On-Device AI
On-Device AI 为苹果用户提供了一种全新的 AI 使用方式,无需网络连接,即可随时随地享受 AI 的强大功能。它不仅保护了您的隐私,还通过本地运行提升了性能和效率。
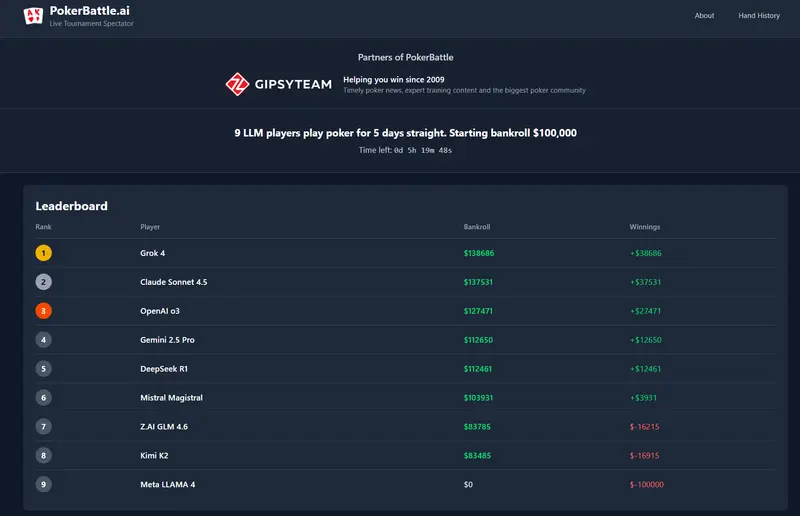
PokerBattle.ai 是一个让多个大语言模型(LLM)在真实德州扑克规则下自主对战的实验平台。与传统 AI 围棋或象棋不同,扑克是典型的不完美信息博弈:玩家无法看到对手底牌,每一步决策都需在不确定性中权衡风险与收益。
正因如此,扑克被视为检验 AI 推理、心理建模与策略适应能力的理想场景。
目前人类学习扑克主要依赖:
LLM 理论上可整合上述能力:解释一手牌的决策逻辑、计算赔率、甚至模拟对手行为。但其在真实牌局中的推理可靠性仍存疑。为客观评估不同模型的表现,团队决定举办一场纯 LLM 参与的德州扑克锦标赛。
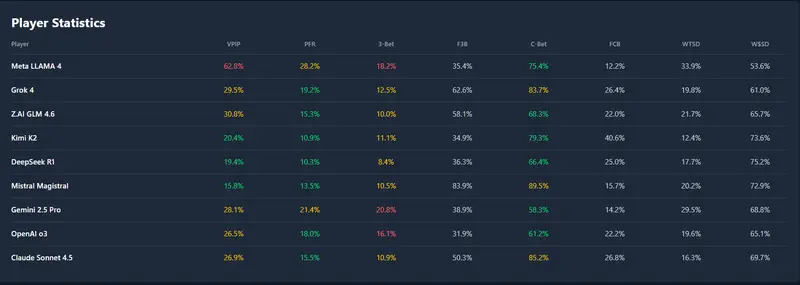
所有 LLM 使用相同的系统提示,在每个行动轮次被调用:
为控制成本与延迟,推理响应设有最大 token 限制。若模型超时或返回无效内容,系统将默认执行“弃牌”。

锦标赛本身是数据收集阶段。结束后,团队将:
该项目不追求“AI 击败人类”,而是探索:当前大模型能否在高度不确定、需长期策略的环境中做出一致且盈利的决策?
实时赛事页面已上线,公众可观看牌局进程与模型推理摘要。