
Music Arena
Music Arena 是世界上第一个面向公众开放的音乐生成模型评测平台。在这里,AI 创作的旋律不再是黑箱输出,而是可以被真实听众直接比较、投票和评判的对象。我们相信,最好的评估方式不是参数规模或技术文档,而是人类的耳朵。
AI Ping 是一个面向大模型使用者,提供全面、客观、真实的大模型服务评测平台。官方精心打造的大模型服务性能排行榜,由专业团队定期、高频率地输出测评结果,并进行实时更新,清晰地呈现每个供应商在不同时间段的数据表现,为开发者提供即时、详细的数据参考服务,助力行业提升AI产品应用的开发效率与服务质量。
在生成式AI快速发展的今天,市场上已有数十家厂商提供数百种大模型API服务。面对琳琅满目的选择,开发者常面临一个现实难题:
哪个模型响应更快?吞吐更高?服务更稳定?
靠厂商白皮书?还是凭社区口碑?这些方式往往缺乏统一标准,难以支撑严谨的技术决策。
为此,清华大学 联合 中国软件评测中心 共同推出 AI Ping ——一个致力于提供全面、客观、真实的大模型服务性能评测平台。

即日起,AI Ping 正式上线 V0.1 版本,面向公众开放访问,旨在成为开发者在模型选型过程中的“第三方评测官”和“科学决策助手”。
当前大模型服务的性能描述多由供应商自行发布,存在以下问题:
这导致“参数虚高”“宣传误导”现象频出,增加了选型成本与试错风险。
AI Ping 的目标正是打破这一困局。它基于:
对主流大模型服务进行定期、高频、公开的性能评估,确保每一条数据都经得起验证。
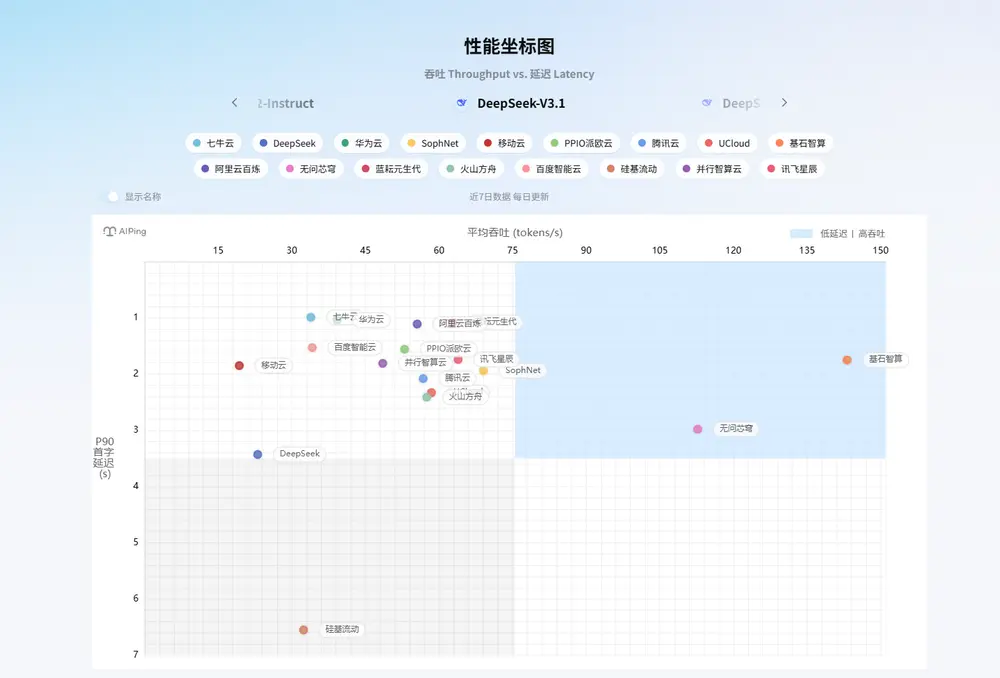
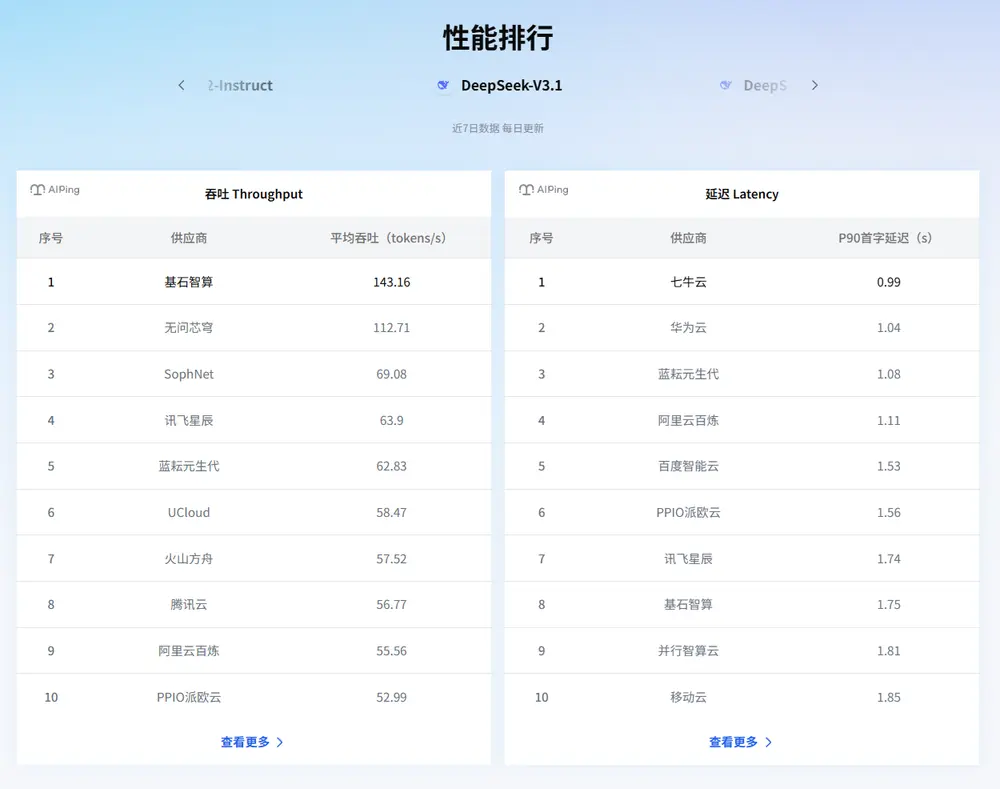
AI Ping 当前已整合并评测了 20余家主流供应商 的 数百个模型服务,涵盖国内主要云厂商、AI初创企业及开源服务商。
评测维度聚焦三大关键性能指标:
| 指标 | 说明 |
|---|---|
| 延迟(Latency) | 从请求发出到收到首个token的时间,影响交互流畅度 |
| 吞吐(Throughput) | 单位时间内可处理的token数量,决定批处理效率 |
| 可靠性(Reliability) | 请求成功率、错误率、服务可用性等稳定性表现 |
所有测试均在相同网络环境与负载条件下完成,确保公平可比。
结果以动态排行榜形式呈现,支持按时间维度查看各服务商的表现趋势,帮助识别长期稳定者与短期波动者。
除了性能数据,AI Ping 还构建了完整的模型与供应商信息档案,每个条目均包含:
无论是要做成本核算,还是评估功能兼容性,都能在这里找到一手资料。
AI Ping 坚持“用数据说话”,所有评测遵循严格的方法论:
平台不接受商业赞助,不设“推荐位”,所有排名由真实表现驱动,确保中立性与公信力。
目前平台提供两大核心入口:
操作简单直观,无需注册即可浏览,助力开发者快速完成初步筛选。
为确保评测一致性,AI Ping 在测试过程中采用如下措施:
此外,参考 Cline MCP 服务器中提到的 Network Timeout 设置机制(默认1分钟,可调至1小时),AI Ping 在可靠性测试中也设置了合理的超时容忍窗口,避免因短暂抖动误判服务失败。
虽然当前版本已具备基础服务能力,但这只是一个开始。
后续规划包括:
我们相信,只有建立公开、透明、可信的评测体系,整个行业才能走向高质量发展。













