如果你是小说作者、播客主理人、广播剧创作者,或正在尝试将文字转化为有声内容,那么「配音成本高」「角色音色单一」「合成流程复杂」可能是你绕不开的障碍。

CosyVoice Desktop 是一个完全本地运行的桌面端有声内容生成工具,基于 CosyVoice3-0.5B 大模型构建,无需联网、无需订阅,打开即用,支持多角色配音、语音修补、跨语言合成,并提供完整的项目管理与音频导出流程。
为什么选择本地部署?
与云端 TTS 服务不同,CosyVoice Desktop 的所有推理均在你的电脑上完成:
- 无需上传文本,保障内容隐私
- 无 API 调用限制,可批量生成
- 支持自定义参考音频,实现角色音色复刻
- 断网也能用,适合敏感或离线创作场景
硬件要求:建议显存 ≥4GB(支持 CUDA 12.8,已适配 RTX 50 系显卡),亦可在 CPU 模式下运行(速度较慢)。
四种语音生成模式,覆盖多元创作需求
- 零样本复刻(Zero-shot Cloning)
仅需一段参考音频(3–10 秒),即可复刻其音色朗读任意文本。适合快速创建角色旁白。 - 精细控制(Fine-grained Control)
通过参考文本 + 参考音频 + 音素对齐,实现更精准的语调、停顿与情感控制,适合关键对白。 - 指令控制(Instruction-based)
用自然语言指令调整语音风格,例如:“用温和的语气朗读”“加快语速,表现紧张感”。 - 语音修补(Voice Inpainting)
对已有合成音频的某一段进行重生成(如修正发音错误、替换语气),无需重跑全文。
所有模式均支持中文、英文、日文、韩文及部分方言,跨语言合成能力持续优化中。
一站式工作台:从文本到成品音频
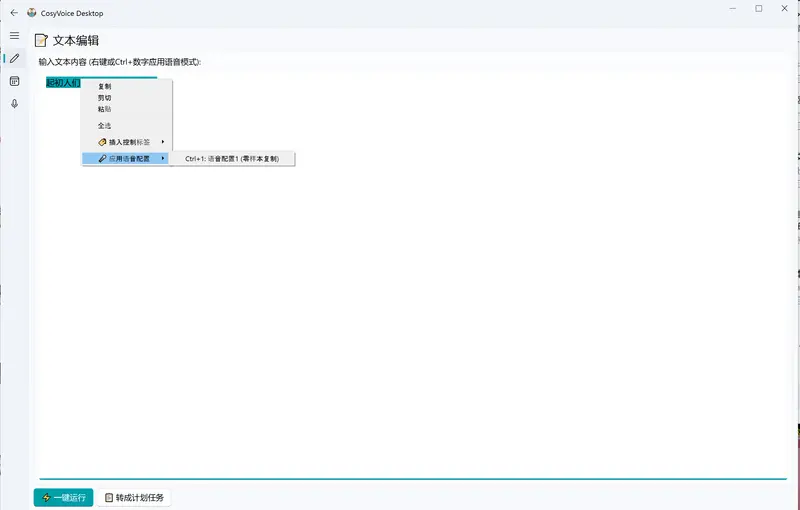
智能文本编辑器
- 支持标准编辑操作(复制/粘贴/撤销)
- 按段落绑定语音配置,不同角色以颜色标记区分(如红色=主角,蓝色=旁白)
- 生成后自动顺序播放各段音频,实时反馈效果
多角色语音管理
- 创建无限数量的角色配置,包含:模式、参考音频、参考文本、标记颜色
- 配置以 JSON 格式保存,可导入/导出,便于团队协作或跨项目复用
- 启动时自动加载上次配置,无需重复设置
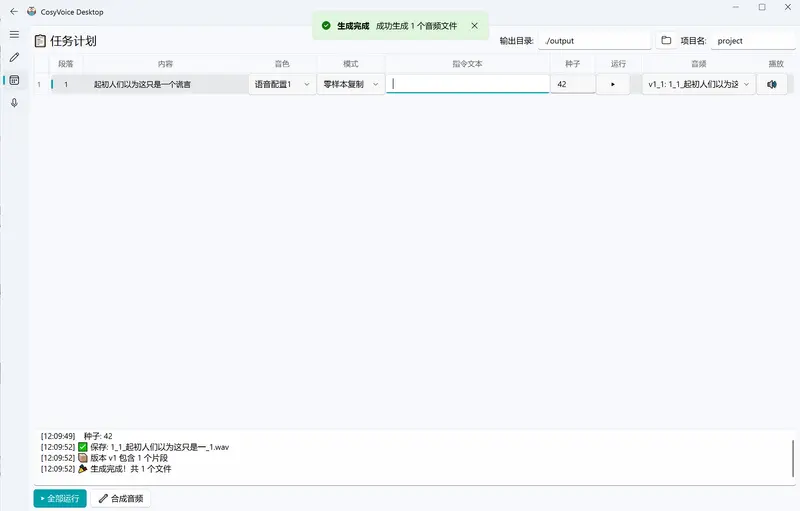
自动化输出与合成
- 音频自动保存至
output/{项目名}/ 目录,结构清晰 - 内置 FFmpeg(V1.2+),支持一键合并分段音频为完整文件
- 提供重 Roll 按钮:对不满意段落单独重新生成,不重跑全文
开箱即用,但保留灵活性
- 便携设计:解压即用,自带 Python 环境,不污染系统
- 模型按需下载:从 v1.3 起,程序本体不再捆绑模型。运行
download_all_models.bat 可选择从 HuggingFace 或 ModelScope 下载(后者对国内用户更友好) - 主题切换:支持浅色/深色/自动模式,适配不同工作环境
- 日志面板:实时显示生成进度、耗时、显存占用与警告信息,便于调试
常见问题与解决方案
- “No module named 'PIL'”
因便携环境中缺少 Pillow 库。解决方法:在程序根目录打开终端,执行
python_env\Scripts\pip.exe install Pillow --upgrade - 合成音频失败
V1.2 已内置 FFmpeg,通常无需额外配置。若仍失败,请确认系统环境变量中无冲突的旧版 FFmpeg。 - 语音失真或无声
请确保参考音频语言与待合成文本语言一致。例如:不能用日语参考音频生成中文语音(零样本模式下尤其敏感)。 - 模型加载失败
检查 pretrained_models/ 目录是否完整,显存是否充足(建议 ≥4GB)。
📦 版本演进:从可用到好用
- V1.0(2025.10.7):基础功能上线
- V1.1(2025.10.30):修复 Pillow 依赖问题
- V1.2(2025.12.14):升级 Torch 2.7 + CUDA 12.8,支持 RTX 50 系;新增设置页、配置记忆、自动输出目录
- V1.3(2025.12.16):升级至 CosyVoice3-0.5B,语音自然度与情感表达显著提升;提供语音修补模式;模型分离,未来将全面迁移至 GitHub 发布
项目计划逐步弃用百度网盘,所有版本将通过 GitHub 提供,提升下载稳定性和社区协作效率。
适合谁用?
- 网络小说作者:快速生成试听样章
- 独立播客制作人:低成本实现多角色对话
- 教育内容创作者:为课程脚本配音
- AI 语音爱好者:本地实验 TTS 模型效果


![CosyVoice Desktop:在你自己的电脑上,制作多角色有声小说的使用截图[1]](https://pic.sd114.wiki/wp-content/uploads/2025/12/1766590307-1766590307-CosyVoice-Desktop-2.webp)