
DXT
DXT 不仅简化了本地 MCP 服务器的分发和集成流程,也为开发者提供了一个统一的标准格式。无论是本地服务开发者还是终端应用开发者,都可以通过 DXT 快速实现 MCP 功能的部署与使用。
大语言模型(LLM)正在从“会说话的系统”演变为能操作数字世界的“行动者”。它们不再只是回答问题,而是开始调用API、更新数据库、管理任务流程——这种能力的核心,是MCP(Model-Controller-Provider)架构。

但问题是:我们如何判断一个AI代理是否真的可靠?现有的评估方式大多停留在“读取数据”或“执行简单命令”的层面,难以反映复杂工作流中的实际表现。
为此,研究团队推出了 MCPMark ——一个面向真实使用场景的全面压力测试基准。它不是理论推演,而是一次对当前顶尖AI系统的实战检验。
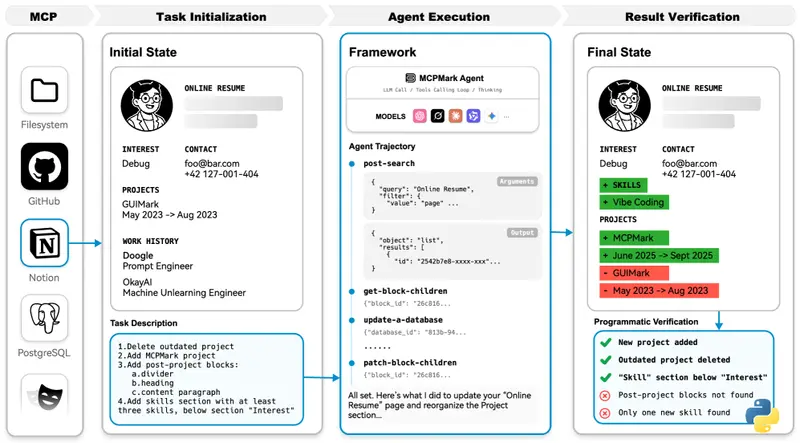
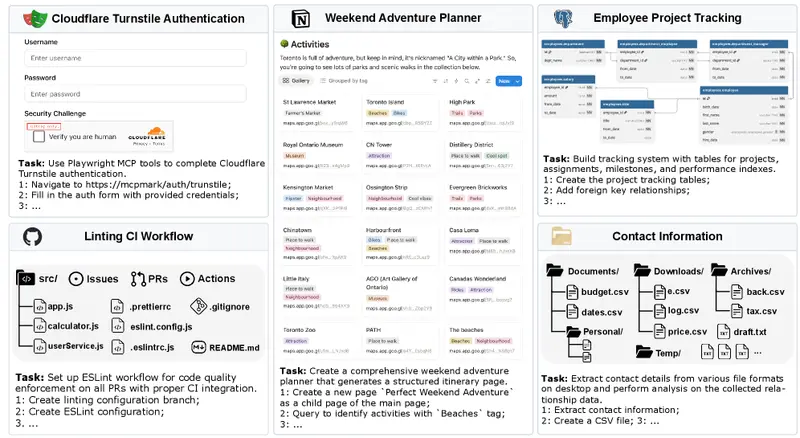
MCPMark包含127个精心设计的任务,覆盖多个行业场景,如项目管理、客户关系维护、自动化运维等。每个任务都具备以下特点:
这些任务由领域专家与AI工程师协作构建,模拟的是真实职业环境中常见的复合型需求。例如:“根据销售线索创建客户档案 → 同步至CRM系统 → 安排跟进会议 → 更新进度并通知团队”。
这不是一次简单的问答挑战,而是一场完整的“数字生存测试”。
研究人员在统一的轻量级代理框架下,测试了包括 gpt-5-medium、claude-sonnet-4 和 o3 在内的主流模型。评估指标包括:
结果令人警醒:
| 模型 | pass@1 | pass^4 |
|---|---|---|
| gpt-5-medium | 52.56% | 33.86% |
| claude-sonnet-4 | <30% | <15% |
| o3 | <30% | <15% |
平均来看,每个任务需要 16.2轮执行 和 17.4次工具调用 才可能达成目标。这意味着模型往往需要反复试错,而非一次性正确推理。
这组数据揭示了一个关键事实:当前AI代理的能力仍高度依赖“尝试-失败-修正”循环,缺乏稳定、高效的自主执行能力。
从MCPMark的结果中,可以提炼出制约AI代理发展的三个关键瓶颈:
多数模型表现出“看到什么就做什么”的行为模式,缺乏前瞻规划和抽象推理。它们无法像人类一样理解任务目标的本质,从而制定最优路径。
改进方向:
随着任务步骤增加,模型接收到的工具返回值、对话记录、中间状态不断累积,导致注意力分散甚至崩溃。
典型现象:
解决思路:
同一模型在同一任务上多次运行,可能出现完全不同的结果。这种不一致性严重影响可信度。
根本原因:
未来需构建具备“调试能力”的代理系统,能够在出错后自主识别问题、回滚状态并重新尝试。
MCPMark的价值不仅在于暴露短板,更在于为技术演进提供了明确坐标:
更重要的是,它确立了一个原则:评估AI代理,必须回归真实场景的复杂性。
尽管MCPMark已是目前最贴近现实的MCP评测体系,但它仍有局限:
未来的迭代方向包括:













