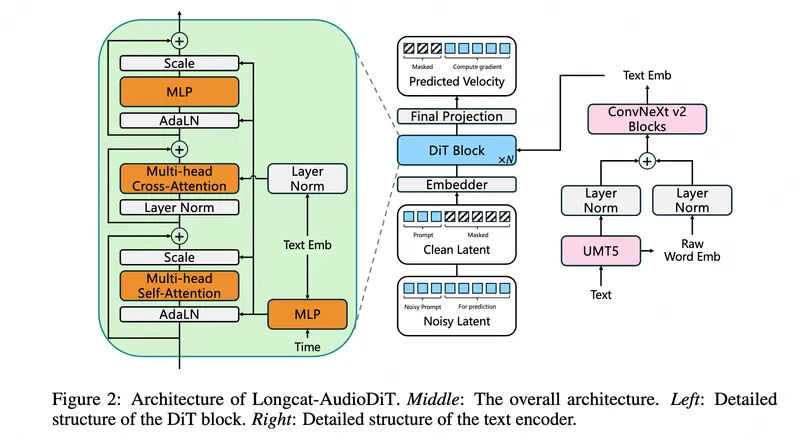
LongCat-AudioDiT:美团开源的端到端语音合成模型,直接在波形潜空间生成高保真语音美团 LongCat 团队推出了 LongCat-AudioDiT,这是一种基于扩散模型的最新文本转语音(TTS)系统。该模型的核心创新在于摒弃了传统的中间声学特征(如梅尔频谱图),直接在波形潜空间...语音模型# LongCat-AudioDiT# TTS# 美团1周前0100
See-through:一张静态动漫图,自动“透视”拆分为可动 2.5D 角色在虚拟主播(VTuber)、游戏开发和视觉小说制作中,将静态插画转化为可互动的 Live2D 模型 是标准流程。然而,传统制作极其耗时:画师需要手动将图片切割成数十个图层,凭想象“脑补”被头发遮挡的脸...图像模型# Live2D 模型# See-through1周前0310
阿里通义千问发布 Qwen3.5-Omni:全模态原生大模型,215 项 SOTA 碾压 Gemini 3.1 Pro“能听、能看、能思考、能执行,还能像真人一样打断和克隆声音。” 阿里巴巴正式发布了其最新一代全模态原生大模型——Qwen3.5-Omni。这款模型不仅在文本、图像、音频、视频的理解上实现了全面融合,更...多模态模型早报# Qwen3.5-Omni# 通义千问# 阿里1周前01330
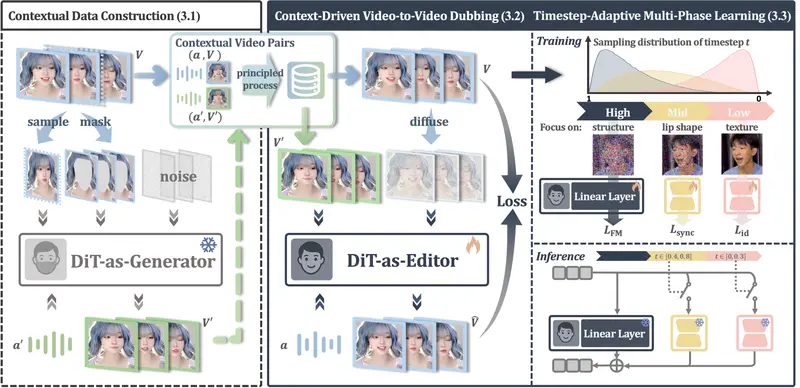
X-Dub:告别“面具式”配音,AI 让视频唇同步更自然逼真在影视翻译、虚拟人互动和短视频创作中,音频驱动的视觉配音(Visual Dubbing)技术至关重要。然而,传统方法长期受困于一个核心难题:缺乏完美的成对训练数据(即除了嘴型不同,其他完全一致的视频...视频模型# X-Dub# 数字人# 配音1周前0160
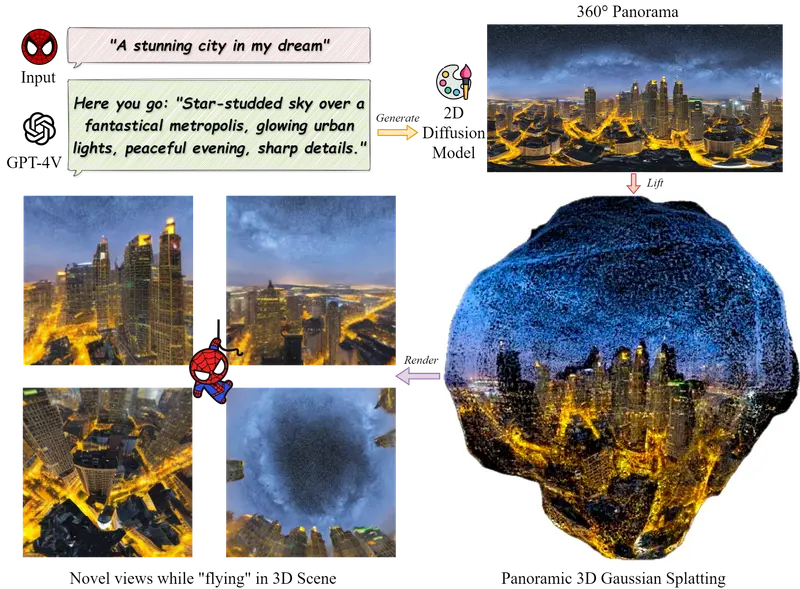
DreamScene360:输入文字,一键生成可沉浸式漫游的 360°3D 场景在虚拟现实(VR)、游戏开发和数字孪生领域,高质量 3D 场景的构建一直是最大的瓶颈。传统建模需要专业技能和数周时间,而现有的“文本生成 3D”技术往往只能生成单一视角的物体,或者生成的全景场景存在严...3D模型# 3D 场景# DreamScene3601周前0160
Foundation-1:重新定义 AI 音乐制作,首个“结构化文本生成采样”模型在 AI 音乐生成领域,大多数模型(如 Suno, Udio)专注于生成完整的歌曲或长段落,但对于专业音乐制作人而言,他们真正需要的是高质量的、可循环的、结构精准的采样(Samples/Loops...语音模型# Foundation-1# 采样模型1周前0190
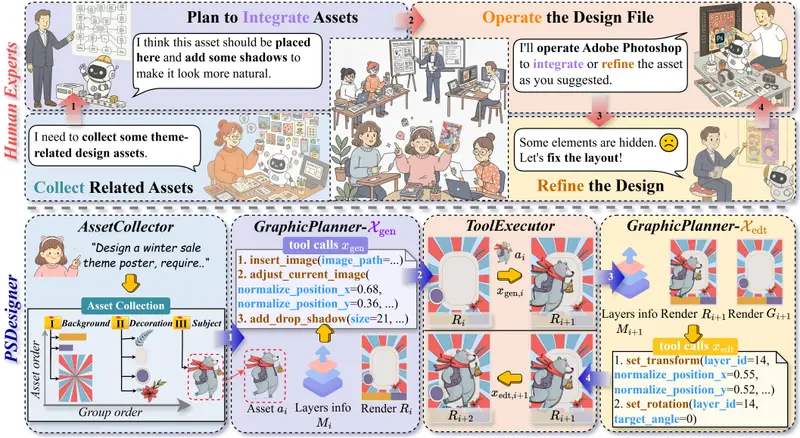
PSDesigner:首个模拟人类设计师工作流的自动化图形设计系统,直接生成可编辑 PSD 文件在 AI 绘画领域,Midjourney 等模型已经能生成令人惊叹的图像,但它们有一个致命弱点:输出的是“死”的位图。图层被合并、文字无法修改、元素无法移动。对于需要反复迭代、精细调整的电商海报、广告...图像模型# PSDesigner# 图形设计1周前0310
PixelSmile:复旦与StepFun联手打造,AI表情编辑迎来“微操”时代“笑得太假”、“愤怒变成了厌恶”、“改完表情不像本人了”——这些曾是AI人脸编辑难以逾越的鸿沟。如今,复旦大学与StepFun的研究团队共同推出了 PixelSmile,一款基于扩散模型的细粒度面部表...图像模型# PixelSmile# 面部表情编辑1周前0740
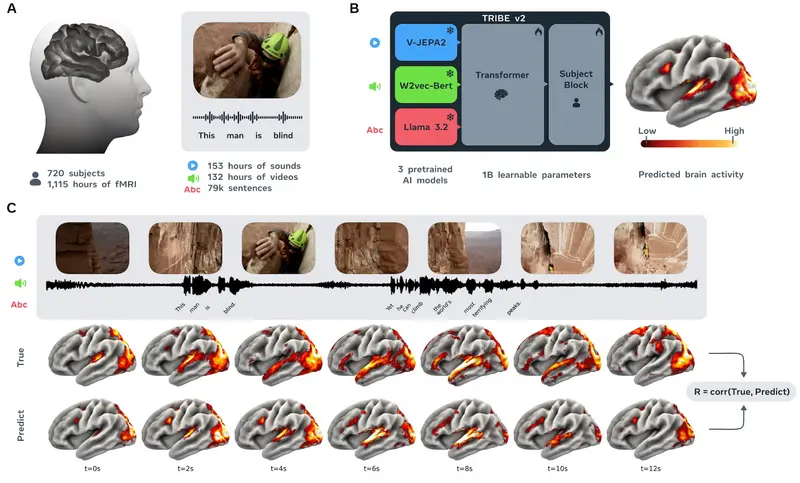
Meta 发布 TRIBE v2:AI 模型可精准预测大脑反应,神经科学迎来“数字孪生”时代脑科学研究长期受限于高昂的实验成本和缓慢的数据采集速度。功能性磁共振成像(fMRI)不仅需要昂贵的设备,还要求受试者长时间配合,且数据充满噪声。 GitHub:https://github.com/f...多模态模型# Meta# TRIBE v21周前080
RealRestorer:开源图像修复新标杆,九合一全能模型直逼闭源顶尖水平在自动驾驶、安防监控、遥感分析乃至日常摄影中,图像质量往往决定了下游任务的成败。然而,真实世界中的图像退化(如模糊、噪点、雾霾、反光等)复杂多变,传统修复模型往往“水土不服”,而效果卓越的闭源大模型...图像模型# RealRestorer# 图像修复2周前0980
智谱突袭发布GLM-5.1:编码能力暴涨 30%,直逼 Claude Opus,手把手教你接入 Claude Code 与 OpenClaw就在距离春节版 GLM-5.0 发布仅一个多月后,智谱 AI 今晚突然放出“大招”——正式推出改进版大模型 GLM-5.1。该模型现已面向 GLM Coding Plan 全体用户(Lite/Pro...大语言模型早报# Claude Code# Claude Opus# GLM-5.12周前03020
美团开源 LongCat-Next:原生多模态新范式,用“离散 Token”统一文本、图像与语音在人工智能迈向“通用智能”的征途中,如何处理文本、图像、语音等多种模态数据,一直是业界最大的挑战之一。传统方案往往需要为不同模态设计独立的编码器,或采用复杂的跨模态对齐机制,导致模型架构臃肿、训练困难...多模态模型# LongCat-Next# 美团2周前01210