SDXL系列新模型SDXL Flash:高速且保证质量的SDXL模型Stable Diffusion Community是一个非官方、非盈利性质的组织,它们主要目标是尽可能改进 SD 模型并让每个人都可以使用它们,近期它们推出了新的SDXL系列模型SDXL Flash...图像模型# SDXL Flash# sdxl-flash-mini# 高速模型1年前01,0490
Stable Diffusion 1.5Stable Diffusion 1.5 是由 Runway ML 开发,基于 Stable Diffusion 1.2 版本,于2022年10月发布,并进行了以下改进: 使用了更大的模型:Stabl...图像模型# Runway ML# Stable Diffusion 1.5# 模型1年前01,0420
华为PixArt系列最新模型—PIXART-Σ:基于DiT,可直接生成4K分辨率的图像来自华为诺亚方舟实验室、大连理工大学、香港大学的研究人员推出了最新的PixArt模型—PIXART-Σ,PixArt-Σ基于Diffusion Transformer架构 (DiT,与Sora、Sta...图像模型# DiT# PIXART-Σ# 文生图模型1年前01,0380
PixelWave Flux.1-Dev:基于FLUX.1-dev的微调FLUX模型,适合艺术和摄影风格PixelWave Flux.1-Dev是一个基于FLUX.1-dev的微调FLUX模型,非常适合艺术和摄影风格,黑色和深色图像输出更可靠,手部问题更少。目前已经推出了第三版,开发者推出了多个版本(S...Flux衍生# FLUX.1-dev# PixelWave Flux.1-Dev1年前01,0330
别让好模型消失,这个 WAN2.1 LoRA 合集值得收藏”近日,CivitAI 在 Visa 和 Mastercard 的压力下进一步收紧内容政策,导致平台上大量 模型被删除。这些模型中包含了许多创作者精心训练的作品,尤其是 NSFW类内容。 地址:http...视频模型# WAN2.1 LoRA10个月前01,0310
卷积重建模型CRM:将一张普通的2D图片转换成一个带有纹理的3D模型清华大学、中国人民大学等团队研究人员推出卷积重建模型CRM。该模型可用于将单图像转换为3D纹理网格,可在短短10秒内就从图像中提供了高保真纹理网格,无需任何优化测试。 项目主页 GitHub Demo...3D模型# 3D模型# CRM# 重建模型1年前01,0110
文生图模型新架构MoA:根据用户的个性化需求生成包含特定人物的图像,同时保持原有模型的风格和多样性Snap推出新架构注意力混合(Mixture-of-Attention,简称MoA),即在个性化图像生成中实现主体与上下文解耦的注意力混合模型(MoA),用于个性化文本到图像的扩散模型。简单来说,Mo...图像模型# MoA# 文生图模型1年前09950
图像修复模型BrushNet:使用分解的双分支扩散方法来进行图像内容的恢复和编辑来自腾讯PCG ARC实验室和香港中文大学的研究团队推出新型图像修复(inpainting)模型BrushNet,它使用了分解的双分支扩散(diffusion)方法来进行图像内容的恢复和编辑。图像修复...图像模型# BrushNet# 图像修复1年前09860
基于 FLUX.1-schnell的开源、无审查的生成模型ChromaChroma 是一个基于 FLUX.1-schnell 的 8.9 亿参数生成模型,完全采用 Apache 2.0 许可证,为开发者和研究者提供一个自由、开放、无审查的工具。无论是用于艺术创作、科学研...Flux衍生# Chroma# FLUX.1 [schnell]10个月前09840
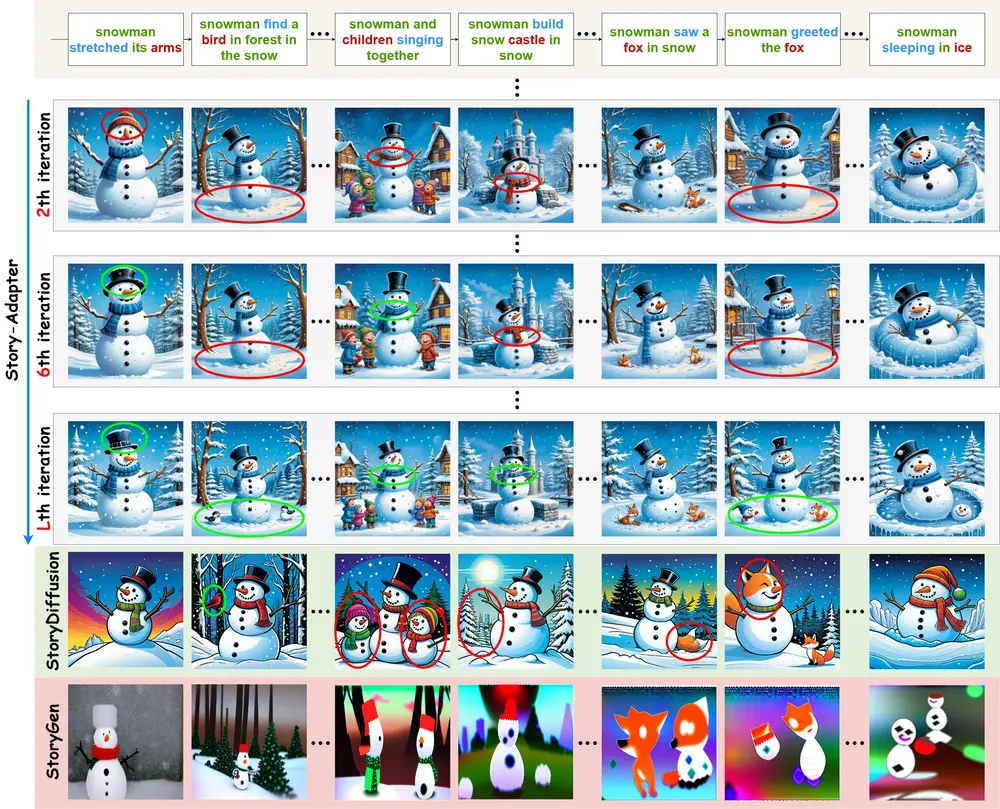
用于长篇故事视觉化的迭代框架Story-Adapter:根据长篇故事的文字描述生成一系列既连贯又具有丰富细节的图像加州大学圣克鲁斯分校、杭州电子科技大学和新加坡理工学院的研究人员推出一个用于长篇故事视觉化的迭代框架Story-Adapter,Story-Adapter能够根据长篇故事的文字描述生成一系列既连贯又具...图像模型# Story-Adapter# 长篇故事视觉化1年前09720
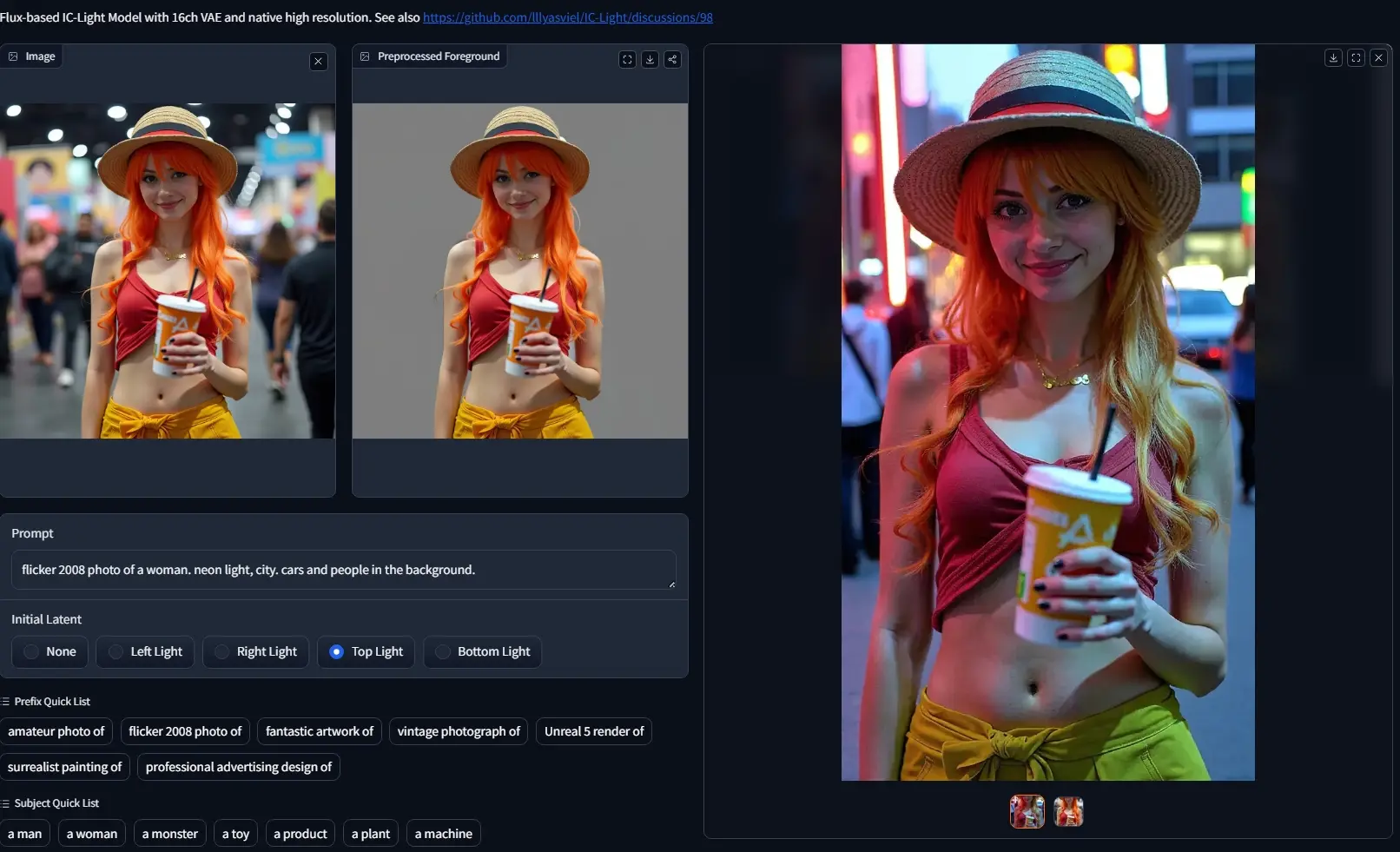
IC-Light推出基于Flux模型的新版本IC-Light V2:为图像进行重新打光IC-Light是Controlnet、Fooocus、Stable Diffusion WebUI Forge的开发者lllyasviel推出的一款控制图像照明效果的模型,之前是基于SD1.5,目前...Flux衍生# FLUX模型# IC-Light V21年前09620
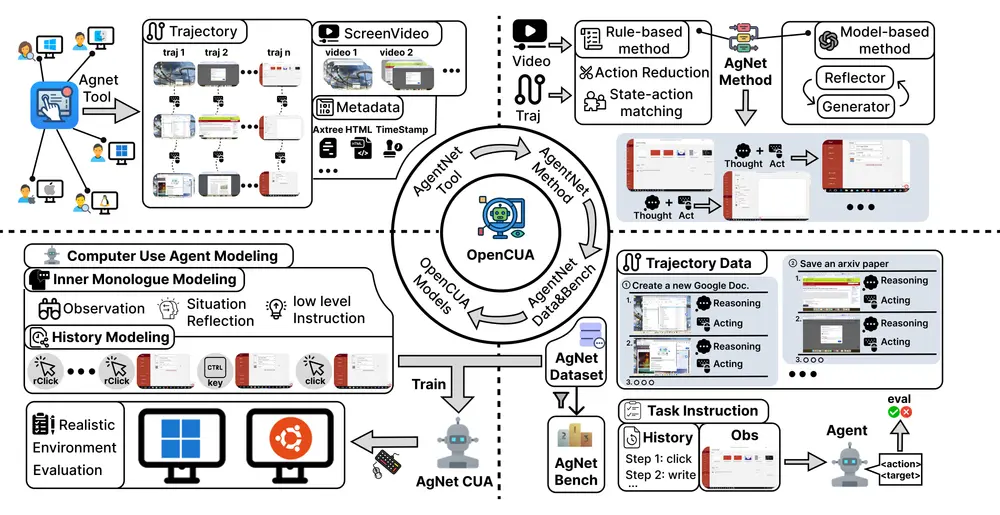
OpenCUA:首个开源的计算机使用智能体框架发布你是否曾希望有一个 AI 助手,能像你一样操作电脑——打开浏览器查资料、在 Excel 中整理数据、切换应用完成多步骤任务?如今,这类被称为“计算机使用智能体”(Computer Use Agents...多模态模型# OpenCUA# 智能体框架7个月前09500