
HumaneBench
HumaneBench基于以下核心原则构建:科技应尊重用户注意力为有限珍贵资源;通过有意义选择赋能用户;增强而非取代人类能力;保护人类尊严、隐私与安全;培育健康人际关系;优先考虑长期福祉;保持透明诚实;以及设计促进公平包容。
在 AI 领域,硬件常是聚光灯下的主角,但真正决定落地效果的,往往是软件栈——从驱动、内核到推理框架和调度策略。然而,大多数基准测试仍聚焦于芯片本身,忽视了软件演进对实际性能的持续影响。
为填补这一空白,SemiAnalysis 推出了开源项目 InferenceMax(Apache 2.0 许可),一个每晚自动运行的 AI 推理基准测试套件,专门衡量真实世界推理场景中软硬件组合的效率,并以 总拥有成本(TCO) 为核心指标。
当前主流基准测试多为“快照式”——在某一时间点测试固定版本,无法反映软件每日迭代带来的性能变化。而 InferenceMax 采用滚动发布模式,每晚使用最新版推理框架(如 vLLM、SGLang、TensorRT-LLM 等)和驱动,持续追踪性能演进。
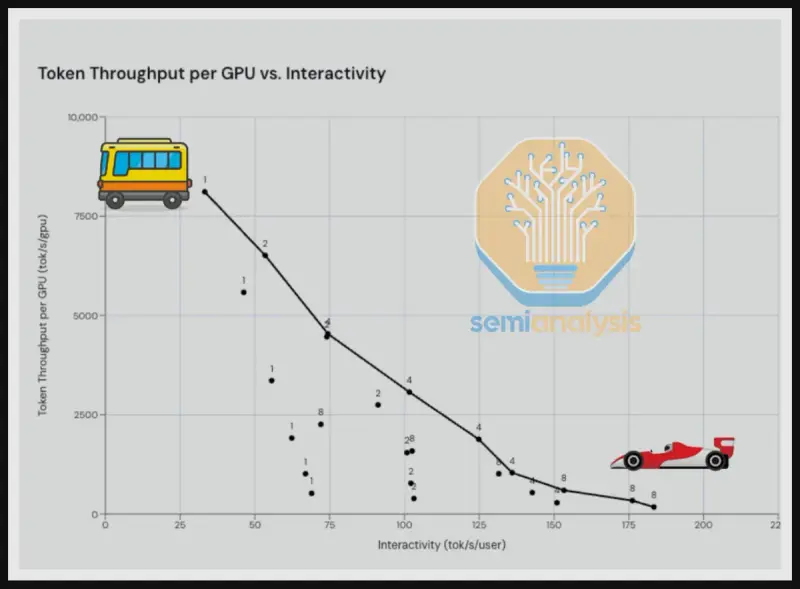
更重要的是,它不只看“每秒生成多少 token”,而是回答一个更关键的问题:每百万 token 花多少钱?
InferenceMax 关注两个关键维度:
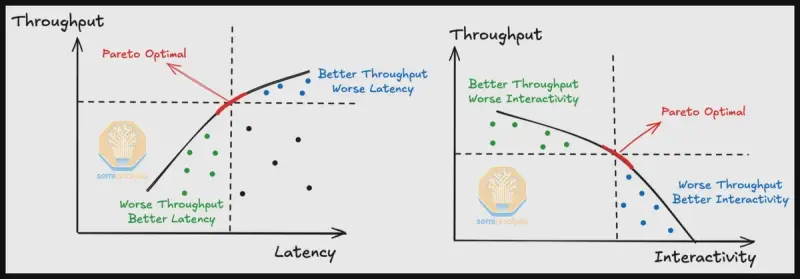
二者存在天然权衡:高吞吐常导致响应“卡顿”,高交互性则牺牲整体效率。理想配置位于 Pareto 前沿——在给定成本下,找到吞吐与交互的最佳平衡点。
而最终决策依据是 TCO(Total Cost of Ownership),即:
每百万 token 的美元成本
=(GPU 购置/租赁成本 + 电力 + 运维) ÷ 生成的 token 总量
这意味着,最快的 GPU 不一定最划算。例如,InferenceMax 数据显示,AMD 的 MI355X 在某些场景下的 TCO 可与 Nvidia 的 B200 相当,尽管后者峰值性能更高。
目前 InferenceMax 1.0 支持:
未来数月将加入 Google TPU 和 AWS Trainium。
基准测试在 GitHub Actions 上每晚自动运行,使用厂商提供的“真实世界配置”——因为同一硬件可通过数千种参数组合调优,仅测默认设置无实际意义。
InferenceMax 已促成多项实际优化:
项目团队感谢 英伟达、AMD 及多家云厂商的工程师深度协作,部分人员甚至通宵调试。这反映出 AI 软件栈仍处高速迭代期,基准测试本身已成为推动生态成熟的重要工具。
对于任何部署 LLM 推理服务的团队,InferenceMax 提供了一个动态、真实、成本导向的评估视角。













