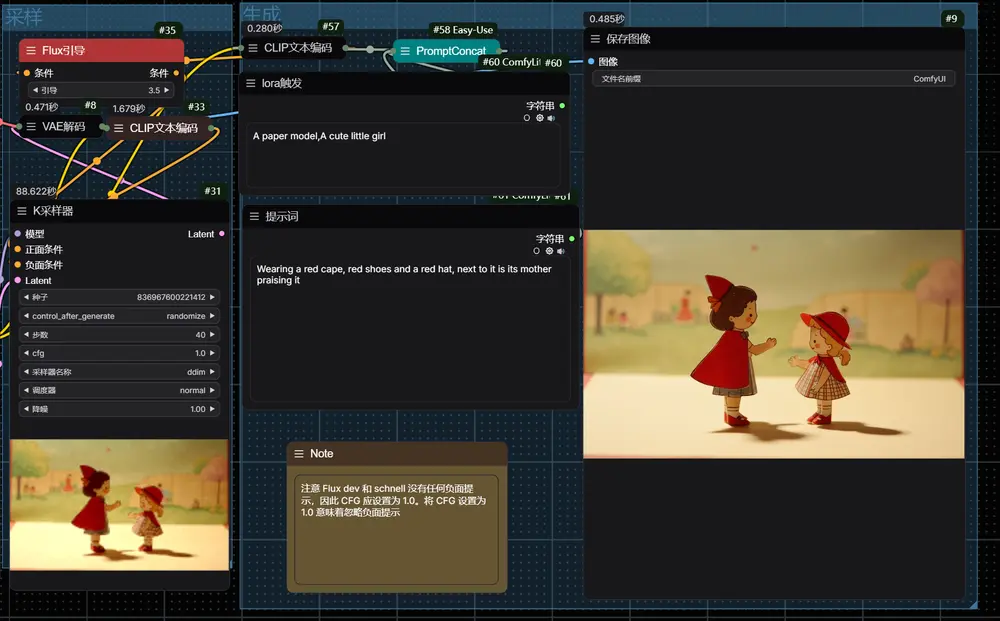
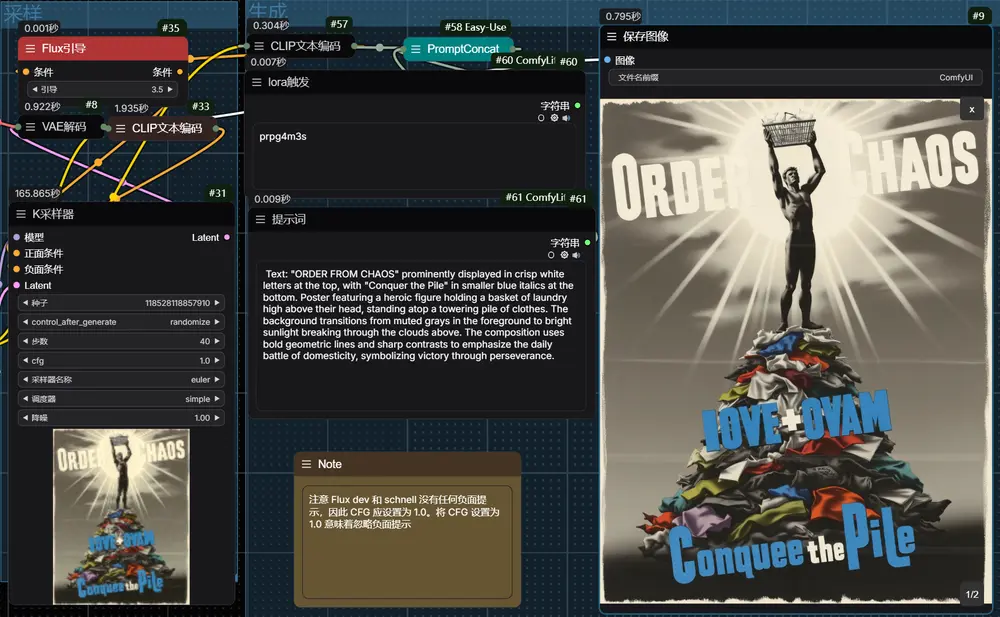
Chroma 是一个基于 FLUX.1-schnell 的 8.9 亿参数生成模型,完全采用 Apache 2.0 许可证,为开发者和研究者提供一个自由、开放、无审查的工具。无论是用于艺术创作、科学研究还是其他领域,任何人都可以自由使用、修改和扩展这一模型。目前,该模型仍在训练中,开发团队欢迎社区的反馈与建议,以进一步优化其性能。

Chroma 的目标
Chroma 的设计初衷是为用户提供一个可靠的开源选项,支持多样化的生成任务,同时保持完全无审查的理念。以下是 Chroma 的主要目标:
- 大规模多样化数据集训练
- 在 500 万个数据集上进行训练,从 2000 万个样本中精心挑选,涵盖动漫、furry、艺术作品和照片等多种内容类型。
- 数据集的多样性确保了模型能够生成高质量、多风格的内容,满足不同用户的需求。
- 完全无审查
- Chroma 重新引入了许多被现有模型限制或删除的解剖概念,确保生成内容的真实性和完整性。
- 这一特性使其成为需要高度自由表达场景的理想选择。
- 社区驱动的支持
- Chroma 致力于为开源社区提供支持,任何开发者都可以在其基础上构建自己的项目,而无需担心企业限制。

如何运行 Chroma 模型
要求
要运行 Chroma 模型,您需要以下组件:
- ComfyUI 安装:确保已正确安装 ComfyUI。
- Chroma 检查点:从官方仓库下载最新版本的 Chroma 模型。
- T5 XXL 或 T5 XXL fp8:两者均可使用。
- FLUX VAE:用于处理生成模型中的变分自编码器部分。
- Chroma_Workflow:包含运行 Chroma 所需的工作流程配置。
手动安装(Chroma)
- 导航到 ComfyUI 的
ComfyUI/custom_nodes文件夹。 - 克隆 Chroma 的仓库:git clone https://github.com/lodestone-rock/ComfyUI_FluxMod.git
- 重启 ComfyUI。如果 ComfyUI 已在运行,请刷新浏览器。
运行模型的方法
- 将
T5_xxl放入ComfyUI/models/clip文件夹。 - 将
FLUX VAE放入ComfyUI/models/vae文件夹。 - 将 Chroma 检查点放入
ComfyUI/models/diffusion_models文件夹。 - 在 ComfyUI 中加载 Chroma 工作流程。
- 运行工作流程并观察生成结果。
架构修改与优化
为了提升模型的性能和训练效率,Chroma 团队对原始 FLUX 架构进行了多项关键性修改:
12B → 8.9B 参数裁剪
- 问题背景:原始 FLUX 模型中有 33 亿个参数仅用于编码单个输入向量,这种资源分配显得过于冗余。
- 解决方案:团队将这部分替换为一个简单的前馈神经网络(FFN),仅使用 2.5 亿个参数完成相同任务。
- 效果:通过这一裁剪,模型规模从 120 亿参数缩减至 89 亿,同时保持了知识损失最小化。整个裁剪过程在单台 3090 GPU 上仅用了一天时间。
MMDiT 掩码
- 问题背景:在预训练过程中,模型对填充令牌(如
<pad>)的关注度远高于实际提示信息,导致生成内容模糊或混乱。 - 解决方案:通过掩码技术屏蔽多余的填充令牌,仅保留一个填充令牌参与训练,从而让模型专注于实际提示信息。
- 效果:修复后,模型生成的图像保真度显著提升,训练稳定性也得到了增强。
时间步分布优化
- 问题背景:传统扩散模型通常使用“lognorm”分布随机采样时间步,但这种方法容易忽略高噪声和低噪声区域(尾部),导致训练过程中出现损失尖峰。
- 解决方案:团队引入了自定义时间步分布函数(如
-x^2),更频繁地采样尾部时间步,确保覆盖所有关键区域。 - 效果:新分布使模型在训练初期和后期都能更好地应对极端噪声情况,避免了训练失控的问题。
小批量最优传输
- 数学优化:通过改进配对策略减少“路径歧义”,加速向量场的学习过程。
- 效果:这一优化显著提升了训练效率,并提高了生成结果的质量。
为什么选择 Chroma?
- 完全开源:Chroma 使用 Apache 2.0 许可证,允许任何人自由使用、修改和扩展,没有任何企业限制。
- 无审查理念:与其他模型相比,Chroma 提供了一个更加开放的环境,重新引入了缺失的解剖概念,适合需要高度自由表达的应用场景。
- 高性能与灵活性:凭借架构优化和训练方法改进,Chroma 在保持较低参数规模的同时,依然能够生成高质量的多样化内容。
- 社区驱动:开发团队高度重视用户反馈,并鼓励社区成员参与模型的改进和扩展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
![LibreFLUX:基于FLUX.1 [schnell]的免费、开源、去蒸馏FLUX 模型](https://pic.sd114.wiki/wp-content/uploads/2024/10/1729674970-LibreFLUX.webp~tplv-o4t1hxlaqv-image.image)

暂无评论...











