
3D Arena
Hugging Face 推出的 3D Arena 是生成式 3D 领域的一项重要进展。它首次实现了大规模、结构化的人类偏好数据收集,并通过 ELO 排名系统提供可靠、可解释的模型评估结果。
当用户只需写下“增加导出为 CSV 的功能”,AI 就能自动完成代码修改、测试并通过构建——这是否意味着真正的“无代码开发”时代正在到来?
要回答这个问题,首先需要一个可靠的衡量标准。为此,研究团队推出了 NoCode-bench,一个专门用于评估大语言模型(LLMs)在自然语言驱动下实现功能添加能力的新基准。
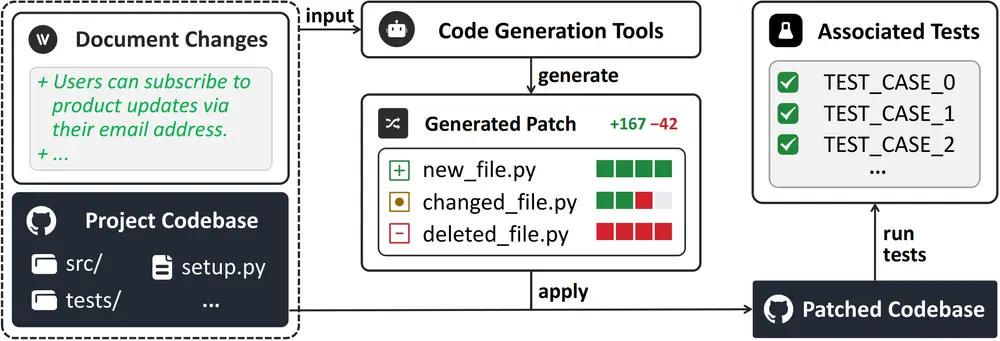
与以往聚焦于错误修复或代码补全的测试不同,NoCode-bench 直面更复杂的现实场景:仅凭文档描述,让模型理解需求并自主实现新功能。
这不仅是技术挑战的升级,更是对“AI 编程助手”是否真正具备工程化能力的一次检验。
当前主流的代码智能基准(如 SWE-bench)多集中于两类任务:
但它们并未触及软件开发中更常见的场景:功能演进。
在真实项目中,大多数变更源于产品文档、发布说明或用户需求的更新。例如:
“新增 Dark Mode 支持”
“允许用户将数据导出为 PDF”
“集成第三方登录方式”
这些变更通常由产品经理或用户提出,不附带具体实现方案。而 NoCode-bench 正是基于这类文档驱动的功能添加请求构建的。
它的目标很明确:
评估大模型能否仅通过自然语言输入,理解上下文、定位相关文件、生成正确代码,并通过测试验证。
NoCode-bench 从多个真实开源项目中提取了 634 个功能添加任务,涉及约 11.4 万次代码变更,覆盖 Web 开发、数据处理、CLI 工具等多个领域。
每个任务包含三部分核心内容:
| 组成部分 | 说明 |
|---|---|
| 文档变更 | 来自 PR 描述、release notes 或文档更新的自然语言输入,作为模型的指令 |
| 上下文文件 | 项目中与任务相关的源码、配置文件等,供模型分析依赖和结构 |
| 基准补丁 | 实际合并的代码变更,作为“正确答案”用于评估 |
此外,研究团队还构建了一个高质量子集:NoCode-bench-Verified,包含 114 个经过人工验证的任务实例,确保任务描述清晰、目标明确,适用于高置信度的人工评估。
为了保证任务的有效性与可评估性,NoCode-bench 采用系统化的五阶段构建流程:
这一流程确保了所有任务均可在隔离环境中执行和验证,提升了基准的可靠性。
NoCode-bench 支持两种主流 AI 编程框架的接入:
评估过程模拟真实开发流程:模型接收到文档变更后,需自主完成代码修改,并提交补丁。系统通过以下指标衡量其表现:
| 指标 | 含义 |
|---|---|
| 任务成功率(Success Rate) | 生成的补丁能完全通过所有测试用例的比例 |
| 补丁应用率(Patch Apply Rate) | 生成的代码能成功应用到代码库的比例 |
| 回归测试通过率 | 修改未破坏原有功能的程度 |
其中,“任务成功率”是最核心的指标。
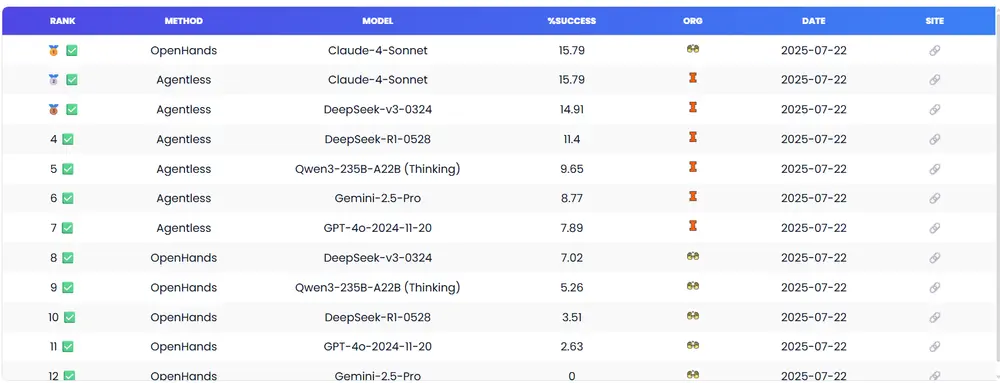
研究团队对多个先进 LLM 进行了测试,结果令人清醒:
| 模型 | NoCode-bench-Verified 成功率 | NoCode-bench-Full 成功率 |
|---|---|---|
| Claude-4-Sonnet | 15.79% | 6.94% |
| GPT-4o | 12.28% | 5.43% |
| DeepSeek-Coder-V2 | 9.65% | 4.12% |
即使是最强模型,在完整集上的成功率也不足 7%。
通过对失败案例的深入分析,研究发现当前 LLMs 在以下方面存在明显短板:
NoCode-bench 的意义不仅在于暴露了当前 AI 编程的局限,更在于定义了一个新的能力维度:从“响应式修复”走向“主动性开发”。
它提醒我们:
真正的智能编程助手,不应只是“写代码更快”,而是能理解业务意图、规划实现路径、并独立交付可运行功能的协作者。
未来,随着代理架构、记忆机制、测试反馈循环的演进,我们有望看到模型在 NoCode-bench 上的表现逐步提升。而这一进步,将直接推动无代码/低代码平台向更复杂场景延伸。













