美团开源 LongCat-Next:原生多模态新范式,用“离散 Token”统一文本、图像与语音在人工智能迈向“通用智能”的征途中,如何处理文本、图像、语音等多种模态数据,一直是业界最大的挑战之一。传统方案往往需要为不同模态设计独立的编码器,或采用复杂的跨模态对齐机制,导致模型架构臃肿、训练困难...多模态模型# LongCat-Next# 美团2周前01210
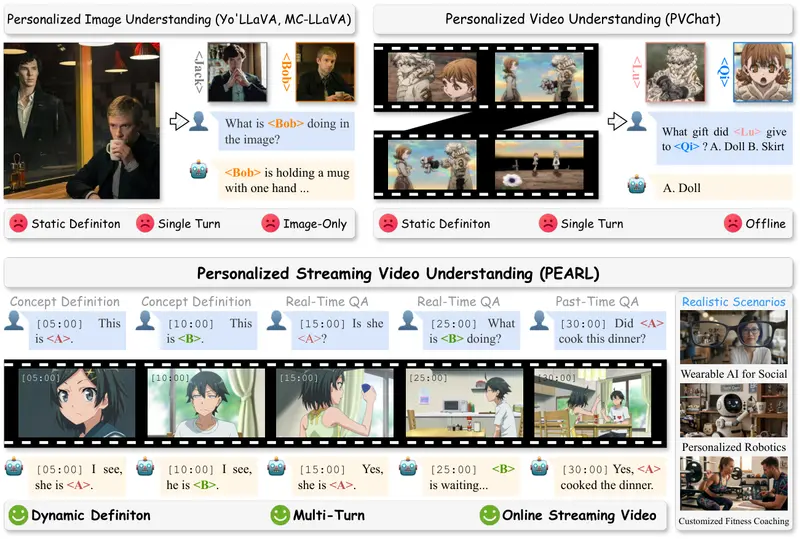
AI终于能“边看视频边记人”!北大等联合推出PEARL,实时互动不“失忆”想象一下这个场景:你正在看一部长达两小时的电影直播,中途你指着屏幕对 AI 助手说:“记住那个穿红衣服的女孩,她叫小红。” 十分钟后,你问:“小红现在在干嘛?” AI 立刻回答:“她在厨房切菜。” 半...多模态模型# PEARL# 视频理解2周前0330
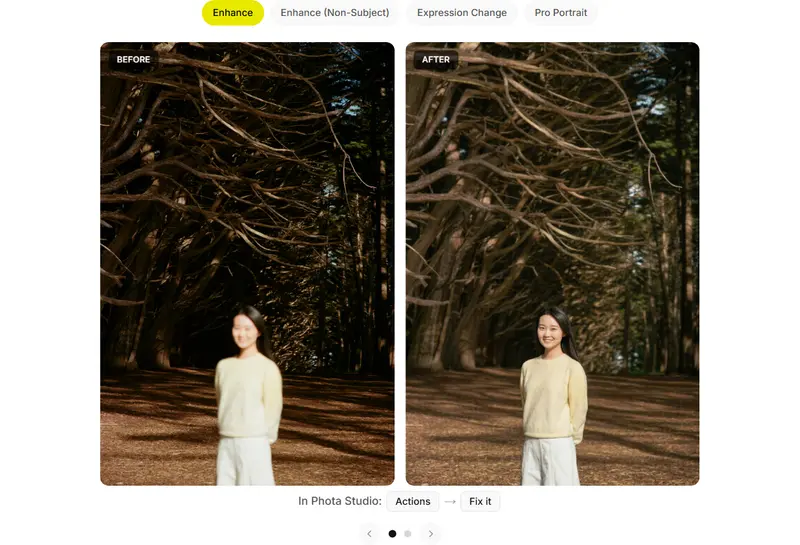
Phota Labs 发布全新 AI 摄影工具:保留真实人像,实现个性化照片创作与编辑在生成式 AI 席卷图像领域的今天,我们常常面临一个尴尬的困境:AI 生成的图片虽然精美,但里面的人“像我却不是我”。眼神不对、微笑的弧度陌生、甚至五官细节都发生了微妙的偏移。对于摄影而言,真实性与身...图像模型早报# Phota Labs2周前0800
Mistral 发布 Voxtral TTS:40 亿参数开源模型,以极致低延迟和跨语言克隆挑战 ElevenLabs法国 AI 独角兽 Mistral AI 今日正式进军语音合成领域,发布了其首款开源文本转语音(TTS)模型——Voxtral TTS。这款基于 Ministral 3B 架构打造的轻量级模型,旨在以...语音模型# Mistral# Voxtral TTS2周前0160
谷歌发布 Gemini 3.1 Flash Live:迄今最自然、最敏锐的语音 AI,支持全球 200+ 语言谷歌在 AI 语音交互领域再次迈出关键一步。今日,谷歌正式推出 Gemini 3.1 Flash Live,称其为“迄今为止最高质量的音频和语音模型”。这款新模型不仅大幅降低了延迟,更在语调理解、情绪...早报语音模型# Gemini 3.1 Flash Live# 谷歌2周前01180
Cohere 开源自动语音识别(ASR)模型 Cohere Transcribe:20 亿参数跑赢巨头,消费级显卡即可部署在企业 AI 赛道深耕多年的 Cohere 今日正式进军语音领域,发布了其首款开源自动语音识别(ASR)模型——Cohere Transcribe(cohere-transcribe-03-2026...语音模型# Cohere# Cohere Transcribe# 自动语音识别模型2周前0600
谷歌发布 Lyria 3 Pro:谷歌音乐生成迈入“完整曲目”时代,最长支持 3 分钟继上个月推出 Lyria 3 后,谷歌于本周三正式发布了其最新音乐生成模型 Lyria 3 Pro。这款升级版模型不仅将生成时长从 30 秒大幅延长至 3 分钟,更在音乐结构理解、创意控制和多平台集成...早报语音模型# Lyria 3 Pro# 谷歌2周前0330
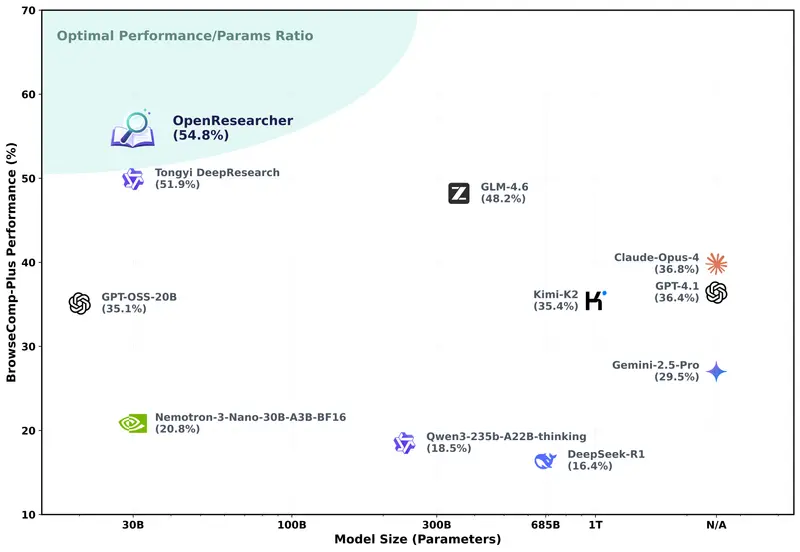
OpenResearcher:全开源深度研究智能体,离线合成百万级轨迹,性能超越 GPT-4.1 与 Claude Opus在 AI 自主代理(Agent)迈向“深度研究”的征途中,数据一直是最大的拦路虎。训练一个能像人类专家一样进行多步推理、交叉验证的 AI,需要海量的长周期研究轨迹数据。然而,现有的数据合成方案严重依赖...大语言模型# OpenResearcher2周前0190
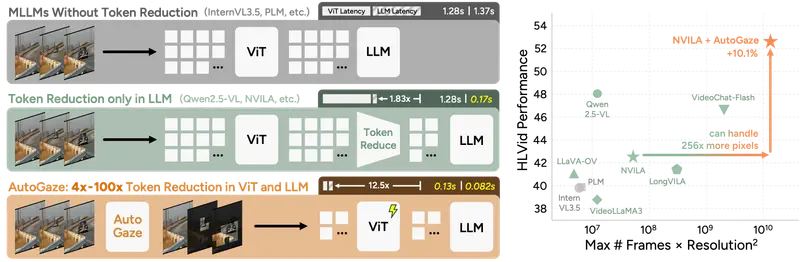
Attend Before Attention:伯克利与英伟达联手,让AI像人眼一样“扫视”视频,推理提速19倍在视频理解领域,长久以来存在一个巨大的效率悖论:人类只需扫视关键物体就能理解场景,而AI模型却必须像素级地“硬啃”每一帧。这种对时空冗余数据的无差别处理,导致当前的多模态大语言模型(MLLM)在面对长...多模态模型# Attend Before Attention# AutoGaze2周前0200
daVinci-MagiHuman:单流架构重塑音视频生成,1080p 仅需 38 秒的开源新标杆在 AI 生成内容(AIGC)领域,音视频联合生成一直被视为“皇冠上的明珠”。然而,现有的开源方案往往陷入两难:要么采用复杂的多流架构导致推理缓慢、难以优化,要么为了速度牺牲了人物表情与语音的自然度...视频模型# daVinci-MagiHuman# 视频生成2周前01260
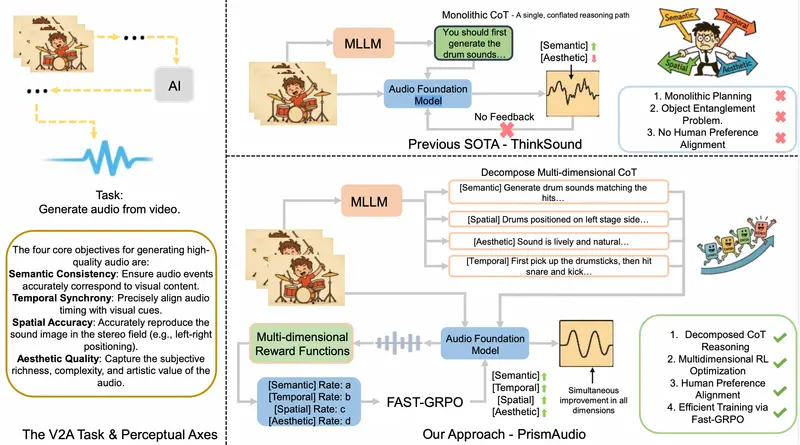
PrismAudio:阿里通义首创“思维链+强化学习”视频音效框架,让AI学会“先思考再发声”在视频生成领域,画面与声音的同步一直是难以攻克的“最后一公里”。传统的视频转音频(Video-to-Audio)模型往往采用“端到端”的黑箱模式:输入视频,直接输出音频。这种“直觉式”生成容易导致声音...视频模型# PrismAudio# 视频音效2周前0210
英伟达发布 Nemotron-Cascade 2:开源 30B MoE 模型,激活仅 3B 却斩获 IMO/IOI 金牌水平在“越大越强”的大模型军备竞赛中,英伟达走出了一条截然不同的路:追求极致的“智能密度”。 英伟达正式开源 Nemotron-Cascade 2,一款总参数量 30B、激活参数仅 3B 的混合专家模型...大语言模型# Nemotron-Cascade 2# 英伟达2周前01150