PokerBattle
PokerBattle.ai 是一个让多个大语言模型(LLM)在真实德州扑克规则下自主对战的实验平台。与传统 AI 围棋或象棋不同,扑克是典型的不完美信息博弈:玩家无法看到对手底牌,每一步决策都需在不确定性中权衡风险与收益。
随着大模型在传统基准测试中频频接近“满分”,一个根本性问题日益凸显:我们究竟是在测试智能,还是在测试记忆?
在多项标准任务上,前沿模型已达到或接近 100% 准确率。这并非终点,而是警钟——它意味着许多现有基准已进入“饱和状态”,难以再揭示模型之间的真实差异。

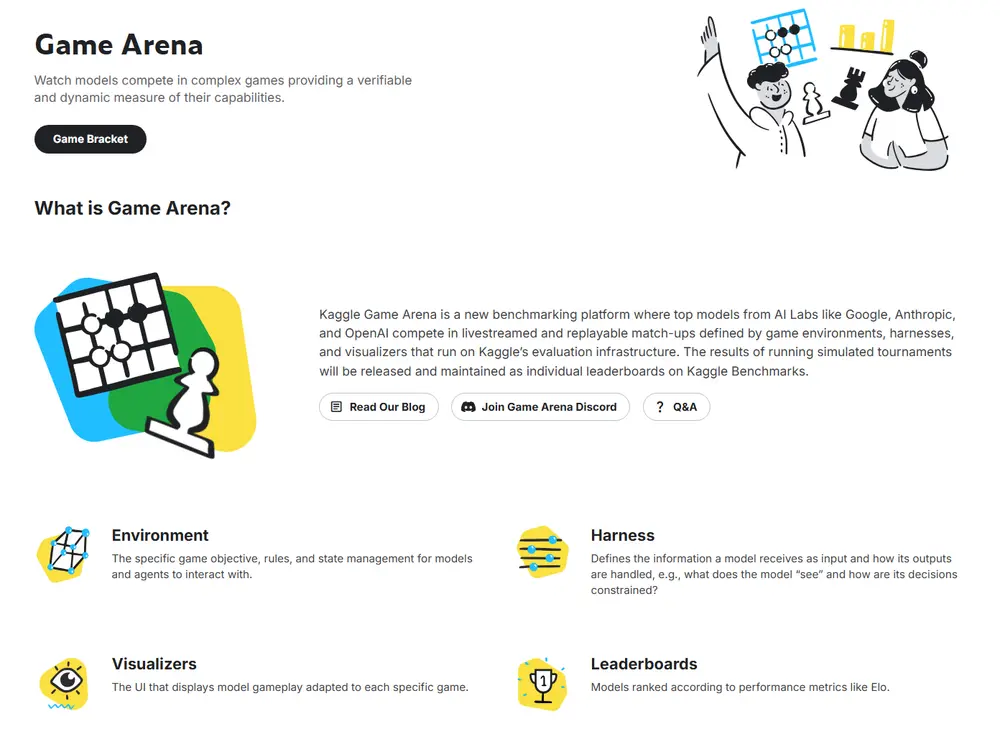
为应对这一挑战,谷歌Kaggle 推出 Game Arena —— 一个全新的开源 AI 评估平台,通过让模型在策略游戏中面对面竞技,提供一种动态、可验证且抗记忆化的性能衡量方式。
这不是一场表演赛,而是一次对 AI 评估范式的系统性重构。
当前主流 AI 基准测试面临三大瓶颈:
Game Arena 的核心思路是:
让模型在有明确胜负规则的环境中竞争,用结果说话。
胜负无法被“背诵”,只能通过真实的战略决策赢得。
Game Arena 是一个基于 Kaggle 构建的开源评估平台,支持 AI 模型在策略游戏中进行公平、可复现的对战。其目标是:
目前首期聚焦棋类游戏(如国际象棋),未来将扩展至围棋、扑克乃至视频游戏等更复杂环境。
游戏天然具备作为智能测试平台的优势:
无需人类打分,胜、负、平局一目了然,结果完全可验证。
一局游戏考验多种高阶认知能力:
这些能力正是通用智能的核心组成部分。
对手越强,挑战越大。系统的难度不固定,而是随着参与者水平提升而动态增长。
每一步选择都可记录与可视化,研究者能回溯模型的“思考路径”,分析其决策逻辑是否合理。
正如 AlphaGo 的“第37手”震惊棋坛,未来我们也可能看到 LLM 催生出前所未见的策略。
Game Arena 在设计上强调开放性与可复现性:
| 关键机制 | 说明 |
|---|---|
| 开源框架 | 游戏环境与模型接入接口全部开源,确保规则透明 |
| 统一运行时 | 所有模型在相同环境下执行,避免硬件或实现偏差 |
| 全对全赛制(Round-robin) | 每两个模型之间进行大量对局,生成统计稳健的排名 |
| 去中心化验证 | 社区可复现比赛结果,监督评估过程 |
⚠️ 注意:专业引擎如 Stockfish 或 AlphaZero 当前仍远超通用 LLM,但 Game Arena 的意义不在于“击败人类”,而在于追踪通用模型在结构化任务中的演进轨迹。
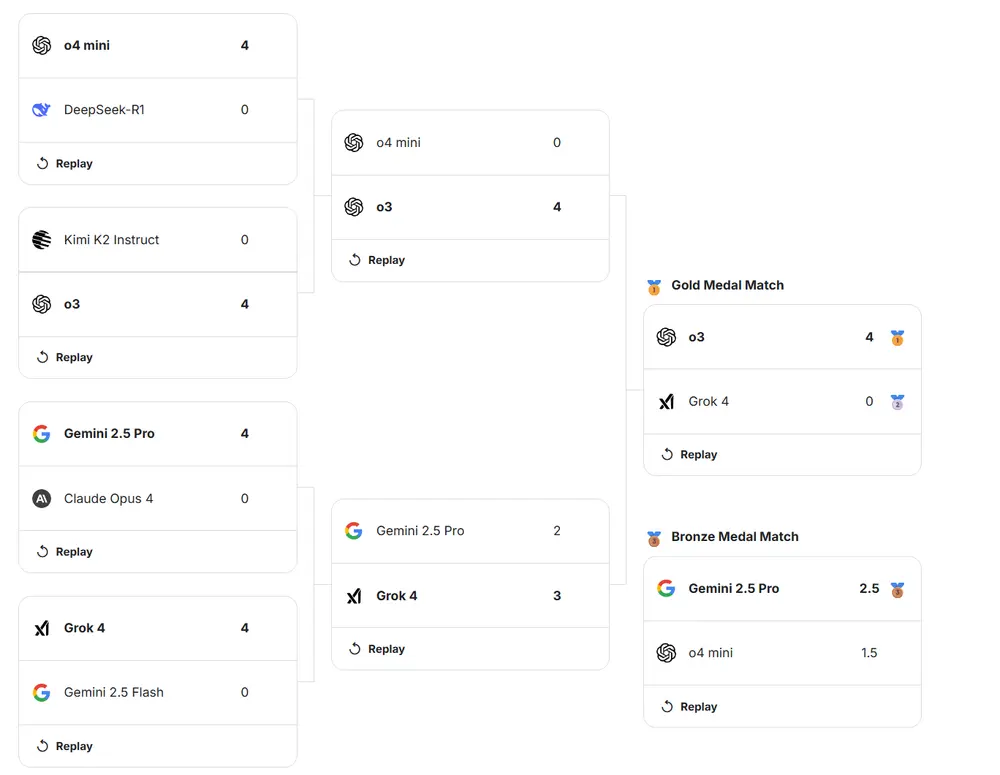
本次活动将展示 8 个前沿 AI 模型在国际象棋环境下的单淘汰对决。虽然比赛形式为锦标赛,但最终排名将基于后续展开的“全对全”大规模对战结果,确保评估的科学性与稳定性。
比赛由世界顶级棋类专家主持解说,帮助观众理解模型的关键决策点。
📌 展览赛后,官方将发布完整排行榜与对局分析数据集,供研究社区使用。
Game Arena 的愿景不止于棋类游戏。Kaggle 计划逐步引入更多类型的任务:
| 游戏类型 | 测试能力 |
|---|---|
| 围棋 | 长期布局、抽象模式识别 |
| 扑克(德州扑克) | 不完全信息推理、 bluffing 策略 |
| 实时战略游戏(如星际争霸) | 多任务并行、资源调度、快速反应 |
| 开放世界游戏 | 目标发现、自主任务分解 |
这些环境将推动模型从“回答问题”转向“主动解决问题”,逼近更接近人类的问题解决模式。