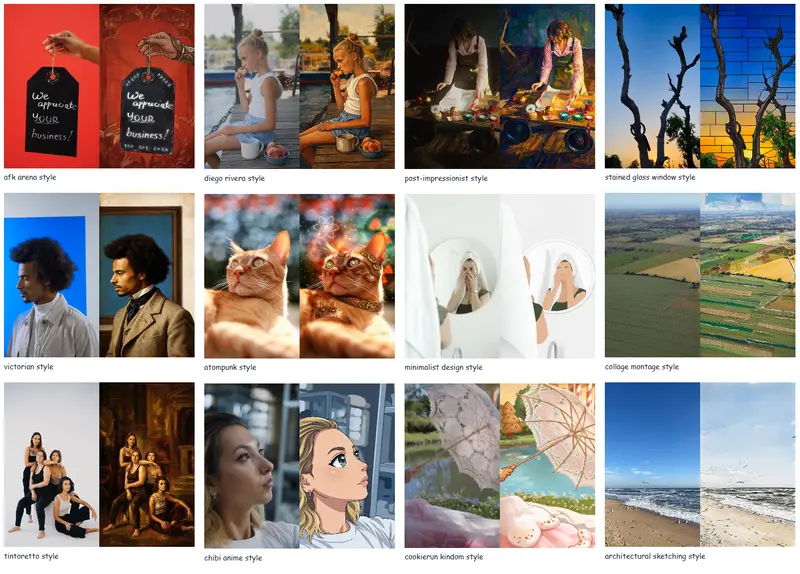
电信AI研究院提出TeleStyle:DiT架构下实现图像/视频内容保持式风格迁移SOTA中国电信人工智能研究院(TeleAI)提出TeleStyle——一款轻量级且高效的图像与视频内容保持式风格迁移模型,核心基于Qwen-Image-Edit构建,针对性解决了扩散变换器(DiT)架构中内...图像模型# TeleStyle# 风格迁移1个月前0390
Apache 2.0 许可!Photoroom 推出轻量级 13 亿参数开源文生图模型 PRXPhotoroom 团队正式发布了其首个开源文生图模型 PRX (Photoroom Experimental)。这是一个拥有 13 亿参数、完全从头开始训练 的扩散变换器模型,并以宽松的 Apach...图像模型# Photoroom# PRX1个月前0350
腾讯混元推出 HunyuanImage 3.0-Instruct:原生多模态图像编辑模型,支持精准编辑与多图融合腾讯混元项目组正式开源 HunyuanImage 3.0-Instruct —— 一款专注于图像编辑的原生多模态大模型。该模型不仅能理解输入图像的语义内容,还能基于复杂指令进行推理,并生成高保真、高一...图像模型# HunyuanImage 3.0-Instruct# 多模态图像编辑模型1个月前0340
阿里DiffSynth-Studio 项目组推出Z-Image-i2L:从单张图像一键生成风格 LoRA阿里 DiffSynth-Studio 项目组 推出 Z-Image-i2L(Image to LoRA)模型——一种“以图生 LoRA”的创新方案。只需输入一张或多张风格统一的图像,模型即可自动生成...图像模型# DiffSynth-Studio# Z-Image-i2L1个月前01480
阿里通义 MAX 项目组发布 Z-Image :支持 CFG 与微调,面向专业创作的非蒸馏基础模型在用户热切期盼下,阿里通义 MAX 项目组正式开源 Z-Image 完整版——这是 Z-Image 系列的基础大模型,专为追求最高生成质量、最大创作自由度与最强提示控制力的专业用户设计。 Huggin...图像模型# Z-Image# 通义 MAX1个月前0340
黑森林实验室发布 FLUX.2 [klein]:统一生成与编辑的最快开源模型黑森林实验室(Black Forest Labs)今日正式推出 FLUX.2 [klein] 模型系列——这是目前速度最快、体积最小的高质量图像生成模型家族。它将文生图、图像编辑与多参考图生成统一于单...图像模型# FLUX.2 [klein]# 黑森林实验室2个月前01900
智谱AI开源GLM-Image:自回归+扩散混合架构,攻克知识密集型图像生成难题智谱AI正式推出GLM-Image——业界首个开源的工业级离散自回归图像生成模型。这款模型创新性地采用自回归模块+扩散解码器的混合架构,既继承了自回归模型对复杂语义的精准理解能力,又兼具扩散模型高保真...图像模型# GLM-Image# 智谱AI2个月前01840
阿里发布文生图模型Qwen-Image-2512:人像、纹理、文字渲染显著提升2025 年 12 月 31 日,阿里 Qwen 项目组发布了 Qwen-Image-2512 —— Qwen-Image 文生图基础模型的最新版本。这是继今年 8 月首次开源 Qwen-Image ...图像模型# Qwen-Image-2512# 文生图模型2个月前0390
1步顶100步!TwinFlow让Qwen-Image、Z-Image推理提速100倍,无需判别器或教师模型当前,大规模多模态生成模型(如 Qwen-Image、Z-Image)在图像与视频生成上展现出惊人能力,但其推理效率仍严重受限——标准扩散或流匹配模型通常需 40–100 次函数评估(NFE)才能生成...图像模型# TwinFlow# TwinFlow-Qwen-Image# TwinFlow-Z-Image-Turbo2个月前01430
fal 发布FLUX.2 Turbo:开源图像模型速度提升6倍,成本降至0.008美元/图在完成 1.4 亿美元 D 轮融资后,AI 媒体基础设施平台 fal.ai(简称 fal)于年末推出其最新成果:FLUX.2 [dev] Turbo —— 一款基于 Black Forest Labs...图像模型# FLUX.2 Turbo2个月前01000
告别 “改不动”!ProEdit:反转编辑新方案,精准修改图像属性,即插即用超 SOTA解决源图像信息过度注入问题,实现更可控的图像与视频编辑 由中山大学、香港中文大学、香港大学与南洋理工大学联合提出,ProEdit 是一种高精度、即插即用的基于反转(inversion-based)的视...图像模型# ProEdit# 编辑图像2个月前0820
阿里通义实验室发布Qwen-Image-Edit-2511:显著提升人物一致性与工业设计能力,支持 LoRA 集成与多图融合阿里通义实验室 Qwen 项目组正式发布 Qwen-Image-Edit-2511,这是继 9 月发布的 Qwen-Image-Edit-2509 后的增强版本。从版本号“2511”可见,该模型原计划...图像模型# Qwen-Image-Edit-2511# 图像编辑模型3个月前01760




![黑森林实验室发布 FLUX.2 [klein]:统一生成与编辑的最快开源模型](https://pic.sd114.wiki/wp-content/uploads/2026/01/1768500030-1768500030-FLUX.2-klein-2.webp~tplv-o4t1hxlaqv-image.image)











