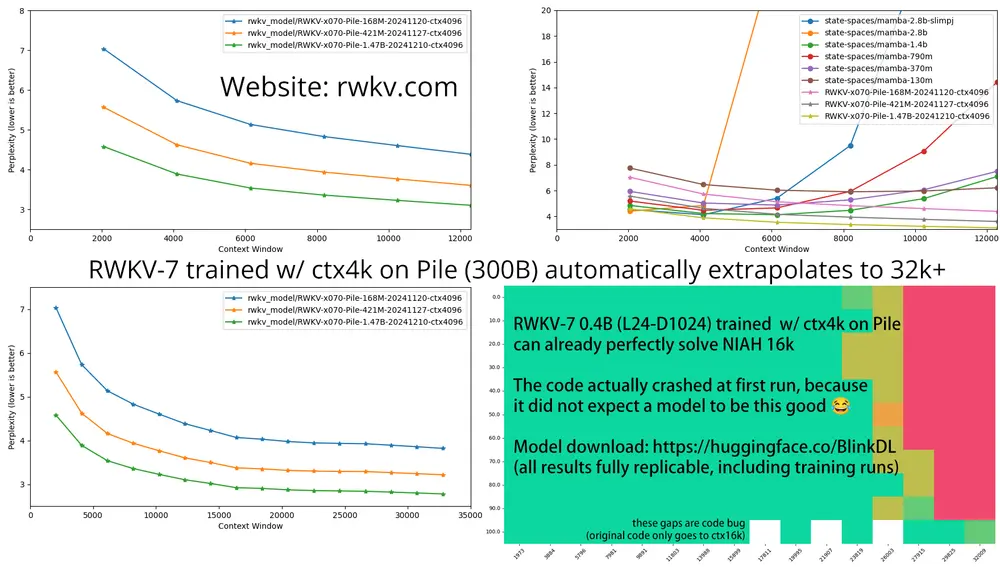
LG AI Research正式开源了其最新研发的AI推理模型——EXAONE Deep。这款模型分为2.4B、7.8B和32B三个版本,在多个关键领域展现出卓越性能。据官方称,EXAONE Deep 32B在部分测试中的表现甚至超越了DeepSeek等知名大模型。
- GitHub:https://github.com/LG-AI-EXAONE/EXAONE-Deep
- 模型:https://huggingface.co/collections/LGAI-EXAONE/exaone-deep-67d119918816ec6efa79a4aa
代理AI的时代来临:增强推理能力至关重要
随着AI技术的快速发展,一个全新的AI时代正在到来——代理AI(Agent AI)。这种AI能够独立提出假设、验证它们,并在无需人类指令的情况下自主决策。这标志着AI从“工具型”向“自主型”的转变。然而,要实现这一目标,开发高性能的推理模型是核心挑战之一。
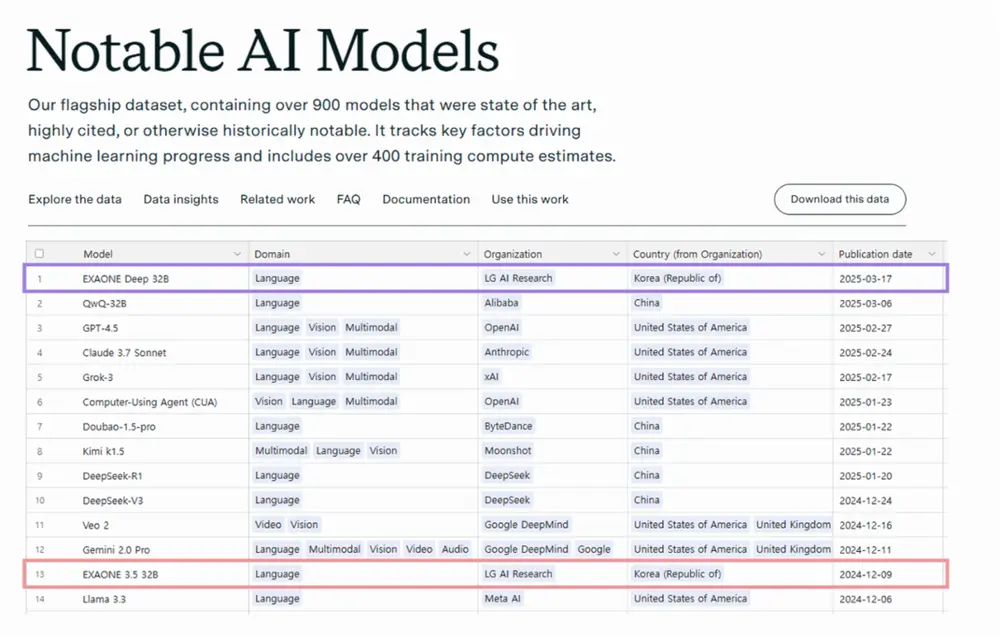
目前,全球范围内能够开发出高级推理模型的公司屈指可数,这些模型的研发不仅需要强大的技术积累,还需要海量资源支持。LG AI Research推出的EXAONE Deep正是为了应对这一挑战而生。它在数学逻辑、科学推理以及编程问题解决等方面表现出色,成为一款具备增强推理能力的高性能模型。
EXAONE Deep的核心亮点
为了让EXAONE Deep在推理性能上达到行业领先水平,研发团队专注于提升其在数学、科学和编码领域的表现,同时确保模型能够在多领域中灵活应用。以下是EXAONE Deep在不同领域的具体表现:
1. 数学:高难度基准测试中的亮眼成绩
EXAONE Deep 32B
在高难度数学基准测试中,EXAONE Deep 32B以仅占竞争对手5%的模型规模,实现了与之相当的性能。例如,在2025年高考数学部分,该模型获得了94.5分;在美国奥林匹克数学选拔考试(AIME 2024)中,得分为90.0分;而在AIME 2025中,它与DeepSeek-R1(671B)模型的表现不相上下。这充分证明了EXAONE Deep在复杂数学问题上的解题能力和逻辑推理能力。EXAONE Deep 7.8B & 2.4B
这两款轻量级模型同样表现出色。在MATH-500基准测试中,7.8B模型得分为94.8,2.4B模型得分为92.3;在AIME 2024中,7.8B模型得分为59.6,2.4B模型得分为47.9。无论是作为设备端模型还是轻量级模型,它们都在各自类别中排名第一,展现了极高的实用价值。
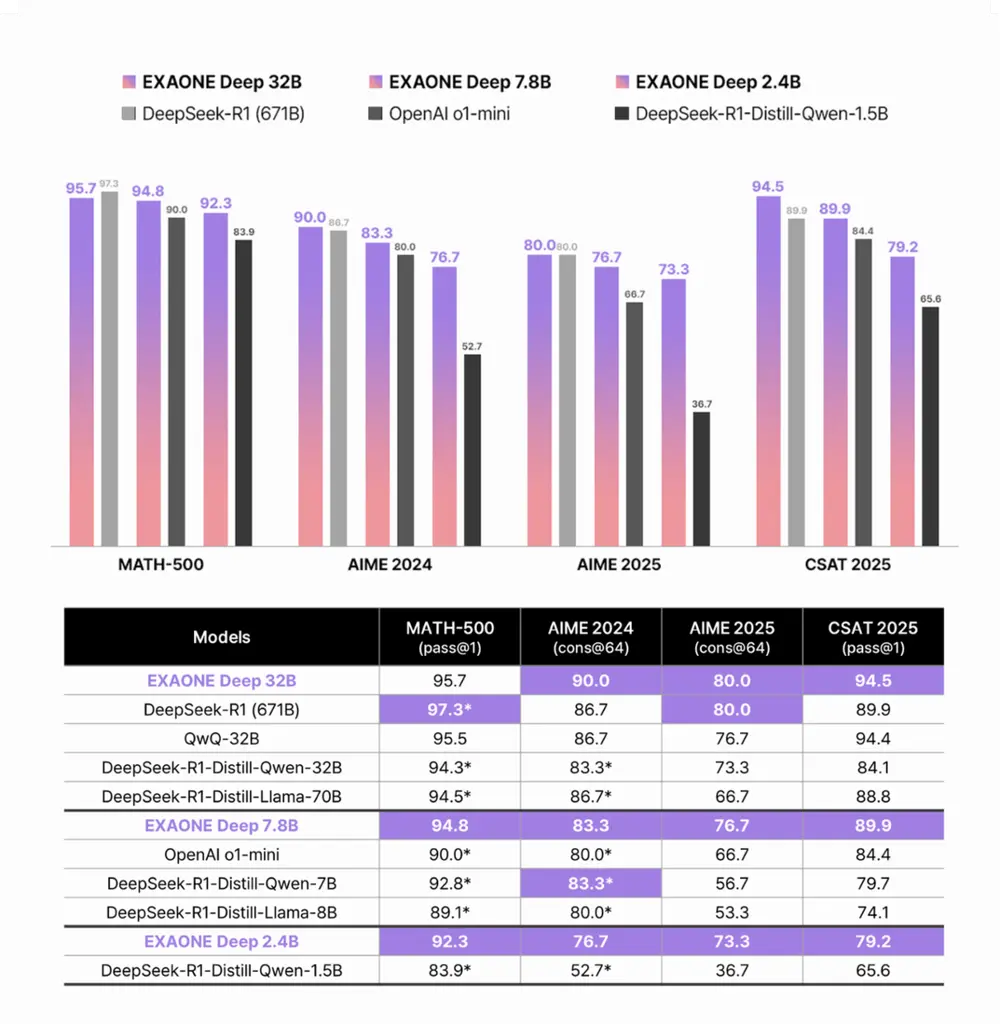

2. 科学与编码:博士级解题能力与高效编码表现
EXAONE Deep 32B
在评估物理、化学和生物学博士级解题能力的GPQA Diamond测试中,EXAONE Deep 32B取得了66.1分的优异成绩。此外,它在评估编码能力的LiveCodeBench基准测试中录得59.5分,超越了类似规模的其他推理AI模型。这表明该模型在专业领域的适用性极高。EXAONE Deep 7.8B & 2.4B
这两款轻量级模型同样在GPQA Diamond和LiveCodeBench中排名第一。特别是在Hugging Face的“LLM排行榜”边缘类别中,EXAONE Deep 2.4B继去年12月发布的EXAONE 3.5之后再次夺冠,进一步巩固了其在轻量级和设备端模型领域的领先地位。

3. MMLU:国内模型中的最高分
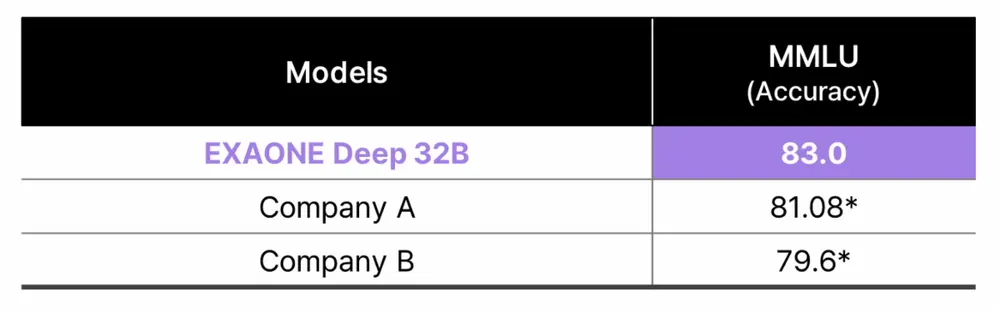
除了在特定领域的突出表现,EXAONE Deep在通用语言理解方面也毫不逊色。在衡量通用推理能力的MMLU测试中,EXAONE Deep 32B取得了83.0分,成为韩国开发模型中的最高分。这不仅证明了其在数学、科学和编码领域的专业推理能力,还展示了其在多领域知识理解和应用上的综合实力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











