
PinchBench
PinchBench 是一个基准测试系统,用于评估作为 OpenClaw 编码智能体的大语言模型。我们在不同模型上运行同一组真实世界任务,并衡量成功率、速度和成本,以帮助开发者为其用例选择合适的模型。
为了全面评估 Qwen-Image 的通用图像生成能力,并将其与最先进的闭源 API 进行客观比较,阿里推出了 AI Arena,一个基于 Elo 评分系统的开放基准测试平台。AI Arena 提供了一个公平、透明和动态的模型评估环境。
为了全面、公正地评估其最新图像生成模型 Qwen-Image 的通用生成能力,并与当前最先进的闭源模型(如 Imagen 4、GPT Image 1 等)进行直接对比,阿里巴巴通义实验室推出了 AI Arena ——一个基于 Elo 评分系统 的开源、开放图像生成模型基准测试平台。
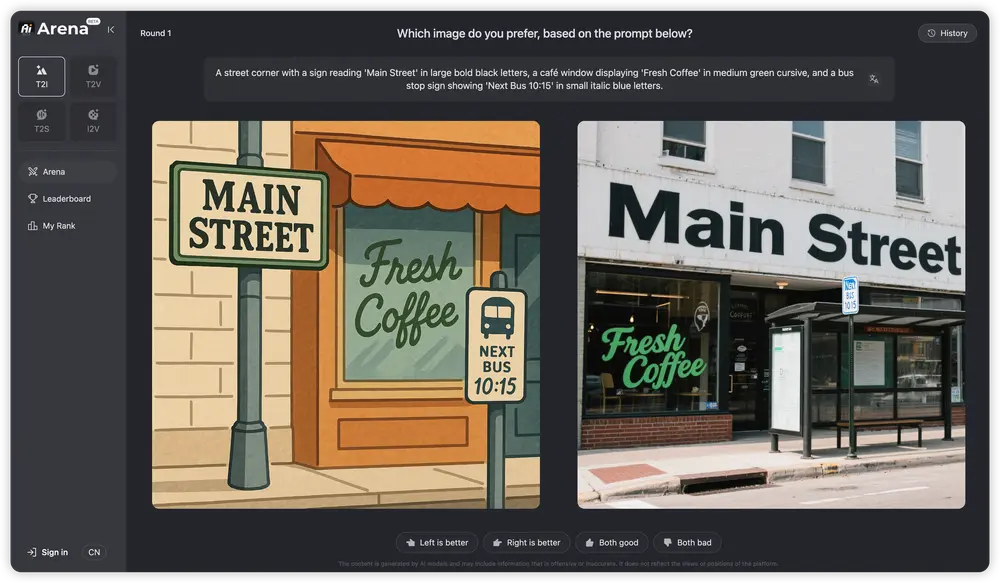
AI Arena 的目标是打破传统静态榜单的局限,构建一个公平、透明、动态演进的评估环境,让模型性能不再依赖单一指标,而是由真实用户在实际体验中投票决定。
AI Arena 采用经典的 成对比较(Pairwise Comparison) 方法,其核心流程如下:
这一机制确保了:
当前的图像生成评估常依赖自动化指标(如 FID、CLIP Score),但这些指标:
AI Arena 通过大规模人类反馈,弥补了这一空白,为开发者、研究人员和公众提供了一个数据驱动、可信赖的模型性能参考。
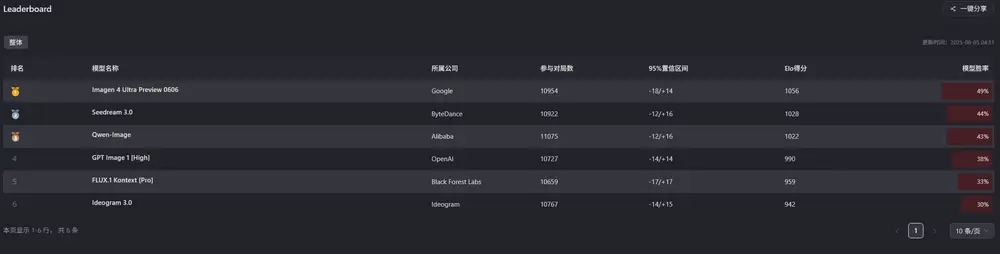
AI Arena 面向所有人开放:
AI Arena 的推出,正值阿里发布 Qwen-Image(20B 参数 MMDiT 模型)之际。该平台为 Qwen-Image 提供了一个直接对标顶级闭源模型的竞技场。
通过在 AI Arena 中的表现,Qwen-Image 能够:
AI Arena 不只是一个排行榜,更是一种全新的模型评估范式。它将“谁生成得更好”这个问题,交还给最权威的裁判——人类用户。
在这个由人类偏好驱动的竞技场中,模型不再比拼冷冰冰的分数,而是通过一次次真实的审美较量,赢得属于自己的位置。
对于关注多模态生成技术发展的任何人来说,AI Arena 都是一个值得关注的风向标。













