
Yupp
Yupp正式推出人类评估系统 ,邀请使用者协助评估全球逾 500 个大语言模型,包括 ChatGPT、Claude、Gemini、DeepSeek、Grok 及 Llama 等,也涵盖了必须付费订阅的各种 Pro 与 Max 模型,并根据使用者的回馈制定 Yupp AI VIBE排行榜。
当前的多模态大语言模型(MLLM)在图像描述和视觉推理方面能力惊人,但它们真的“认识”自己看到的东西吗?还是仅仅在进行看似合理却脱离事实的“幻觉”?为了解决这一核心问题,Kimi 团队推出了 WorldVQA——一个专门用于衡量 MLLM 事实正确性与原子视觉世界知识的新基准。

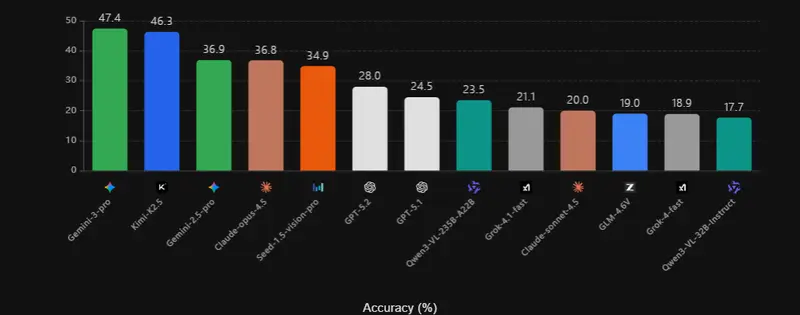
WorldVQA 的设计直指当前 MLLM 的软肋。它通过精心构建的问题,检验模型是否能准确识别图像中的特定实体(如一个罕见的建筑、一种冷门的动植物或一件历史文物),而非仅凭通用视觉模式进行猜测。评估结果显示,即便是最先进的模型,在面对长尾(小众、罕见)视觉知识时,准确率也普遍低于50%,凸显了现有模型在事实可靠性上的巨大挑战。
WorldVQA 数据集包含 3500 个经过严格人工验证的图像-问题对,其构建遵循三大原则:
所有数据均经过多轮人工审核,旨在成为一个可靠的“金标准”评估工具。
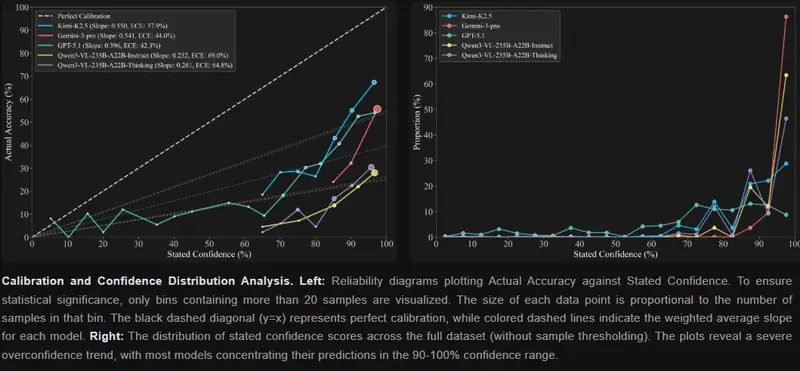
除了准确率,WorldVQA 还引入了校准度(Calibration)作为关键评估维度,即模型的主观置信度是否与其客观准确率相匹配。通过两个指标进行衡量:
实验结果表明,所有被测模型都存在显著的过度自信倾向——它们对自己的错误答案也常常抱有极高的信心。即便是表现最佳的 Kimi-K2.5 模型(ECE 37.9%,斜率 0.550),距离理想的“诚实”与“对齐”仍有很大差距。
WorldVQA 的发布,为推动多模态 AI 向更可靠、更知识丰富、更具自我认知能力的方向发展,提供了一个至关重要的评估标尺。













