
解决源图像信息过度注入问题,实现更可控的图像与视频编辑
由中山大学、香港中文大学、香港大学与南洋理工大学联合提出,ProEdit 是一种高精度、即插即用的基于反转(inversion-based)的视觉编辑方法。它专门针对当前主流编辑框架(如 RF-Solver、FireFlow、UniEdit)中的一个核心缺陷——源图像信息过度注入——提出系统性解决方案。
该问题表现为:尽管编辑后图像在背景或结构上保持了与原图的一致性,但用户指定的属性(如颜色、姿态、数量)无法被正确修改。例如,指令“将橙色猫改为黑色”却仍保留橙色,或“添加第二只猫”却无法生成新主体。

ProEdit 从注意力机制与潜在空间两个层面入手,实现了精准属性编辑与背景一致性的兼顾。

问题根源:源信息过度注入
在基于反转的编辑流程中,模型通常通过在采样过程中注入源图像的特征(如注意力 KV 对或潜在表示),以维持非编辑区域的稳定性。
然而,这种注入往往是全局且无差别的,导致:
- 目标文本提示(如 “黑色”)的注意力权重被源图像特征压制
- 编辑区域仍“记住”原始属性,难以响应新指令
- 出现“改不动”“改不全”“改错对象”等失败案例
可视化分析显示:在 RF-Solver 等方法中,源文本标记对视觉 token 的注意力始终高于目标提示,即使目标语义更相关。
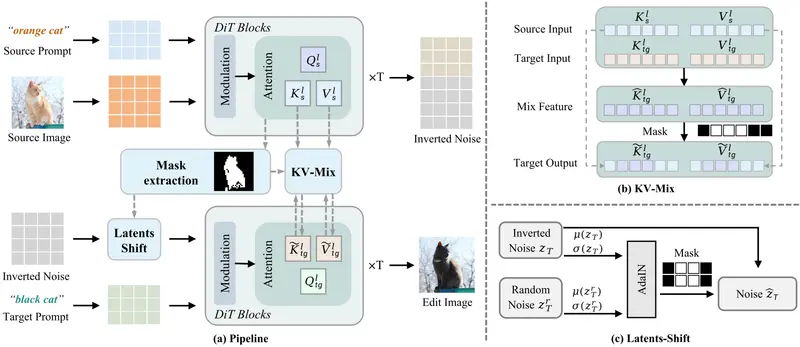
ProEdit 的双路径解决方案
1. KV-mix:注意力层面的区域感知融合
- 核心思想:在编辑区域混合源图像与目标提示的 Key-Value 特征;在非编辑区域保留完整源特征
- 效果:
- 编辑区域:降低源图像先验影响,增强目标提示控制力
- 背景区域:维持原始结构与纹理一致性
- 实现:通过掩码区分编辑/非编辑区域,动态融合 KV 对
2. Latents-Shift:潜在空间的扰动解耦
- 核心思想:在反转得到的初始噪声(latent)中,对编辑区域施加可控扰动(如注入随机噪声)
- 效果:打破源图像潜在表示对采样过程的强约束,使扩散模型能更自由地响应新提示
- 优势:无需训练,仅在推理阶段操作,计算开销极低
工作流程
- 掩码提取:基于源提示与目标提示的语义差异,自动识别需编辑的区域
- 潜在扰动:对反转得到的初始 latent,在编辑区域应用 Latents-Shift
- 选择性特征融合:在采样过程中,对编辑区域使用 KV-mix,非编辑区域直接注入源 KV
- 生成输出:得到既符合新指令、又保留背景一致性的高质量结果
整个流程无需额外训练,可作为模块插入现有反转编辑 pipeline。
实验结果
图像编辑(PIE-Bench)
| 方法 | Structure Distance ↓ | PSNR ↑ | CLIP Sim ↑ |
|---|---|---|---|
| UniEdit(基线) | 10.56 | 28.74 | 89.21 |
| UniEdit + ProEdit | 9.22 | 30.08 | 90.87 |
→ 在保持结构的同时,显著提升编辑准确性与图像质量。
视频编辑(自建数据集)
| 指标 | RF-Solver | RF-Solver + ProEdit |
|---|---|---|
| 主体一致性 | 0.9425 | 0.9712 |
| 运动平滑度 | 0.9841 | 0.9920 |
| 成像质量 | 0.6412 | 0.6936 |
→ 在视频中实现时空一致的属性修改,无闪烁或跳变。
即插即用设计
ProEdit 并非独立模型,而是一个通用增强模块,可无缝集成至多种现有框架:
- ✅ RF-Solver
- ✅ FireFlow
- ✅ UniEdit
- ✅ 其他基于 inversion + attention injection 的方法
只需在采样阶段插入 KV-mix 与 Latents-Shift 逻辑,即可获得显著性能提升。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











