
Miro
Miro 是一个创新的可视化工作空间,使任何规模的分布式团队能够共同梦想、设计和建设未来。借助 Miro 智能画布™的魔力,团队可以在任何地方可视化概念、想法和解决方案,无需干擦标记。即使在远程、分布式或混合工作环境中,也能与您的团队同步、流畅并感受并肩工作的联系。
llm.pdf 并不是一个实用工具,而是一个技术探索项目——它试图回答一个问题:
我们能否仅用一个 PDF 文件,完成大语言模型(LLM)的推理?
答案是:可以。尽管效率有限,但这个项目成功实现了在标准 PDF 阅读器中运行完整的 LLM 推理流程。
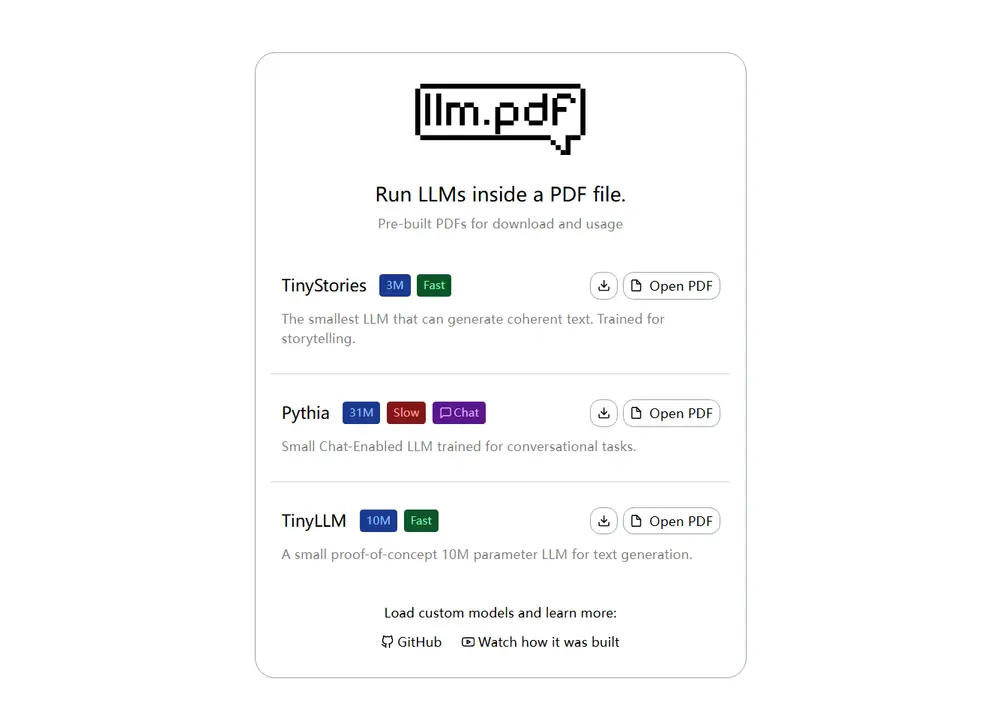
llm.pdf 的核心技术基于以下几个关键步骤:
llama.cpp 编译为 asm.js(一种可在浏览器中运行的低级 JavaScript 表示),使其能在支持 JavaScript 的环境中执行。当用户用支持 JavaScript 的 PDF 阅读器打开该文件时,模型会在本地解码、加载并执行推理,整个过程发生在用户的设备上。
📽️ 想看完整实现过程?作者在 YouTube 上发布了详细讲解视频(文末附链接)。
项目提供了一个脚本,用于将任意兼容的 LLM 模型打包为可运行的 PDF 文件。
进入 scripts 目录,运行以下命令:
cd scripts
python3 generatePDF.py --model "path/for/model.gguf" --output "path/to/output.pdf"
该脚本会自动完成以下操作:
你生成的 PDF 将具备与原始项目相同的功能:在支持 JS 的 PDF 阅读器中启动本地推理。
由于运行环境受限(JavaScript + 单线程 + 解码开销),模型性能受显著影响。选择模型时请注意以下几点:













