
Game Arena
Kaggle游戏竞技场(Game Arena)是一个全新的基准测试平台,来自谷歌、Anthropic和OpenAI等AI实验室的顶尖模型在这个平台上,通过游戏环境、控制台和可视化工具在Kaggle的评估基础设施上运行的直播和可重放的比赛中进行竞争。模拟比赛的结果将作为Kaggle基准测试中的个人排行榜发布和维护。
SciArena是一个开放且协作的平台,直接吸引科学界参与评估科学文献任务中的基础模型。这种基于众包的、面对面的语言模型评估方法已在通用领域由类似 Chatbot Arena 的平台成功开创。
近日,AI2(艾伦人工智能研究所)推出了 SciArena —— 一个用于评估基础模型在科学文献相关任务中表现的开放平台。该平台采用众包式评估机制,旨在推动 AI 在科研领域的应用向更准确、可靠的方向发展。
随着科学研究产出的快速增长,研究人员越来越难以及时跟进最新成果并有效整合知识。在此背景下,大型语言模型(LLM)被广泛用于辅助科学探索,但如何客观评估它们在复杂、专业性强的科学任务中的表现,仍是一个重大挑战。
传统基准测试存在明显局限:
为此,AI2 推出了 SciArena,借助社区参与的方式,构建一个动态、开放、面向未来的科学模型评估体系。
SciArena 是一个开源、协作式的评估平台,专注于评估基础模型在科学文献理解与推理方面的表现。其核心理念借鉴自 Chatbot Arena 等用户驱动的模型比较平台,但针对科学任务进行了深度定制。
平台包含三大核心组件:
用户可以提交科学问题,平台自动检索相关论文并让两个模型生成答案。用户对比输出后投票选择更优回答。
基于社区投票数据,使用 Elo 评分系统对模型进行动态排名,实时反映模型能力变化。
基于人类偏好数据构建的自动化评估基准,用于衡量模型是否能准确预测人类判断,是检验评估系统可靠性的重要工具。
SciArena 的运作流程高度依赖高质量的科学文献检索与标准化的答案呈现机制:
整个流程确保了评估的公平性和可重复性。
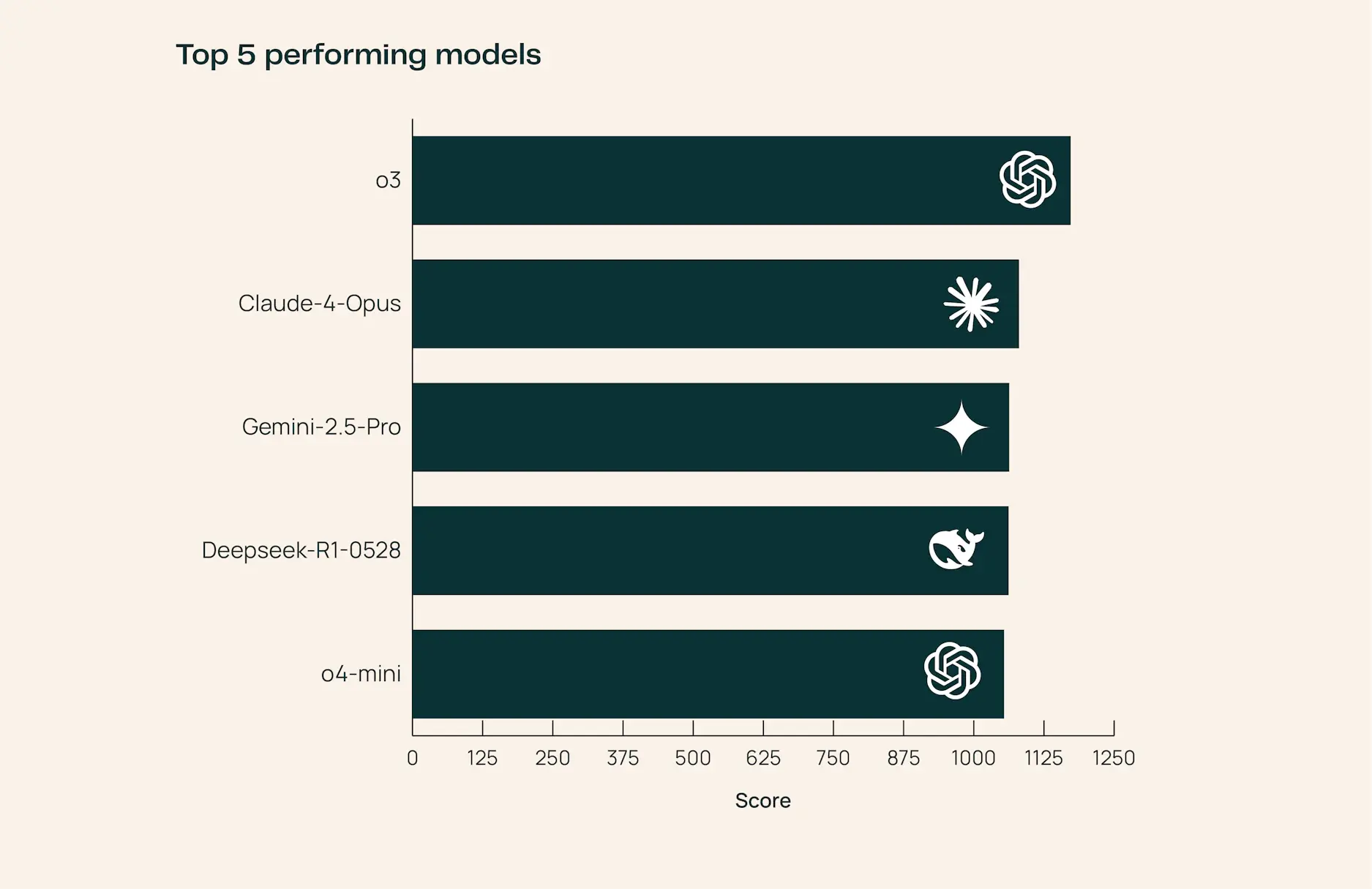
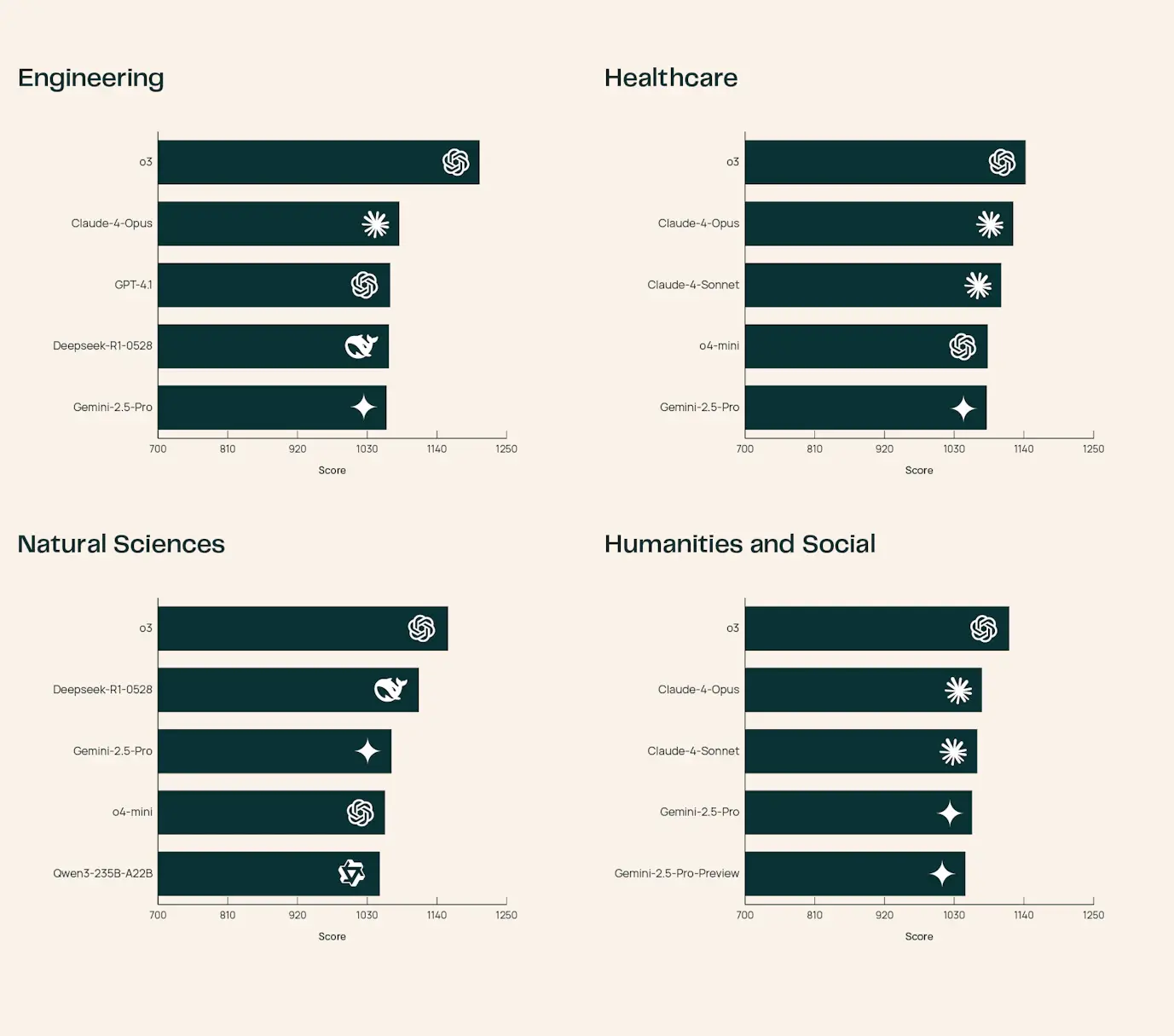
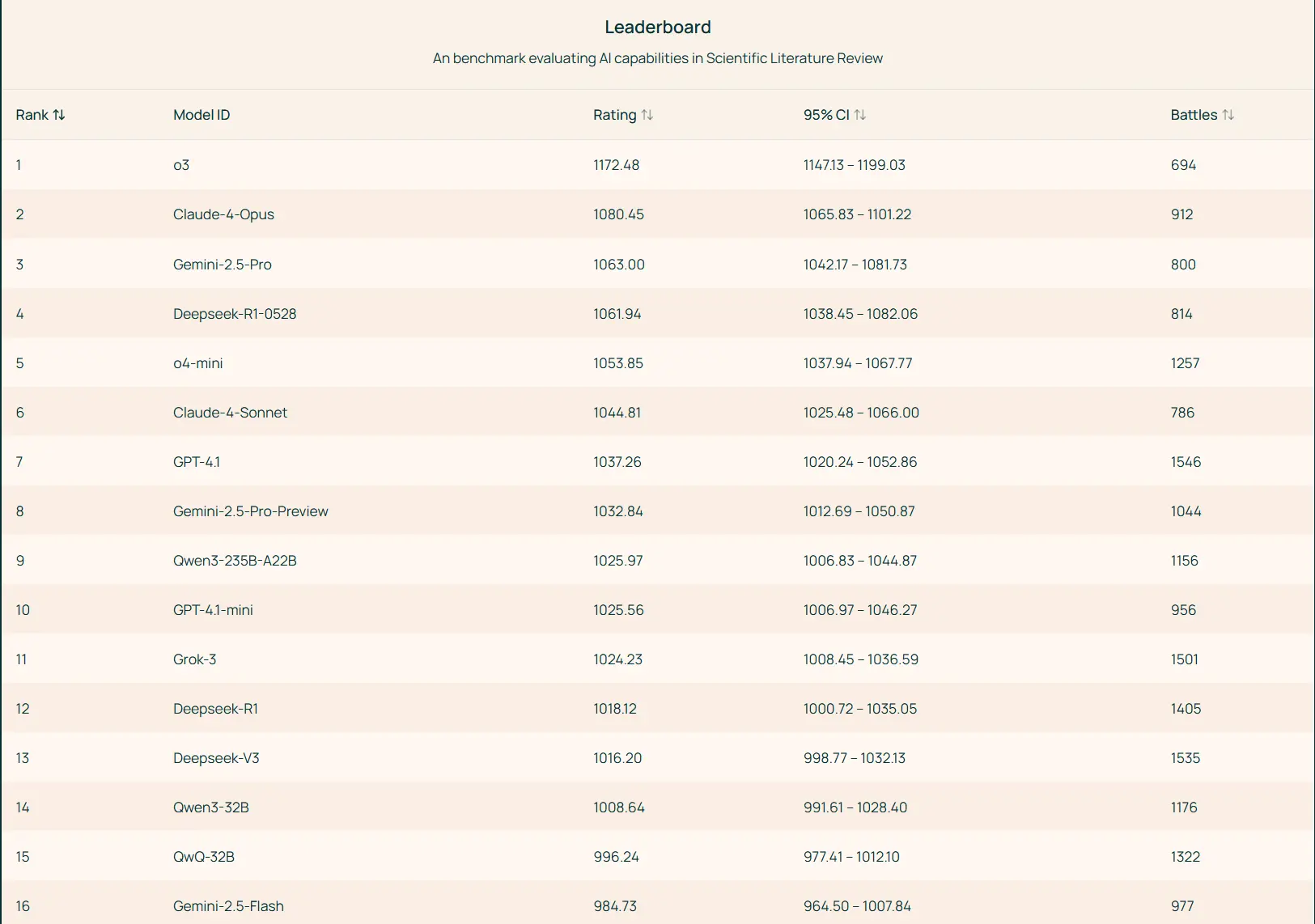
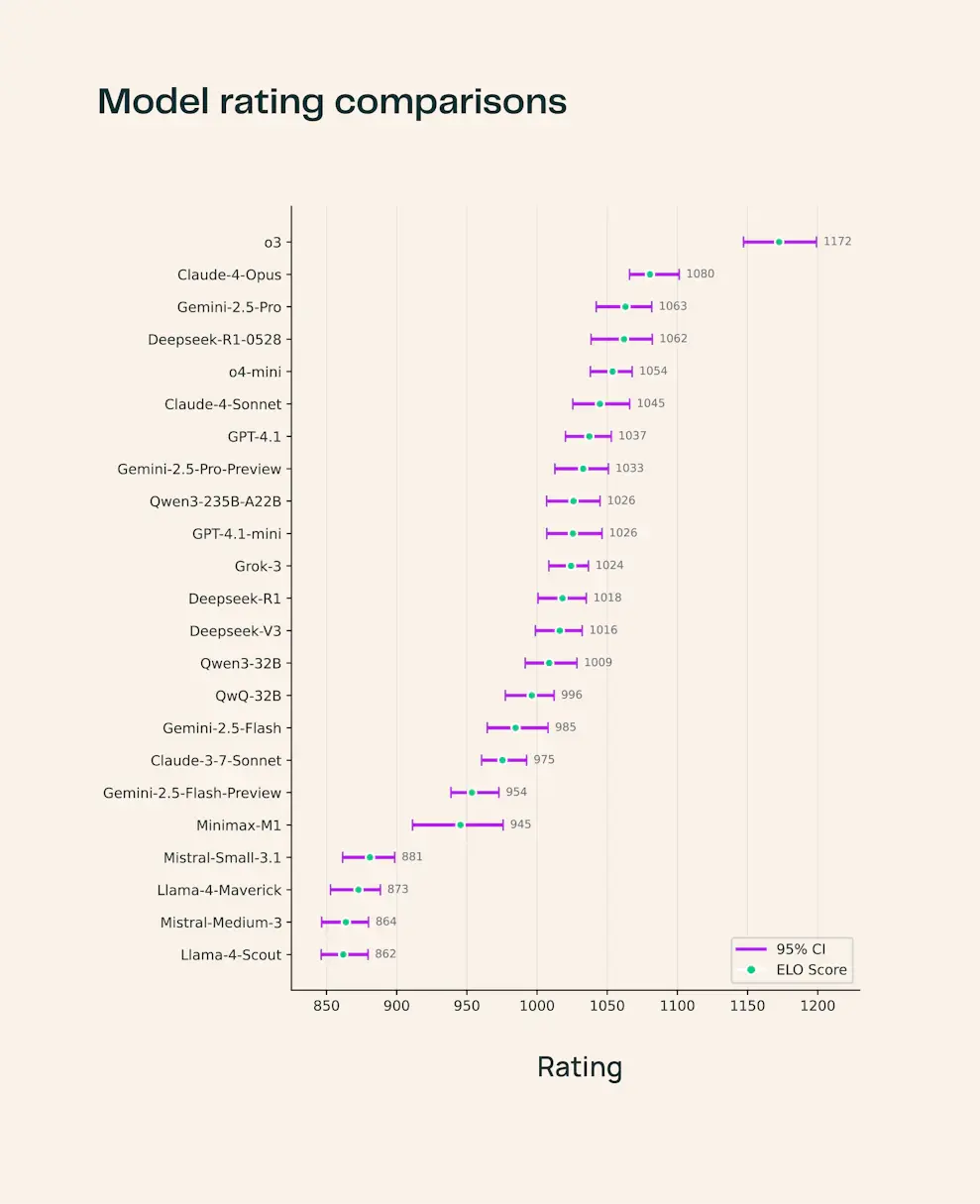
目前 SciArena 已集成 23 个前沿基础模型,涵盖当前主流闭源和开源方案。以下是主要发现:
| 模型 | 表现亮点 |
|---|---|
| o3 | 综合表现最佳,在工程领域尤为突出,生成的回答技术性强且引用详尽 |
| Claude-4-Opus | 医疗健康领域领先,擅长处理临床和生物医学相关内容 |
| DeepSeek-R1-0528 | 自然科学领域表现出色,尤其在物理、化学等基础学科中优势明显 |
值得注意的是,即便是最强模型 o3,在预测人类偏好的 SciArena-Eval 基准上也仅达到 65.1% 准确率,远低于通用领域的 AlpacaEval 和 WildChat(>70%)。这表明:
科学推理任务的评估难度显著高于通用任务,亟需更稳健、可靠的评估方法。
高质量评估离不开高质量的人类反馈。SciArena 在数据采集和标注方面采取了多项严格措施:
这些措施确保了评估数据的高可信度,使 SciArena 成为当前最严谨的科学模型评估平台之一。
尽管 SciArena 已取得初步成功,但仍面临多个重要挑战:













