NOFXNOFX是一个基于 DeepSeek/Qwen AI 的加密货币期货自动交易系统,支持 Binance、Hyperliquid和Aster DEX交易所,多AI模型实盘竞赛,具备完整的市场分析、AI决策、自我学习机制和专业的Web监控界面。
Music ArenaMusic Arena 通过提供一个标准化的人类偏好评估平台,为文本到音乐生成领域带来了新的评估方法和数据资源。它不仅解决了当前 TTM 领域中缺乏大规模、可再生人类偏好数据的问题,还通过透明的数据发布政策和音乐领域定制的功能,推动了该领域的研究和应用发展。
Windsurf EditorCodeium 团队推出全新的 AI 集成开发环境(IDE)—Windsurf Editor。这款编辑器结合了 Copilot 的协作智能和代理系统的自主能力,旨在帮助开发者更高效地开发产品,这款编辑器是基于VSC(Visual Studio Code)。
LocalSite AILocalSite AI 是一款功能强大且灵活的工具,适合希望快速生成网页代码的开发者、设计师以及需要原型设计的团队。无论您是使用本地模型还是云端服务,LocalSite AI 都能提供高效的解决方案,帮助您将创意变为现实。
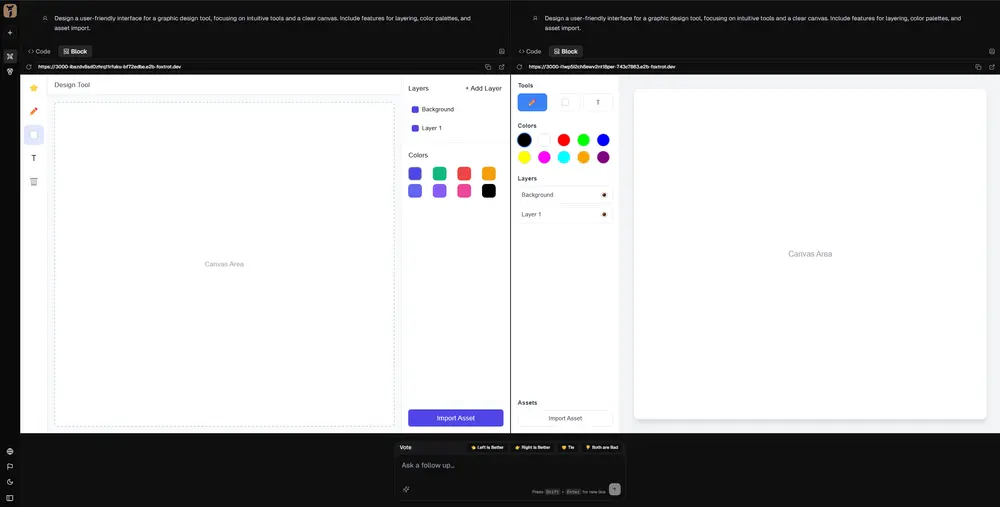
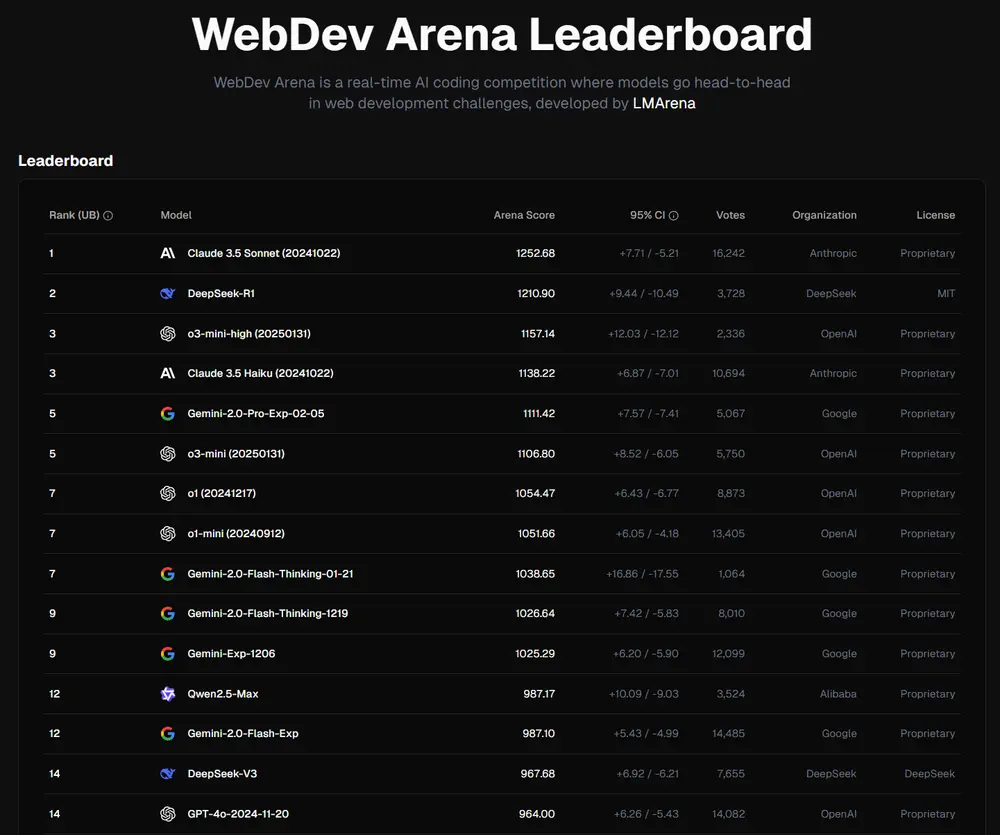
Code ArenaLMArena正式推出 Code Arena,一个面向 AI 编程模型的新型评估平台。与传统仅测试代码正确性或通过单元测试的基准不同,Code Arena 聚焦于完整软件开发周期,记录模型从需求理解到部署的全过程行为。
AITradeGameAITradeGame 是一个开源的 AI 交易模拟平台,支持 本地自托管 与 在线竞技 双模式,旨在为开发者、量化爱好者和 AI 研究者提供一个隐私优先、灵活可扩展的 AI 交易实验环境。
stagewiseStagewise 是一个浏览器工具栏,能够将您的前端用户界面连接到代码编辑器中的AI代理。这意味着您可以直接在网页上选择元素,AI代理会根据您的操作提供实时的代码修改建议,真正做到“指哪改哪”。