NOFX
NOFX是一个基于 DeepSeek/Qwen AI 的加密货币期货自动交易系统,支持 Binance、Hyperliquid和Aster DEX交易所,多AI模型实盘竞赛,具备完整的市场分析、AI决策、自我学习机制和专业的Web监控界面。
LoCoDiff 不只是一个性能榜单,更是对当前长上下文模型能力边界的诚实检验。它揭示了一个事实:即使模型宣称支持百万 token 上下文,也不意味着能在实际任务中有效利用这些信息。尤其是在需要持续状态跟踪的场景中,记忆衰减、注意力分散等问题依然严峻。
AbanteAI 推出了一项新的长上下文评估基准——LoCoDiff,专为衡量大模型在真实代码演化场景下的上下文处理能力而设计。

不同于依赖人工构造或填充文本的测试方式,LoCoDiff 直接从真实 Git 提交历史中提取数据,要求模型根据完整的变更记录,推理出目标文件的最终状态。这一任务模拟了开发者在阅读代码历史、理解重构过程或解决合并冲突时的实际挑战。
当前许多长上下文能力的评估,往往基于合成数据或简单问答任务,难以反映模型在复杂软件工程任务中的真实表现。LoCoDiff 的设计目标是:
git log 输出,输出为具体代码文件,匹配精度可通过字符串完全比对判断。值得一提的是,LoCoDiff 的全部代码、提示生成、实验运行、网站搭建及 GitHub 页面部署,均由 AbanteAI 开发的编码智能体 Mentat 独立完成。这本身也验证了该基准对自动化开发流程的支持能力。
我们在多个主流大模型上运行了 LoCoDiff 基准测试,涵盖不同架构、推理模式与上下文长度(从几千到数万 token),得出以下关键结论:
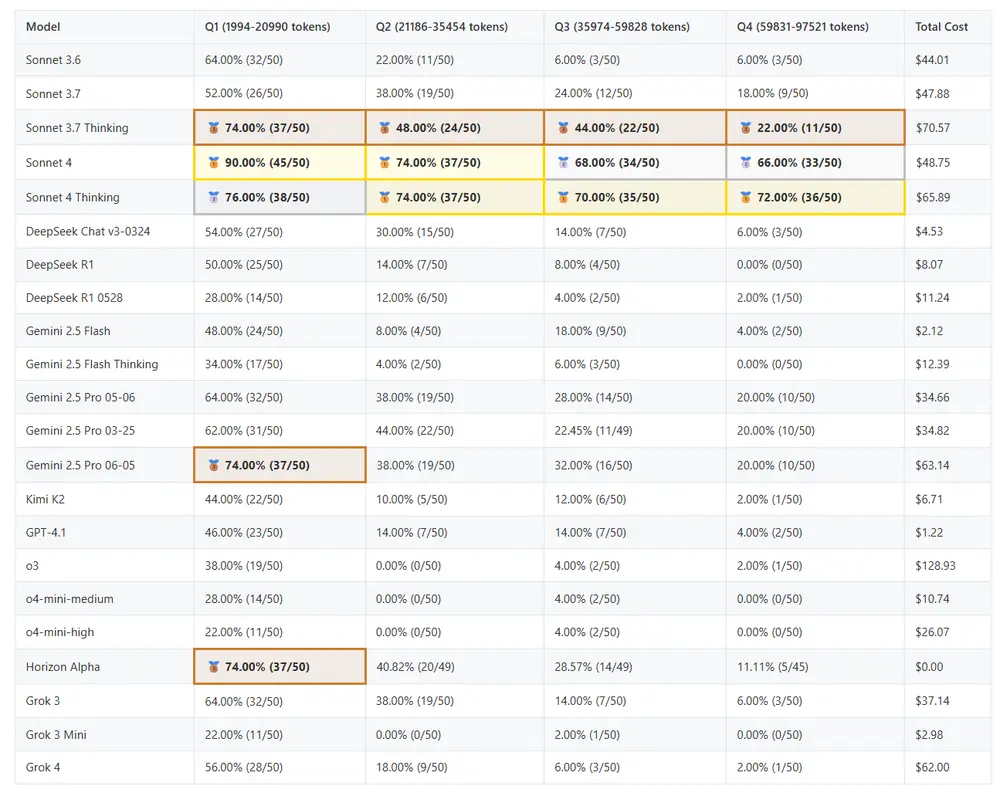
我们最初设想用此基准探索百万级上下文窗口的潜力,但现实是:现有模型连 25k 的有效利用都尚未达标。
在所有测试语言(Python、Zig、TypeScript、Rust、JavaScript)和上下文长度下,Claude 3.7 Sonnet Thinking 均取得最佳成绩。
尤其在长上下文场景中,它展现出更强的状态追踪能力——能够准确识别分支变更、合并冲突及其解决方案。这种能力正是优秀编码代理的关键特质。
令人意外的是,在本任务中,“推理优先”模型并未体现出优势:
唯一例外是 Claude 3.7 Sonnet Thinking,其推理版本显著优于非推理版本。这表明:并非所有推理机制都能有效分配计算资源,而 Sonnet 3.7 显然找到了更适合此类任务的策略。
每个测试用例的输入基于标准 Git 日志命令生成:
git log -p --cc --reverse --topo-order -- path/to/file
各参数含义如下:
-p:显示每次提交的具体代码差异;--cc:展示合并提交相对于各父节点的双差异(diff against both parents);--reverse:按时间正序排列(从最早到最新);--topo-order:保证拓扑排序,父提交先于子提交出现。这种方式确保模型接收到的是结构清晰、顺序合理的历史流,最大限度减少解析歧义。
基准包含 200 个文件,均匀分布于 5 个开源项目:
| 项目 | 语言 | 特点 |
|---|---|---|
| Aider | Python | AI 编程工具 |
| Ghostty | Zig | 高性能终端模拟器 |
| tldraw | TypeScript | 实时绘图应用 |
| Qdrant | Rust | 向量数据库 |
| React | JavaScript | 前端框架 |
筛选条件:
一个典型的 50k token 提示可能涵盖 50–150 次提交,涉及多分支演进与复杂合并逻辑,最终要求模型还原完整的最新代码。
所有测试用例、预期输出及模型响应均已开源,可供复现与分析。