在当前的 AI 浪潮中,“大力出奇迹”的上下文窗口扩展策略正面临瓶颈。将数百万 token 强行塞入提示词,不仅带来高昂的延迟和成本,更导致了著名的“迷失在中间(Lost in the Middle)”现象——模型在海量噪声中无法精准定位关键信息。
- 官方介绍:https://www.trychroma.com/research/context-1
- GitHub:https://github.com/chroma-core/context-1-data-gen
- 模型:https://huggingface.co/chromadb/context-1
Chroma(知名开源向量数据库公司)今日发布了 Context-1,一款专为解决这一痛点而生的 20B 参数智能体搜索模型。它不试图成为通用的推理引擎,而是定位为高度优化的"侦察兵":专门负责在复杂的多跳查询中拆解任务、执行搜索、清洗上下文,并将提炼后的“黄金信息”传递给下游的大模型进行最终生成。
核心理念:搜索与生成的解耦
Context-1 代表了一种架构范式的转变:将检索逻辑从应用代码或通用大模型中剥离,交给一个专门的子智能体。
- 传统 RAG:开发者编写硬编码的检索逻辑,或使用通用大模型被动地处理 retrieved chunks,容易受噪声干扰。
- Context-1 模式:模型本身就是一个自主智能体。它能理解复杂意图,将其分解为子目标,并行调用工具(如
search_corpus,grep_corpus,read_document),并迭代式地探索语料库。
架构背景
Context-1 基于 gpt-oss-20B(混合专家架构 MoE),通过监督微调(SFT)和基于 CISPO(分阶段课程优化)的强化学习训练而成。其核心能力不是“回答问题”,而是“找到支撑答案的确凿证据”。
杀手锏功能:自编辑上下文 (Self-Editing Context)
面对长程推理中不可避免的“上下文腐烂”问题,Context-1 引入了最具创新性的机制:主动剪枝。
- 痛点:随着多轮搜索的进行,上下文窗口会被大量冗余、无关的文档填满,导致通用模型注意力分散,推理能力下降。
- 解决方案:Context-1 经过专门训练,具备高达 0.94 的剪枝准确率。在搜索过程中,它会实时审查已收集的信息,主动执行
prune_chunks命令,丢弃不相关的段落。 - 效果:这种“软限制剪枝”使得模型能在有限的 32k 上下文窗口内,始终保持高信噪比。它像一个经验丰富的侦探,只保留关键线索,扔掉废纸,从而能够处理通常需要更大窗口才能完成的复杂多跳任务。
防泄漏基准与数据生成:context-1-data-gen
为了训练真正的多跳推理能力,Chroma 开源了 context-1-data-gen 工具链,彻底摒弃了静态基准测试的局限性。
四大垂直领域
该工具在以下领域生成高难度的合成多跳任务:
- 网页:开放网络的复杂研究任务。
- 金融 (SEC):基于 10-K, 20-F 等文件的深度财务分析。
- 法律 (专利):USPTO 现有技术检索与比对。
- 邮件:基于 Epstein 文件和安然公司语料库的证据链挖掘。
严格的生成流程
遵循 探索 → 验证 → 干扰 → 索引 模式:
- 生成必须跨多个文档桥接信息才能回答的“线索”和“问题”。
- 故意植入**“主题干扰项”**(看起来相关但逻辑无用的文档),防止模型通过简单的关键词匹配“幻觉”出正确答案,强制其进行真正的逻辑推理。
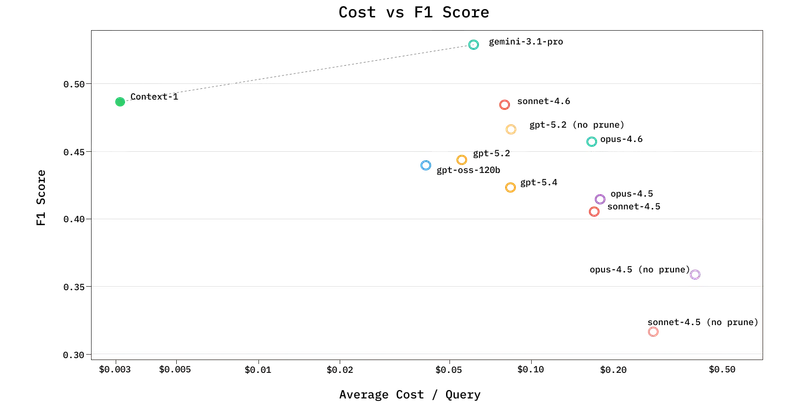
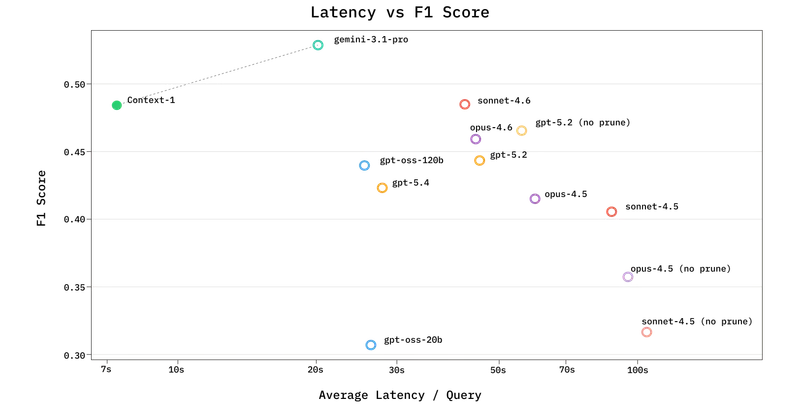
性能表现:以小博大,效率碾压
Chroma 公布的基准测试结果(BrowseComp-Plus, SealQA, FRAMES, HotpotQA)对“唯大模型论”提出了有力挑战。Context-1 在检索精度上与 GPT-5.4, Sonnet/Opus 4.6 等超大规模模型相当,但在效率上实现了数量级的超越:
| 指标 | Context-1 (20B) | 通用前沿模型 (如 GPT-5.4) | 优势倍数 |
|---|---|---|---|
| 推理速度 | 极快 | 慢 | 快 10 倍 🚀 |
| 运行成本 | 极低 | 极高 | 低 25 倍 💰 |
| 多跳稳定性 | 高 (随跳数增加性能稳定) | 低 (易出现性能悬崖) | 显著更优 📈 |
- 帕累托最优配置:通过 "4x" 策略(并行运行 4 个 Context-1 智能体,并使用倒数排名融合结果),其准确性可匹敌单次 GPT-5.4 运行,但计算消耗仅为后者的一小部分。
- 抗性能悬崖:通用模型随着推理跳数增加,往往难以维持搜索轨迹;而 Context-1 因专注于搜索任务,不会过早分心去“回答”,从而在深层推理链中表现更可靠。
分层 RAG 的未来
Context-1 的发布预示着一个新的架构趋势:分层智能体系统。
- 第一层(侦察兵):由像 Context-1 这样的高速、专用小模型组成。它们负责理解复杂意图、规划搜索路径、清洗海量数据,输出精简的“黄金上下文”。
- 第二层(将军):由超大参数的通用前沿模型(如 GPT-5, Claude Opus)组成。它们不再被琐事缠身,只需基于高质量的上下文进行最终的逻辑综合与答案生成。
这种分工不仅解决了延迟和成本问题,更从根本上提升了复杂任务的成功率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











