“过去的 AI 是‘先看懂,再画出来’的两个步骤;现在的 UNI-1 是‘边想边画,画即是想’的一个过程。”
Luma AI 今日正式推出 UNI-1,这是业界首个将视觉理解与图像生成深度融合的统一推理模型。它不再仅仅是一个追求美学效果的绘图工具,而是一个能够执行复杂逻辑推理、处理多模态指令、并在生成过程中实时自我修正的“视觉智能体”。
- 官方介绍:https://lumalabs.ai/uni-1
UNI-1 的发布标志着 AI 视觉领域从“分离式流程”向“统一推理系统”的范式转移。Luma 明确表示,这不仅是图像生成的升级,更是其构建未来视频、语音智能体及交互式世界模拟器的基石。
核心突破:为什么“统一”如此重要?
传统的文生图模型(如 Midjourney v6, DALL-E 3)通常将“理解提示词”和“生成像素”视为两个相对独立的阶段,导致在处理复杂逻辑、空间关系或多轮修改时容易出现偏差。
UNI-1 通过以下两大核心机制打破了这一局限:
1. 🔄 结构化推理先行 (Reasoning-First Generation)
UNI-1 在生成像素之前及过程中,会执行深度的结构化推理:
- 指令分解:将复杂的自然语言指令拆解为空间、因果、时间和逻辑约束。
- 动态规划:在潜空间(Latent Space)中预先规划场景布局、物体关系和光影逻辑。
- 结果:在 RISEBench(基于推理的视觉编辑基准测试)中,UNI-1 取得了 SOTA(最先进)成绩,特别是在跨时间连续性、场景合理性和身份保留方面表现卓越。
2. 🎨 生成即理解 (Generation Enhances Understanding)
Luma 提出了一个反向增强的观点:训练模型去生成图像,能显著提升其细粒度的视觉理解能力。
- 通过生成过程,模型被迫深入理解物体的区域划分、遮挡关系和布局逻辑。
- 这使得 UNI-1 不仅能“画”,还能更精准地“看”和“改”,实现了理解与生成的良性闭环。
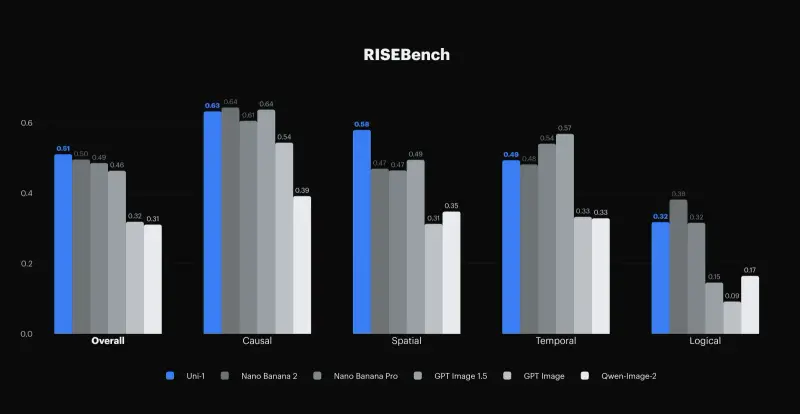
关键能力与应用场景
UNI-1 不仅仅用于生成单张精美图片,它专为复杂工作流而生:
| 核心能力 | 应用场景 | 价值点 |
|---|---|---|
| 🎬 多镜头故事板生成 | 电影预演、广告分镜 | 保持角色、场景和风格在多个镜头间的高度一致性。 |
| 🖼️ 基于参考的构图控制 | 产品设计、建筑可视化 | 精准控制物体位置、姿态和视角,拒绝“抽卡”式随机性。 |
| 🗣️ 多轮优化对话 | 创意迭代、细节打磨 | 支持“把左边的杯子换成红色的,并加上倒影”等复杂修改指令。 |
| 🎨 风格迁移与文化感知 | 营销素材、漫画创作 | 理解并复现特定的艺术风格、模因(Meme)或文化符号。 |
| 🌍 多语言提示支持 | 全球化内容创作 | 打破语言壁垒,直接用母语描述复杂视觉需求。 |
战略版图:Luma 的“全能智能体”野心
UNI-1 的发布并非孤立事件,而是 Luma 宏大战略的关键一环:
- 演进路径:从早期的 NeRF 场景重建 → 3D 资产生成 → Dream Machine 视频扩散 → 如今的 UNI-1 统一推理模型。
- 终极目标:构建能够理解物理世界、具备长期记忆、并能进行多模态交互(视频、语音、动作)的通用世界模拟器。
- 产品整合:UNI-1 已直接融入 Luma 的商业平台,支持从免费试用到企业级部署的全套服务,表明其已准备好承担生产级任务。
商业化与可用性
Luma 采取了务实的商业化策略,将 UNI-1 定位为生产力工具而非研究演示:
- 免费试用:提供初始额度供用户体验推理能力。
- 个人付费计划:面向创作者和自由职业者,提供更高的生成配额和高级功能。
- 企业选项:针对工作室和大团队,提供定制化工作流、API 接入及数据隐私保障。
从“绘图员”到“视觉导演”
UNI-1 的出现,意味着 AI 视觉模型正在从单纯的“绘图员”进化为具备逻辑思维的“视觉导演”。
它不再满足于生成一张“好看但经不起推敲”的图片,而是致力于理解你的意图、遵守你的约束、并在复杂的时空逻辑中创造出连贯的视觉叙事。对于电影制作人、游戏开发者、营销专家而言,这意味着可控性和逻辑性的极大提升。
Luma 已经铺好了通往“交互式世界模拟”的第一块砖。UNI-1 不仅是一个模型,它是未来 AI 智能体“眼睛”与“大脑”合一的雏形。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...