
在生成模型中,可控人脸合成是一项极具挑战的任务。既要保证生成图像的真实感与细节质量,又要实现对发型、五官、表情等语义属性的精确控制,二者往往难以兼顾。
现有方法常将语义条件直接拼接或交叉注意力注入生成模型,导致属性间耦合严重——修改头发可能意外改变脸型,调整眼镜却影响肤色。这种“牵一发而动全身”的现象,限制了其在身份敏感场景(如司法重建、虚拟角色设计)中的应用。
为此,北京交通大学、蚂蚁集团、青海大学与清华大学联合提出 Face-MoGLE ——一个基于扩散变换器(Diffusion Transformer, DiT)的新型人脸生成框架。它通过语义解耦建模、全局-局部专家协同与动态门控机制,实现了高质量与细粒度控制的统一。
- 项目主页:https://xavierjiezou.github.io/Face-MoGLE
- GitHub:https://github.com/XavierJiezou/Face-MoGLE
- 模型:https://huggingface.co/XavierJiezou/face-mogle-models
该框架支持多模态输入(文本 + 掩码),可广泛应用于文本到人脸、掩码到人脸及混合条件生成任务,并展现出强大的零样本泛化能力。

核心挑战:语义控制与真实感的平衡
理想的人脸生成系统应具备:
- 高保真度:皮肤纹理、光影细节逼真;
- 精确可控性:能独立编辑特定属性(如只换发型不改脸型);
- 多模态兼容:支持文本、掩码、草图等多种输入形式;
- 泛化能力强:无需重新训练即可适应新属性或组合。
然而,传统方法在以下方面存在瓶颈:
- 条件注入方式粗暴,语义信息混合不分离;
- 缺乏对局部区域的精细化建模;
- 控制机制静态固定,无法随去噪过程动态调整。
Face-MoGLE 的设计正是为了解决这些问题。
方法创新:三大关键技术
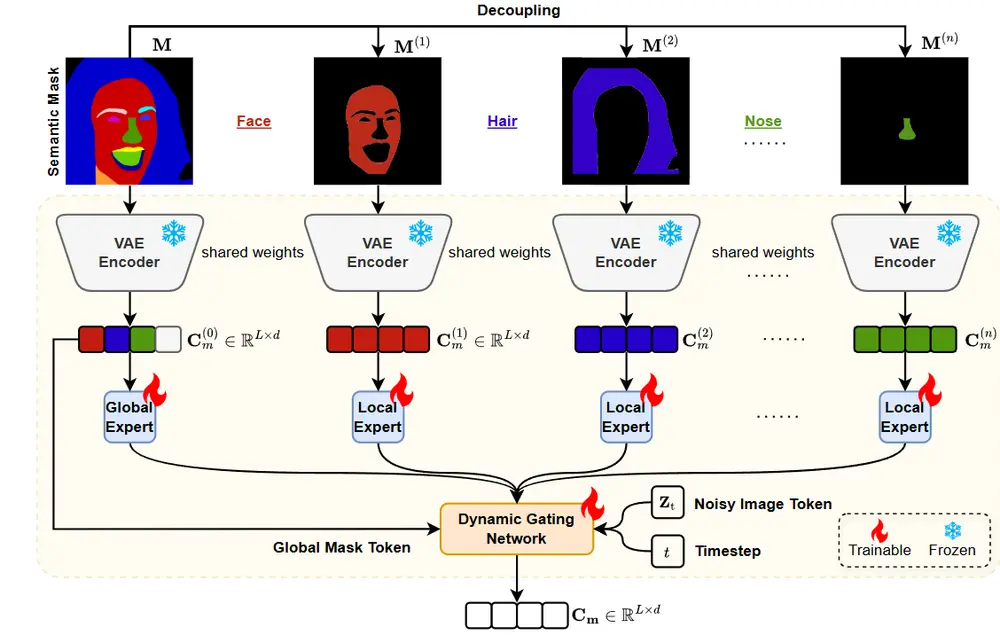
1. 语义解耦的潜在建模:实现属性独立操作
Face-MoGLE 首先将输入的语义掩码进行空间因式分解,拆分为多个独立的二进制掩码:
- 头发
- 眼睛
- 鼻子
- 嘴巴
- 脸型
- 配饰(眼镜、帽子等)
每个掩码通过一个共享权重的VAE编码器映射为潜在表示。这种方式确保不同属性的特征在潜在空间中保持解耦,从而支持精准编辑。
✅ 示例:仅修改“眼镜”掩码,即可生成戴/不戴眼镜的同一人物,其他属性保持不变。
2. 全局与局部专家混合架构:兼顾整体结构与细节质量
Face-MoGLE 引入“专家混合”(Mixture of Experts, MoE)思想,在DiT主干中部署两类专家:
| 专家类型 | 功能 |
|---|---|
| 全局专家 | 捕捉面部整体结构与姿态,确保身份一致性 |
| 局部专家 | 专注特定区域(如眼部、嘴部)的细节生成 |
每个patch(图像块)根据其语义归属,被路由至对应的专家处理。例如,属于“眼睛”的patch由局部眼睛专家优化,而背景区域则交由全局专家协调。
这种分工机制既提升了局部细节质量,又维持了整体协调性。
3. 动态门控网络:随时间和空间演化的控制权重
传统MoE使用静态门控,难以适应扩散模型逐步去噪的特点。
Face-MoGLE 提出动态门控网络(Dynamic Gating Network),其输出权重由两个因素决定:
- 扩散步骤:早期注重整体结构(全局专家权重高),后期强调细节精修(局部专家权重上升);
- 空间位置:不同区域激活不同专家组合。
门控信号随去噪进程自适应变化,实现“先整体、后局部”的生成策略,显著提升控制精度与图像质量。
工作流程概览
- 输入处理:
- 文本描述 → CLIP编码
- 语义掩码 → 分解为多个二进制掩码 → 共享VAE编码
- 专家处理:
- 全局专家处理整体布局
- 局部专家细化各区域特征
- 动态融合:
- 动态门控网络生成加权系数
- 融合专家输出,形成语义嵌入
- 图像生成:
- 注入DiT主干
- 通过扩散过程逐步去噪,生成最终人脸图像
实验结果:全面领先现有方法
Face-MoGLE 在多个标准数据集上进行了系统评估,涵盖多模态、单模态与零样本场景。
1. 多模态人脸生成(MM-CelebA-HQ)
| 指标 | Face-MoGLE | SOTA基线 |
|---|---|---|
| FID ↓ | 22.24 | 26.81 |
| KID ↓ | 10.87 | 13.52 |
| CMMD ↓ | 0.477 | 0.531 |
| 掩码一致性 ↑ | 2.44 | 2.18 |
| 文本一致性 ↑ | 26.32 | 23.76 |
✅ 所有指标均优于当前最优方法,尤其在语义对齐方面优势明显。
2. 单模态任务表现
掩码到人脸(Mask-to-Face)
- FID: 19.63
- KID: 8.29
- CMMD: 0.399
文本到人脸(Text-to-Face)
- FID: 34.81
- KID: 21.85
- CMMD: 0.636
在两种单模态任务中均达到SOTA水平,表明框架具有良好的任务适应性。
3. 零样本泛化能力(MM-FFHQ-Female)
在未参与训练的新数据集上测试泛化性能:
| 指标 | 结果 |
|---|---|
| FID | 62.93 |
| KID | 31.27 |
| 掩码一致性 | 2.77 |
| 文本一致性 | 28.06 |
尽管数据分布偏移,Face-MoGLE 仍保持稳定输出,说明其语义解耦机制具备较强泛化能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











