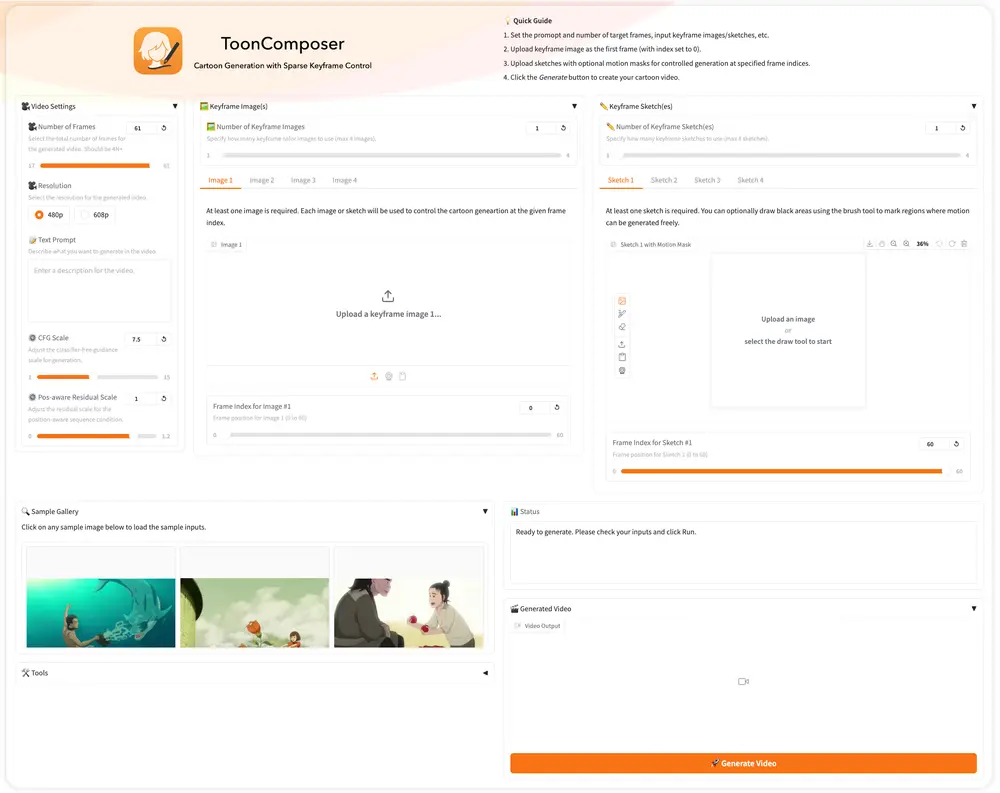
ToonComposer:通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程香港中文大学、腾讯PCG ARC Lab和北京大学的研究人员推出 ToonComposer ,通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程。传统的卡通和动画制作涉及关键帧绘...视频模型# ToonComposer# 卡通制作7个月前01,1160
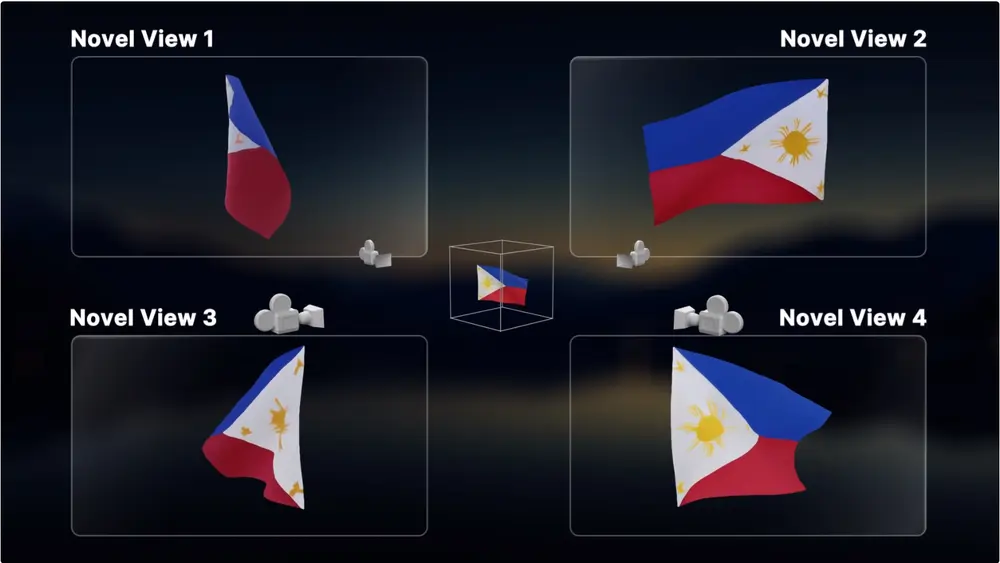
StabilityAI推出全新视频生成模型Stable Video 4D(SV4D):可将单个视频转化为 8 个不同角度/视图的新视图视频StabilityAI在今天推出一个新的视频生成模型Stable Video 4D(SV4D),只需 40 秒就可将单个视频转化为 8 个不同角度/视图的新视图视频(5 帧/个视角),整个 4D 优化...视频模型# StabilityAI# Stable Video 4D# SV4D1年前01,1070
CosmicMan:专注于生成高保真人类图像的文生图基础模型上海人工智能实验室推出CosmicMan,这是一款专注于生成高保真人类图像的文本到图像基础模型。CosmicMan能够生成外观精细、结构合理,并且与详细描述精确对齐的逼真人类图像。 项目主页:http...图像模型# CosmicMan# 文生图模型1年前01,0960
阿里 WAN 项目组正式推出 Wan2.2:MoE 架构 + 高压缩设计,开源视频生成再进化阿里 WAN 项目组正式推出 Wan2.2,这是对 WAN 系列视频生成模型的一次重大升级。本次发布涵盖多个模型变体,全面支持文本到视频(T2V)、图像到视频(I2V)以及混合输入(TI2V)任务,在...视频模型# Wan2.2# 视频生成模型8个月前01,0870
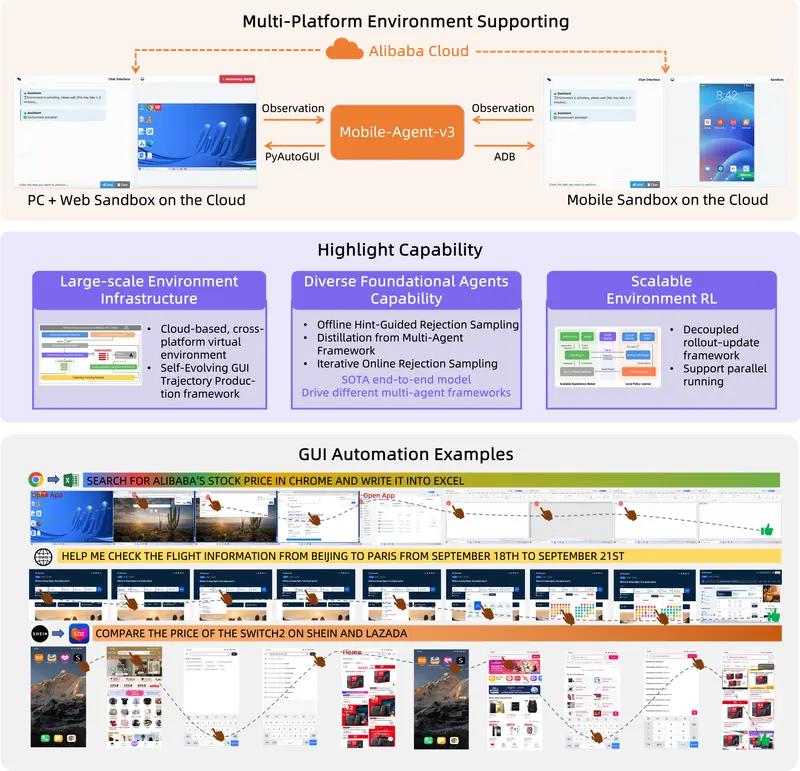
阿里通义实验室推出 Mobile-Agent-v3 框架:为图形用户界面(GUI)任务的自动化带来了全新的解决方案在当今数字化时代,自动化技术的发展日新月异。阿里通义实验室作为行业内的创新先锋,于近期推出了令人瞩目的Mobile-Agent-v3框架,为图形用户界面(GUI)任务的自动化带来了全新的解决方案。 G...多模态模型# Mobile-Agent-v3# 图形用户界面# 通义实验室7个月前01,0850
Neta Lumina 发布:专为二次元创作打造的高品质图像生成模型由捏Ta实验室(Neta.art)训练的 Neta Lumina 是一款专注于二次元风格的高质量图像生成模型。此模型基于上海人工智能实验室 Alpha-VLLM 团队开源的 Lumina-Image...图像模型# Neta Lumina# 二次元9个月前01,0590
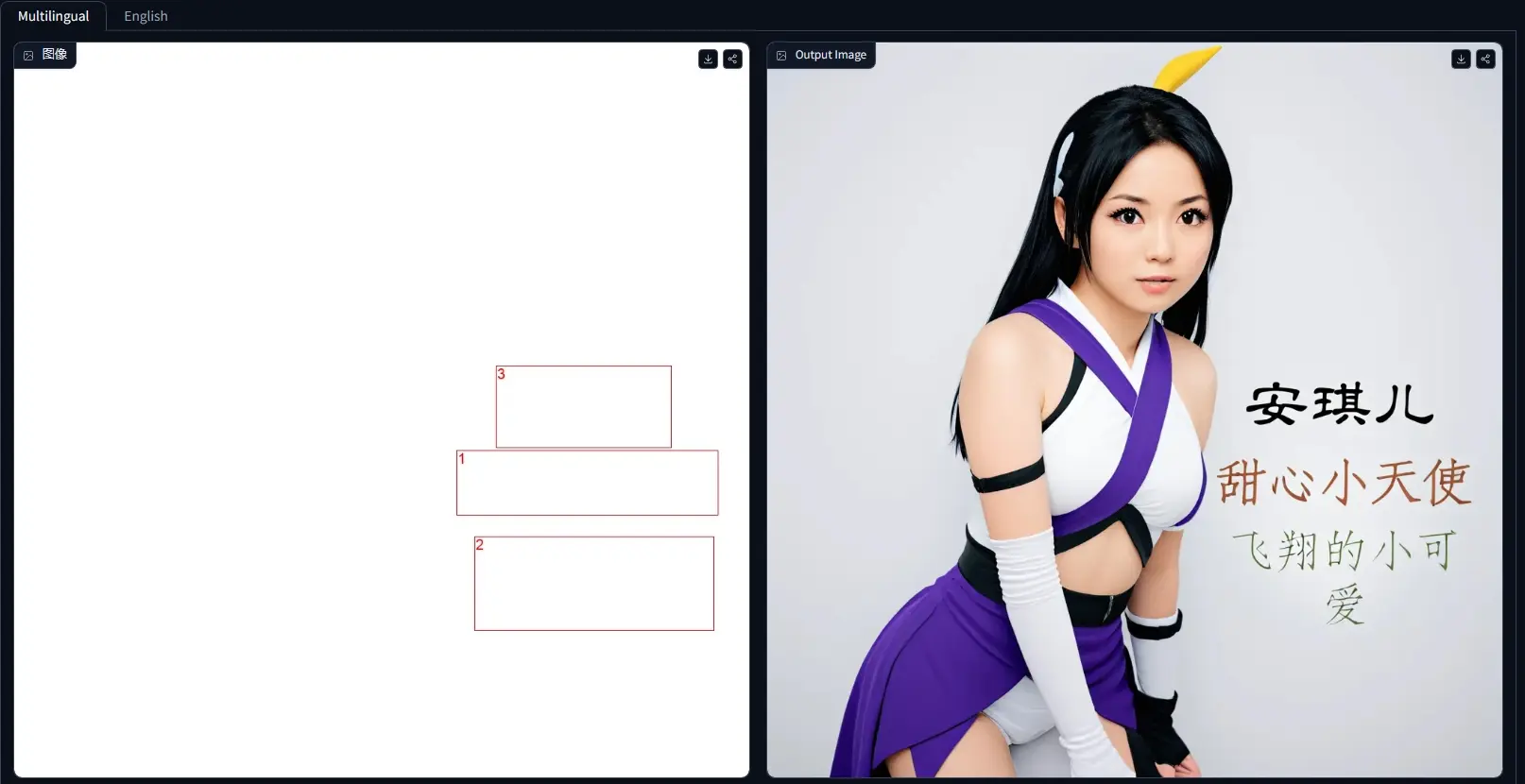
多语言文本编码器Glyph-ByT5-v2:提高在图形设计图像中渲染多种语言文本的准确性和美观度来自微软亚洲研究院、清华大学、北京大学和利物浦大学的研究人员推出新型多语言视觉文本渲染技术Glyph-ByT5-v2,这是之前介绍的Glyph-ByT5升级版,此技术的目标是提高在图形设计图像中渲染多...大语言模型# Glyph-ByT5-v2# Glyph-SDXL-v2# 文本编码器1年前01,0570