新智谱 AI 重磅发布 GLM-5-Turbo:专为 OpenClaw“龙虾”打造的极速智能体引擎在 AI 智能体(Agent)从“对话”走向“执行”的关键时刻,智谱 AI 正式推出了 GLM-5-Turbo —— 一款专为 OpenClaw(俗称“龙虾”)场景深度优化的基座模型。 国内版: 文档...多模态模型早报# GLM-5-Turbo# 智谱 AI23小时前0790
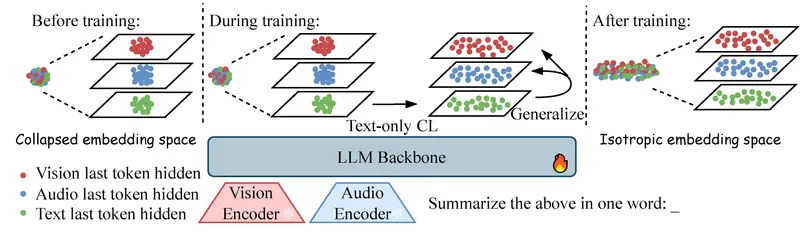
新LCO-EMB:阿里达摩院新突破,用“纯文字”训练出全能多模态AI想象一下,你只需要教 AI 读书(文字),它就能无师自通地看懂图片、听懂音频、理解视频。这听起来像魔法,但阿里达摩院最新推出的 LCO-EMB(Language-Centric Omnimodal E...多模态模型# LCO-EMB23小时前030
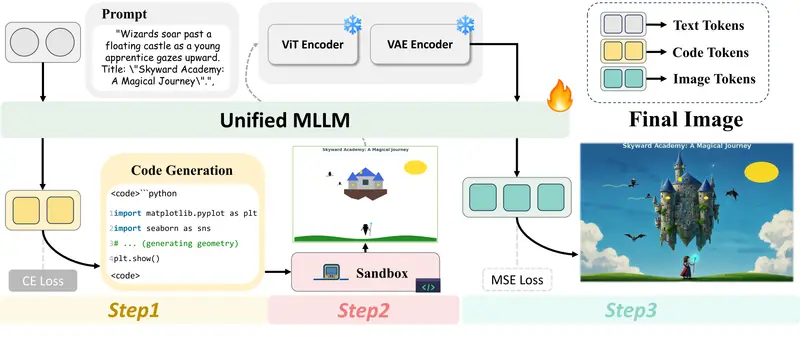
新CoCo:让 AI 像程序员一样“写代码画图”,彻底解决文生图的文字与布局难题如果你曾让 AI 画一张“带有具体数据的饼图”、“排版精美的餐厅菜单”或“标注了坐标轴的数学函数图”,结果大概率会失望:文字变成乱码、布局歪七扭八、数据完全错误。 这是因为现有的文生图模型依赖模糊的自...多模态模型# CoCo1天前050
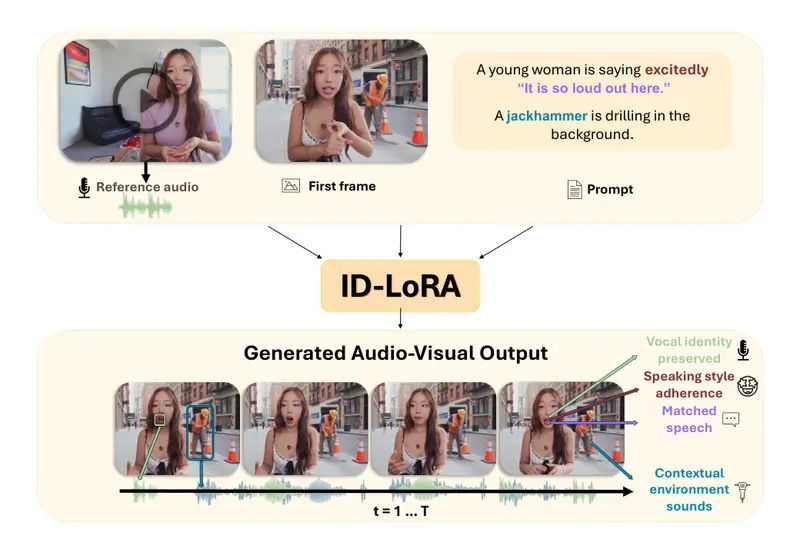
新ID-LoRA:让AI同时“克隆”你的长相和声音,还能配合场景表演你有没有想过,如果AI能根据一张照片和一段声音,就能生成一个“数字分身”,让这个分身在任何场景中说话、表演,而且声音和口型都能完美匹配,这会带来什么可能? 这正是特拉维夫大学等研究机构最新发布的 ID...视频模型# ID-LoRA# 数字人1天前070
新KokoClone:极速实时多语言语音克隆系统,基于 Kokoro-ONNX 驱动KokoClone 是一款构建在 Kokoro-ONNX(目前最快的开源神经语音合成引擎之一)之上的高性能语音克隆系统。它打破了传统 TTS(文本转语音)和语音转换的延迟瓶颈,实现了快速、实时兼容的多...语音模型# KokoClone# Kokoro-ONNX2天前060
黑森林实验室发布 FLUX.2 [klein] 9B-KV:多参考图像编辑速度飙升 2.5 倍黑森林实验室(Black Forest Labs)今日正式推出 FLUX.2 [klein] 9B-KV,这是其备受赞誉的轻量级图像编辑模型 FLUX.2 [klein] 9B 的专用优化变体。新版本...图像模型# FLUX.2 [klein] 9B-KV# 黑森林实验室4天前0800
上海 AI 实验室发布 InternVL-U:40 亿参数统一多模态模型,理解、推理、生成与编辑全能合一在人工智能领域,模型往往面临“专才”与“全才”的抉择:有的擅长理解图片内容,有的精于生成精美画作,但鲜有模型能同时精通“看、想、画、改”四项技能。 上海人工智能实验室正式推出 InternVL-U,一...多模态模型# InternVL-U# 上海 AI 实验室5天前0240
英伟达发布 Nemotron 3 Super:1200 亿参数 MoE 架构,智能体吞吐量飙升 5 倍随着企业 AI 应用从简单的聊天机器人向复杂的多智能体系统(Multi-Agent Systems)演进,两大瓶颈日益凸显:上下文爆炸导致成本激增与目标漂移,以及每一步都需大模型推理带来的高昂"思考税...大语言模型# NVIDIA Nemotron 3 Super# 英伟达5天前0110
Hume AI 开源 TTS 模型 TADA:文本 - 声学一对一同步,推理速度提升 5 倍且零幻觉在基于大语言模型(LLM)的文本转语音(TTS)领域,开发者长期面临一个“不可能三角”:速度、质量与可靠性难以兼得。传统的 LLM-TTS 系统往往因为文本与音频表示的不匹配,导致推理缓慢、内存消耗巨...语音模型# Hume AI# TADA# TTS5天前0390
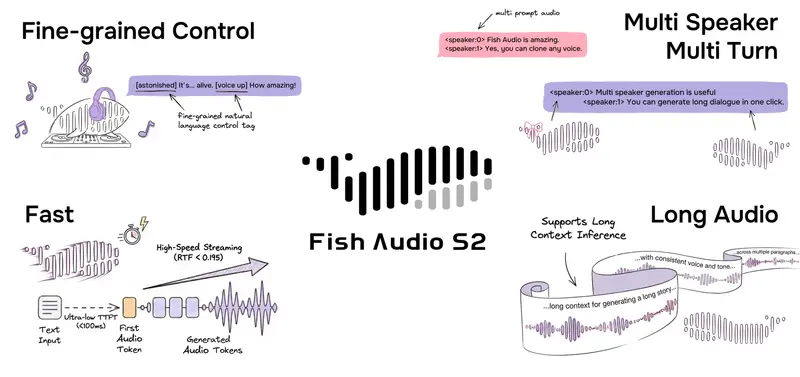
Fish Audio 开源 Fish Audio S2 Pro:支持自然语言指令的精细化 TTS 模型,单卡 H200 实时因子低至 0.195在文本转语音(TTS)领域,如何在保持高保真音质的同时,实现对韵律、情感和副语言特征(如笑声、呼吸声)的精细化控制,一直是行业难点。今日,Fish Audio 正式开源 S2 模型及其完整的生产级推理...语音模型# Fish Audio# Fish Audio S2 Pro5天前070
谷歌发布 Gemini Embedding 2:首个原生多模态嵌入模型,支持文本/图像/音视频统一检索谷歌今日通过 Gemini API 和 Vertex AI 正式开放 Gemini Embedding 2 的公开预览。这是谷歌首个基于 Gemini 架构构建的原生多模态嵌入模型,能够将文本、图像...多模态模型# Gemini Embedding 2# 多模态嵌入模型# 谷歌6天前0110
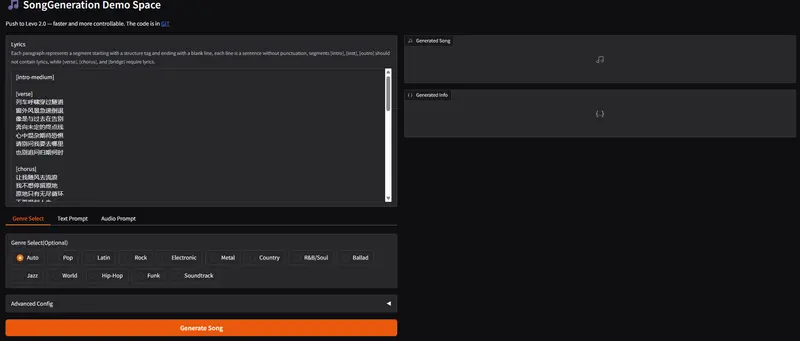
腾讯开源SongGeneration 2:歌词准确率超越 Suno v5,首个真正达到“商业级”的开源音乐大模型腾讯 AI 实验室重磅发布 LeVo 2 (SongGeneration 2) —— 一个旨在打破开源 AI 音乐天花板的基础模型。经过大规模、严格的专家盲测评估,LeVo 2 在音乐性、歌词准确性和...语音模型# SongGeneration 2# 腾讯7天前0870


![黑森林实验室发布 FLUX.2 [klein] 9B-KV:多参考图像编辑速度飙升 2.5 倍](https://pic.sd114.wiki/wp-content/uploads/2026/03/1773338443-1773338443-FLUX.webp~tplv-o4t1hxlaqv-image.image)