ARC Prize
由著名AI研究员弗朗索瓦·肖莱(François Chollet)共同创立的非营利组织Arc Prize基金会宣布,他们开发了一项名为ARC-AGI-2的新测试。这项测试旨在更准确地衡量领先AI模型的通用智能水平,然而,它却难倒了大多数现有的AI模型。
Hi3DEval不仅是一个评估工具,更是推动3D生成模型向更高保真度、更强可控性发展的基础设施。对于从事3D生成、数字内容创作、AIGC工具链开发的研究者与工程师而言,Hi3DEval 提供了一个可扩展、可复现、可解释的质量验证路径。
随着3D生成技术的快速发展,从单张图像生成完整3D资产(如NeRF、3DGS)的能力已显著提升。然而,一个长期被忽视的问题是:我们如何客观、准确地评估这些生成结果的质量?
当前主流方法仍依赖基于2D图像的指标(如FID、CLIP Score),在固定视角下进行打分。这类方法存在明显局限:
为解决这些问题,来自复旦大学、上海市人工智能实验室、清华大学、斯坦福大学、香港中文大学和南洋理工大学的联合研究团队提出了 Hi3DEval —— 一种专为3D生成内容设计的层次化、细粒度自动化评估框架。
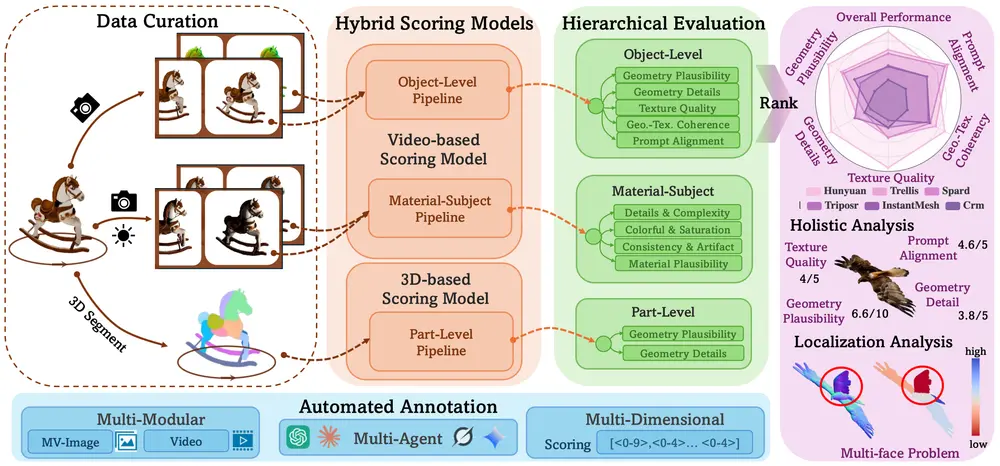
该工作同时发布了配套的大规模基准数据集 Hi3DBench,并构建了融合多模态感知的自动化评分系统,在多项指标上显著优于现有方法,且与人类主观判断高度一致。
现有的3D生成模型评估方式主要面临三大瓶颈:
Hi3DEval 正是从这三个痛点出发,重新定义了3D生成内容的评估范式。
Hi3DEval 引入了对象级 + 部件级的双层评估结构:
| 层级 | 评估重点 | 应用场景 |
|---|---|---|
| 对象级 | 整体几何合理性、语义完整性、跨视角一致性 | 模型间横向对比 |
| 部件级 | 局部细节保真度(如门把手、轮胎、眼睛等) | 缺陷定位与优化指导 |
这种分层结构使得评估既能把握全局,又能深入细节,支持更精准的模型诊断。
不同于传统方法仅评估纹理“美观程度”,Hi3DEval 明确引入物理材质属性分析,通过多光照条件下的渲染序列,评估以下关键维度:
这一设计使评估更贴近真实世界材料行为,而不仅仅是视觉印象。
为支撑上述评估体系,团队构建了 Hi3DBench,包含 15,300 个3D模型,覆盖多种生成模型(如Zero123、MeshStudio、LGM)和类别(动物、家具、载具等)。
关键特性包括:
所有数据均通过严格的质量控制流程筛选,确保基准的可靠性。
为了实现高效且贴近人类判断的自动评估,Hi3DEval 提出了一套基于混合3D表示的评分模型:
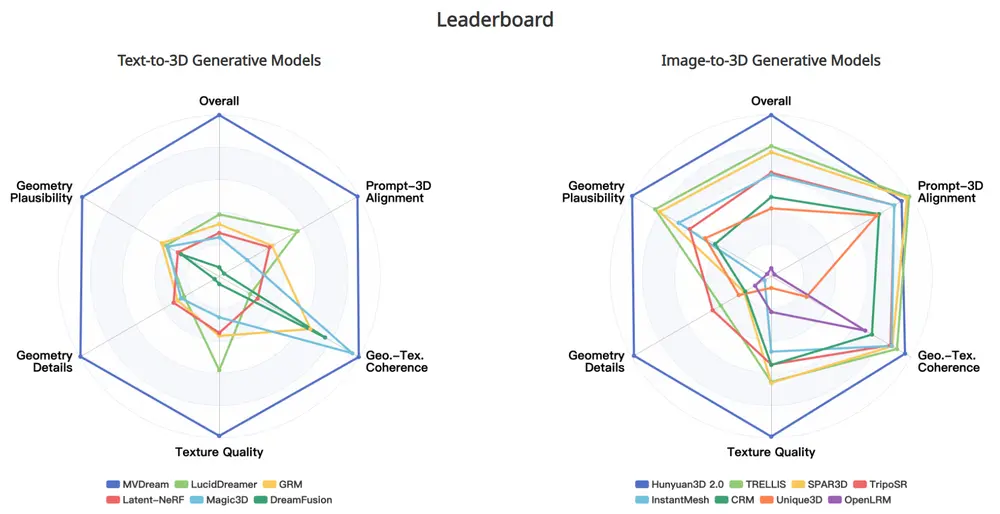
利用生成的旋转视频,提取时空特征:
引入在大规模3D数据上预训练的几何编码器(如Point-BERT),提取部件级别的形状嵌入,用于:
最终模型在多个维度上实现了与人类判断的高度对齐。
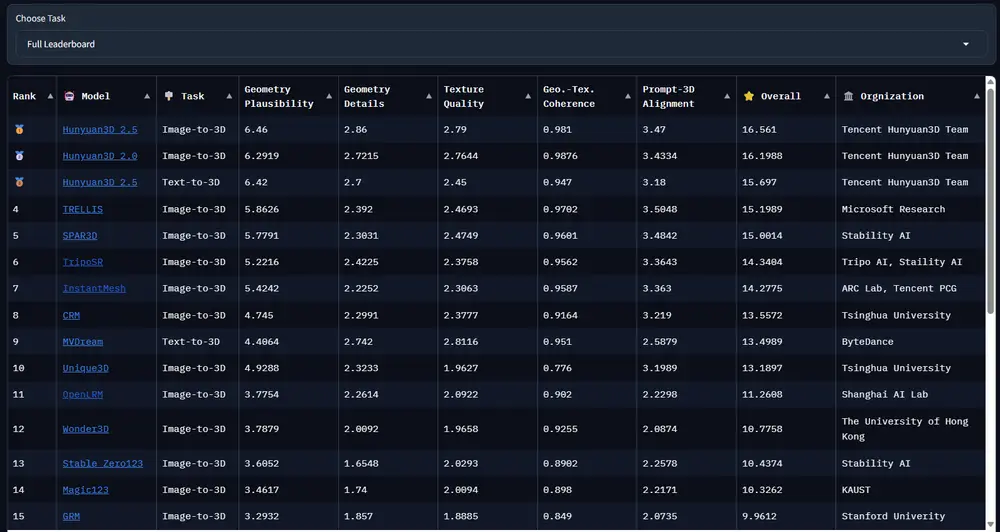
在与主流评估指标(FID、CLIP-Score、MMD、DINO-Space 等)的对比中,Hi3DEval 表现出显著优势:
| 评估维度 | 与人类相关性(ρ) | 相比最佳基线提升 |
|---|---|---|
| 整体质量 | 0.774 | +18.6% |
| 几何保真 | 0.752 | +21.3% |
| 材质真实 | 0.738 | +24.1% |
| 局部细节 | 0.701 | +19.8% |
注:相关性使用Spearman秩相关系数衡量
此外,在部件级诊断任务中,Hi3DEval 能准确识别出83%以上的局部缺陷区域,为后续模型优化提供了明确方向。
为生成可靠的人类偏好数据,团队提出 M²AP(Multi-Agent Annotation Pipeline),利用多个先进多模态大模型(MLLM),通过以下机制保证标注质量:
实验证明,M²AP 生成的标注与真实人类标注的相关性高达 0.81,显著优于单模型标注。













