
LMArena
Chatbot Arena是一个开放平台,专注于通过人类偏好评估大型语言模型(LLMs)的性能。该平台由加州大学伯克利分校的SkyLab和LMSYS研究团队开发,旨在为LLMs提供一个公正、透明的评估环境。
当面对“某位科学家在2010年发表的论文是否引用了某项早期成果?”这类复杂问题时,人类通常会通过多轮搜索、交叉验证和逻辑推理来寻找答案。如今,大语言模型(LLM)结合搜索引擎的“深度研究代理”(Deep Research Agent)也正朝着这一能力迈进。
然而,如何公平、准确地评估这些系统的实际能力?当前主流基准如 BrowseComp 虽然推动了该领域发展,但其依赖实时网络搜索 API 的设计带来了两个根本性问题:
为解决这些问题,滑铁卢大学、CSIRO、卡内基梅隆大学与昆士兰大学的研究人员联合推出 BrowseComp-Plus ——一个固定语料库、人工验证、支持解耦分析的新一代深度研究评估基准。

它不仅提升了评估的公平性与透明度,更使我们能够深入探究:究竟是检索器更强,还是模型更会推理?
现有的深度研究代理通常由两部分组成:
在 BrowseComp 等原始基准中,代理直接访问实时搜索引擎(如 Google),这看似贴近真实场景,但也带来严重问题:
换句话说:我们评估的不是一个系统的稳定能力,而是一次“网络冲浪”的临时结果。
BrowseComp-Plus 的目标就是打破这种不确定性。
BrowseComp-Plus 基于原始 BrowseComp 的 830 个复杂查询构建,每个问题平均需要超过 2 小时人工才能解答。针对这些问题,研究团队构建了一个包含约 10 万个网页文档的静态语料库,满足三个关键标准:
| 标准 | 说明 |
|---|---|
| 全面覆盖 | 每个问题所需的所有证据文档均被收录,确保理论上可解 |
| 有效区分 | 包含大量语义相似但误导性的负样本,能区分强弱系统 |
| 实用规模 | 10 万文档足够大以支持可靠分析,又不至于难以部署 |
为确保语料质量,研究团队采用自动化+人工验证的两阶段方法:
例如,一个问题询问“某作者发表了多少篇论文”,答案是“7”。虽然其个人主页列出全部论文但未写总数,该页面仍被视为金标准文档。
为了测试代理的抗干扰能力,团队还系统性地构建了困难负样本:
这些负样本显著增加了检索难度,有效防止“靠关键词匹配蒙对”的情况。
BrowseComp-Plus 不只是一个“答对多少题”的打分工具,它支持多维度、可解耦的评估:
| 指标 | 含义 |
|---|---|
| 准确率 | 由 GPT-4.1 判断回答是否正确 |
| 召回率 | 代理在搜索过程中检索到的证据文档占比 |
| 搜索调用次数 | 发起的搜索请求数量,反映效率 |
| 校准误差 | 模型自信程度与实际准确率的偏差 |
此外,还可进行仅检索器评估,使用标准信息检索指标:
这使得我们可以独立分析检索器性能,而不受模型推理能力的影响。
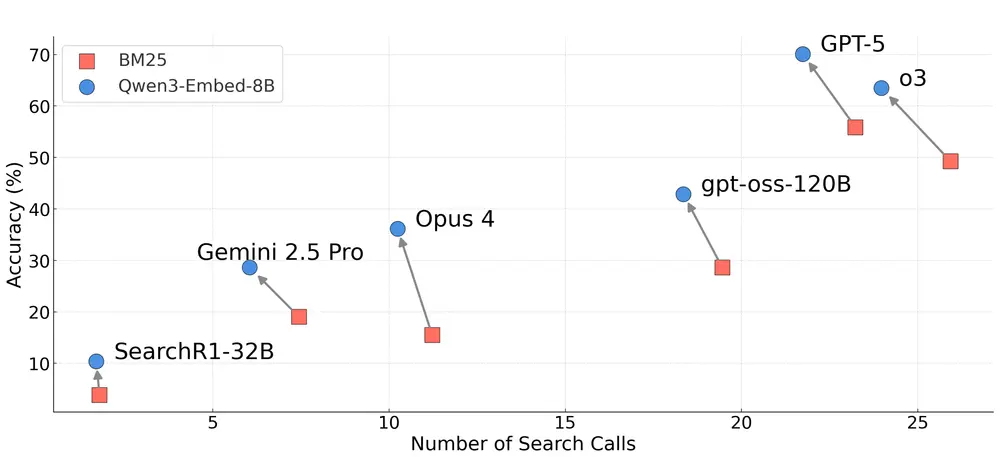
实验表明,使用 Qwen3-Embedding-8B 替代传统 BM25 检索器后:
这意味着:高质量检索不仅能提高准确性,还能降低推理成本——因为模型不需要反复搜索来弥补初始结果的不足。
研究发现,闭源模型(如 GPT-5、o3)倾向于频繁调用搜索工具,平均每查询超过 20 次;而开源模型(如 Qwen3-32B、SearchR1-32B)即便被明确提示使用工具,也极少调用(<2 次)。
这种“高频率搜索+强推理”组合可能是闭源系统表现更好的原因之一。但也引发思考:是否过度依赖搜索?是否存在更高效的推理路径?
通过分析 OpenAI 的 OSS 系列(低/中/高推理模式),研究发现:
说明:深度推理本身具有独立价值,不能完全被更多搜索替代。
即使当前最强的检索器 Qwen3-Embedding-8B,在 nDCG@10 上也仅得 20.3 分(满分100),远未达到理想水平。
进一步分析显示:
这表明:检索技术仍是制约深度研究系统上限的关键瓶颈。

BrowseComp-Plus 的推出,标志着深度研究代理评估正从“黑箱测试”走向“白盒分析”。
它的价值不仅在于提供一个新基准,更在于支持以下研究方向:
未来,随着更多可控基准的出现,我们将能更精准地衡量 AI 的“研究能力”——不是看它能不能找到答案,而是看它如何找到答案。













