美团开源 5677 亿参数 LongCat-Flash-Prover:专攻数学证明,MiniF2F 通过率高达 97.1%在 AI 大模型普遍存在“逻辑幻觉”的今天,如何讓 AI 像数学家一样严谨地思考? 美团正式开源 LongCat-Flash-Prover,这是一款拥有 5677 亿参数 的混合专家模型(MoE)。它...大语言模型# LongCat-Flash-Prover# 美团2周前01670
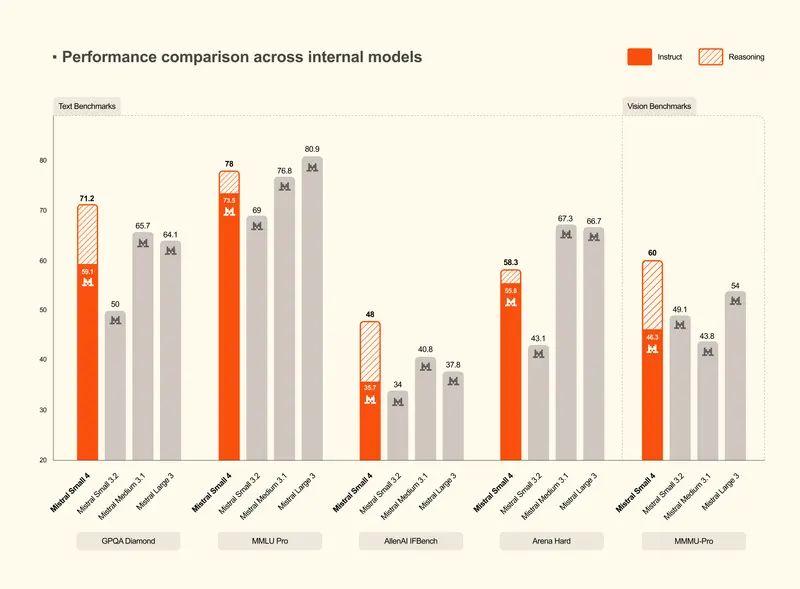
Mistral AI 宣布开源 Mistral Small 4:119B 参数集推理、编码与多模态于一身的统一模型,推理速度提升 3 倍Mistral AI 宣布开源 Mistral Small 4。这不仅仅是一次版本迭代,更是 Mistral 在开源 AI 领域的一次战略级跨越。 作为 Mistral Small 系列的最新旗舰,S...大语言模型# Mistral AI# Mistral Small 43周前0220
微软发布 MAI-Image-2:文生图跻身全球前三,逼真度与文字渲染全面升级微软 AI 正式推出了其最新的图像生成模型 MAI-Image-2。这款专为创意专业人士打造的模型,凭借在自然光影、肤色还原及复杂场景构建上的卓越表现,迅速在权威榜单 Arena-AI 文生图排行榜 ...图像模型# MAI-Image-2# 微软3周前0350
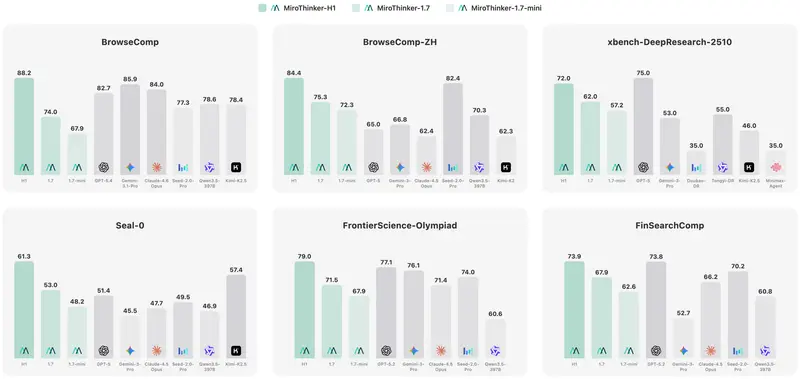
MiroThinker-1.7 系列重磅发布:30B 参数刷新开源 SOTA,打造长链推理新标杆在 AI 智能体(Agent)向复杂长程任务进军的道路上,MiroThinker 团队今日正式推出了 MiroThinker-1.7 系列模型。该系列包含 MiroThinker-1.7-mini ...大语言模型# MiroThinker-1.7# MiroThinker-1.7-mini3周前0270
OpenAI 发布 GPT-5.4 mini 与 nano:极速、低价,重塑智能体经济OpenAI 正式推出 GPT-5.4 mini 和 GPT-5.4 nano,将其旗舰模型系列的能力下沉至成本与延迟曲线的底端。这两款新模型专为高吞吐量场景设计,旨在成为编程助手、子智能体(Sub...大语言模型# GPT-5.4 mini# GPT-5.4 nano# OpenAI3周前0180
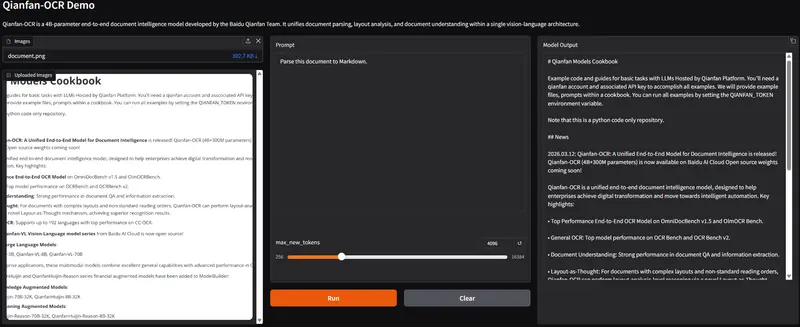
百度千帆发布 Qianfan-OCR:4B 参数端到端模型,文档解析能力全球第一百度千帆团队推出 Qianfan-OCR,这是一款参数量仅为 4B 的端到端文档智能大模型。不同于传统“检测 + 识别 + 理解”的多阶段流水线,Qianfan-OCR 在单一的视觉 - 语言架构内...多模态模型# Qianfan-OCR# 百度千帆3周前0590
限时免费体验一周!小米凌晨官宣三款大模型:MiMo-V2 系列正式亮相,1M 上下文比肩 Opus 4.6小米正式推出三款全新大模型——MiMo-V2-Pro、MiMo-V2-Omni与MiMo-V2-TTS,目前这些模型已登陆Xiaomi miclaw、MiMo Studio、金山办公、小米浏览器等平台...大语言模型# MiMo-V2# MiMo-V2-Omni# MiMo-V2-Pro3周前03910
MiniMax 发布 M2.7:首个实现“自我进化”的 Agent 模型,研发效率提升 50%2026 年 3 月18日,国内大模型独角兽 MiniMax(稀宇科技) 正式发布了新一代 Agent 旗舰大模型 M2.7。这款模型不仅刷新了多项代码与办公基准测试的纪录,更首次向外界展示了 “模型...大语言模型# M2.7# MiniMax3周前01660
阿里通义实验室开源 Fun-CineForge:首个影视级多场景 AI 配音大模型,攻克“音画同步”与“多人对话”难题在 AI 语音合成(TTS)日益普及的今天,将其应用于专业影视制作仍面临巨大挑战:口型对不上、情感不到位、多人对话混乱、画面遮挡时声音消失…… 阿里通义实验室正式宣布开源 Fun-CineForge ...语音模型# Fun-CineForge# 通义实验室# 配音大模型3周前0230
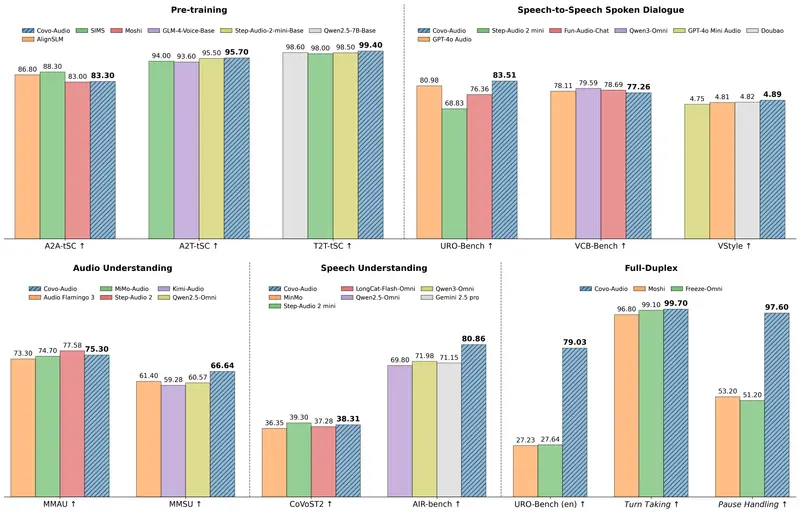
Covo-Audio:腾讯开源 7B 端到端语音大模型,重新定义“像人一样”的对话在 AI 语音交互领域,长期存在一个痛点:传统的“语音识别 (ASR) + 大语言模型 (LLM) + 语音合成 (TTS)”三段式架构,导致信息丢失、延迟累积、情感匮乏,且难以实现真正的实时打断与插...语音模型# Covo-Audio# 腾讯3周前0400
智谱 AI 重磅发布 GLM-5-Turbo:专为 OpenClaw“龙虾”打造的极速智能体引擎在 AI 智能体(Agent)从“对话”走向“执行”的关键时刻,智谱 AI 正式推出了 GLM-5-Turbo —— 一款专为 OpenClaw(俗称“龙虾”)场景深度优化的基座模型。 国内版: 文档...多模态模型早报# GLM-5-Turbo# 智谱 AI3周前01310
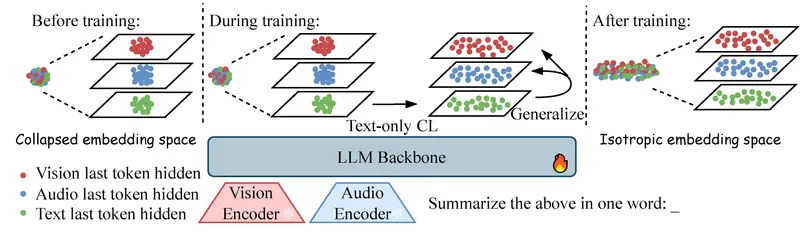
LCO-EMB:阿里达摩院新突破,用“纯文字”训练出全能多模态AI想象一下,你只需要教 AI 读书(文字),它就能无师自通地看懂图片、听懂音频、理解视频。这听起来像魔法,但阿里达摩院最新推出的 LCO-EMB(Language-Centric Omnimodal E...多模态模型# LCO-EMB3周前0130