OmniVoice:小米 K2-FSA 团队开源 600+ 语言零样本 TTS,一句话复刻全球声音OmniVoice 是由 小米 K2-Fsa 团队 最新推出的文本转语音(TTS)模型。它打破了传统 TTS 的语言壁垒,支持超过 600 种语言(包括大量低资源语言和方言),并凭借创新的 扩散语言模...语音模型# OmniVoice# TTS5天前0120
谷歌发布Gemma 4:迄今为止最智能的开放模型,多硬件适配可离线运行今日,谷歌正式推出全新开放模型Gemma 4,并称其为“迄今为止最智能的开放模型”。该模型专为高级推理和智能体工作流打造,核心亮点在于实现了前所未有的单位参数智能水平,既能在自有硬件上高效运行,又能通...大语言模型早报# Gemma 4# 谷歌5天前0140
英伟达发布 Nemotron OCR v2:企业级多语言文本识别OCR模型英伟达正式推出了 Nemotron OCR v2,这是一款专为复杂真实世界场景设计的尖端多语言光学字符识别(OCR)模型。作为 NVIDIA NeMo Retriever 系列的核心成员,该模型不仅实...多模态模型# Nemotron OCR v# 英伟达5天前090
阿里正式发布Qwen3.6-Plus :迈向现实世界智能体的关键一步阿里巴巴今日正式宣布 Qwen3.6-Plus 上线,标志着通义千问系列在智能体(Agent)编程与原生多模态推理领域实现了里程碑式的跨越。作为 Qwen3.5 系列的继任者,Qwen3.6-Plus...多模态模型# Qwen3.6-Plus# 阿里巴巴5天前060
阿里巴巴发布 Wan2.7-Image:集图像生成与编辑于一体的统一模型,人更真、字更稳、色更准阿里巴巴今日正式发布 Wan2.7-Image,一款集图像生成与编辑于一体的统一模型。专为对内容品质有极致要求的创作者打造,Wan2.7-Image 直击当前 AI 生图领域的三大痛点:人物同质化(A...图像模型# Wan2.7-Image# 阿里巴巴6天前0250
Mugen:基于 Flux 2 VAE 的 SDXL 动漫模型新生,低成本实现高质量角色生成Mugen 是开发者 Cabal Research 推出的最新动漫生成模型系列。作为从 SDXL 到 Flux 2 VAE 潜空间转换技术的延续,Mugen 不仅重命名以区别于原始的 NoobAI 模...图像模型# Mugen# SDXL# 动漫模型6天前0290
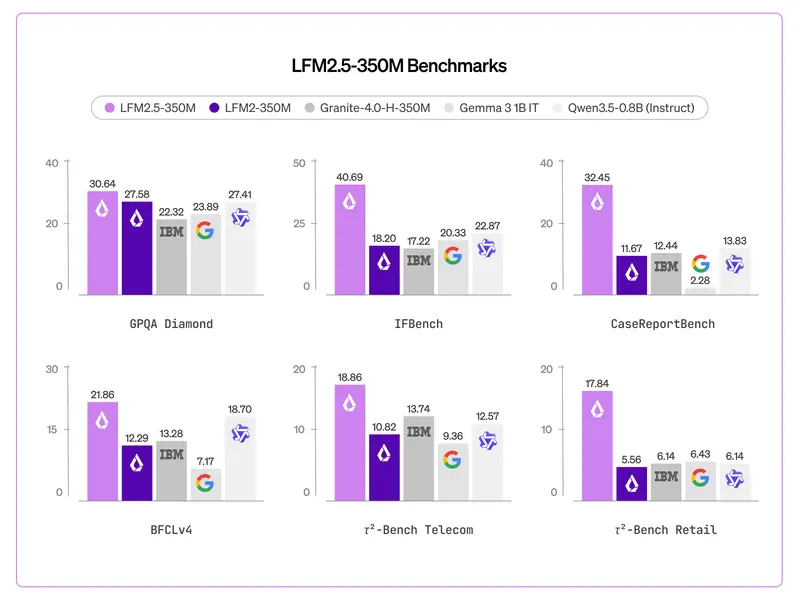
Liquid AI 发布 LFM2.5-350M:3.5 亿参数的“边缘智能”奇迹,重新定义小模型极限在生成式 AI 领域,“大力出奇迹”的规模法则(Scaling Law)似乎是不可动摇的铁律。然而,Liquid AI 今日发布的 LFM2.5-350M 向这一传统观念发起了有力挑战。这是一个仅有 ...大语言模型# LFM2.5-350M# Liquid AI6天前080
微软发布 Harrier-OSS-v1:基于解码器架构的多语言嵌入模型新标杆微软正式发布了 Harrier-OSS-v1,这是一套全新的多语言文本嵌入(Text Embedding)模型系列。该系列包含三种不同规模(2.7亿、6亿、270亿参数),并在权威的 多语言 MTEB...大语言模型百科# Harrier-OSS-v1# 多语言嵌入模型# 微软6天前0120
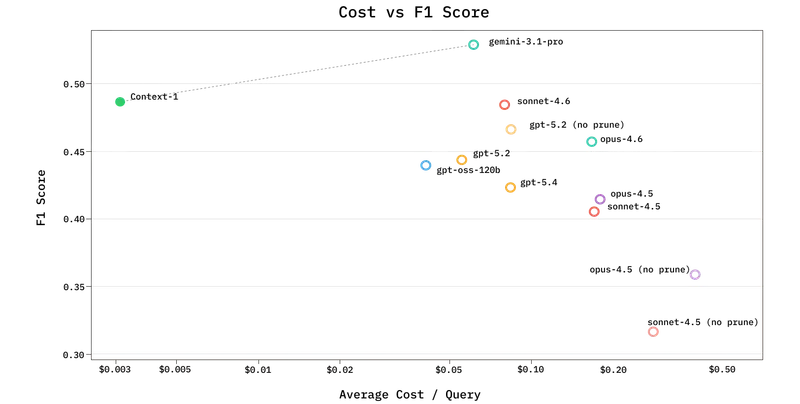
Chroma 发布 Context-1:20B 参数“侦察兵”模型,重新定义多跳检索与 RAG 架构在当前的 AI 浪潮中,“大力出奇迹”的上下文窗口扩展策略正面临瓶颈。将数百万 token 强行塞入提示词,不仅带来高昂的延迟和成本,更导致了著名的“迷失在中间(Lost in the Middle...大语言模型# Chroma# Context-16天前0150
谷歌推出 Veo 3.1 Lite:最具成本效益的视频生成模型,助力开发者大规模应用谷歌今日正式宣布推出 Veo 3.1 Lite,这是其 Veo 3.1 系列中最具成本效益的视频生成模型。该模型现已通过 Gemini API 和 Google AI Studio 向开发者开放,旨在...早报视频模型# Veo 3.1 Lite# 谷歌7天前0140
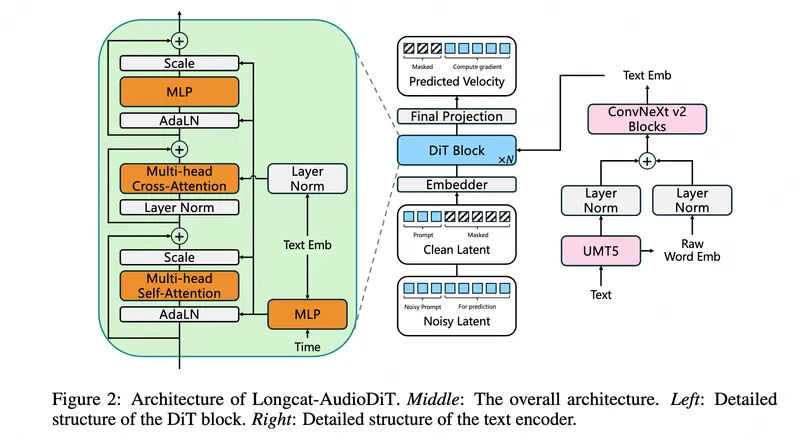
LongCat-AudioDiT:美团开源的端到端语音合成模型,直接在波形潜空间生成高保真语音美团 LongCat 团队推出了 LongCat-AudioDiT,这是一种基于扩散模型的最新文本转语音(TTS)系统。该模型的核心创新在于摒弃了传统的中间声学特征(如梅尔频谱图),直接在波形潜空间...语音模型# LongCat-AudioDiT# TTS# 美团7天前0100
See-through:一张静态动漫图,自动“透视”拆分为可动 2.5D 角色在虚拟主播(VTuber)、游戏开发和视觉小说制作中,将静态插画转化为可互动的 Live2D 模型 是标准流程。然而,传统制作极其耗时:画师需要手动将图片切割成数十个图层,凭想象“脑补”被头发遮挡的脸...图像模型# Live2D 模型# See-through7天前0310