AI Ping
AI Ping 是一个面向大模型使用者,提供全面、客观、真实的大模型服务评测平台。官方精心打造的大模型服务性能排行榜,由专业团队定期、高频率地输出测评结果,并进行实时更新,清晰地呈现每个供应商在不同时间段的数据表现,为开发者提供即时、详细的数据参考服务,助力行业提升AI产品应用的开发效率与服务质量。
随着模型上下文协议(Model Context Protocol, MCP)的快速普及,全球已上线超过 10,000 个 MCP 服务器,涵盖从日程管理、金融查询到智能设备控制的数百种工具。这一生态的兴起,使得大型语言模型(LLM)代理能够通过调用外部工具完成复杂任务。
然而,当前对 LLM 代理的评估仍停留在“小规模、单服务器、静态环境”的阶段,难以反映其在真实、动态、工具丰富的 MCP 环境中的实际能力。
为此,中国科学院软件研究所中文信息处理实验室与中国科学院大学联合推出 LiveMCPBench ——首个面向大规模 MCP 生态的综合性评估基准。
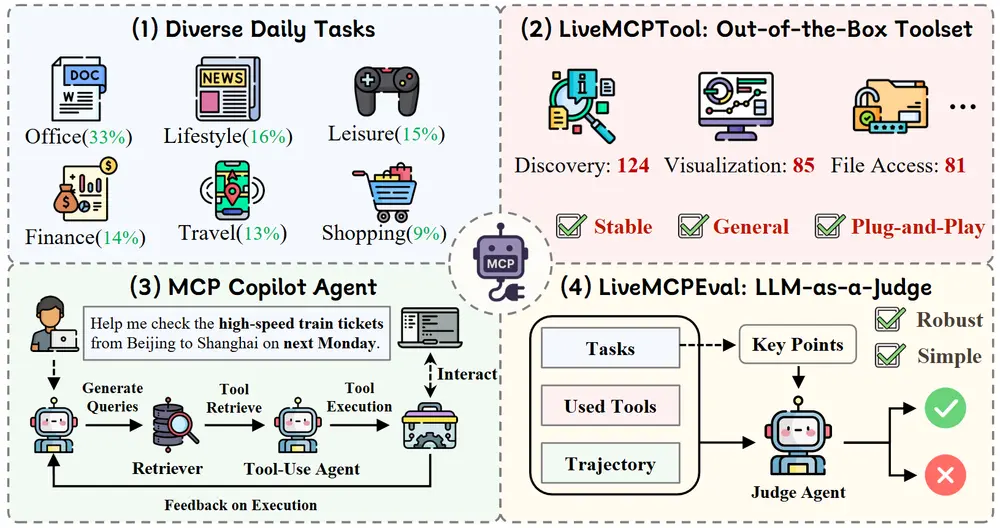
它不仅包含 95 个贴近日常生活的多步任务,还配套构建了可部署的工具集、自动化评估框架和参考代理系统,为 LLM 代理研究提供了可扩展、可重复、贴近现实的测试平台。
目前主流的工具使用评估方法存在三大瓶颈:
这些问题导致模型在实验室表现良好,但在真实 MCP 环境中可能“水土不服”。
LiveMCPBench 的目标正是填补这一空白:让代理评估真正走向“大规模、多服务器、动态化”。
任务覆盖六大高频场景:
| 领域 | 示例任务 |
|---|---|
| 办公 | “安排一场跨时区会议,并同步到团队日历” |
| 生活方式 | “根据天气推荐穿搭,并添加到购物清单” |
| 休闲 | “查找附近评分高的咖啡馆,预订靠窗座位” |
| 金融 | “查询基金近期收益,设置涨跌提醒” |
| 旅行 | “规划周末短途行程,包含交通与住宿” |
| 购物 | “比价三款耳机,下单最优惠且支持次日达的选项” |
所有任务均为多步骤、跨工具、跨服务器,要求代理具备动态规划与上下文保持能力。
为支持可复现评估,团队从公开平台 mcp.so 收集了 5,588 个 MCP 服务器配置,经过筛选构建出 LiveMCPBenchTool 工具集:
这是目前首个开放、可运行、免认证的大规模 MCP 工具集合,极大降低了研究门槛。
传统人工评估成本高、周期长。LiveMCPBench 提出 LiveMCPBenchEval ——一个基于 LLM 的自动评判系统,具备以下能力:
实验表明,该框架与人类评估者的平均一致性达到 81.05%,验证了其可靠性。
为展示基准的可用性,团队构建了 MCP Copilot Agent ——一个基于 ReACT 框架的多步代理系统:
该代理的设计也为后续高效代理架构提供了参考。
研究团队在 LiveMCPBench 上评估了 10 个主流模型,关键发现如下:
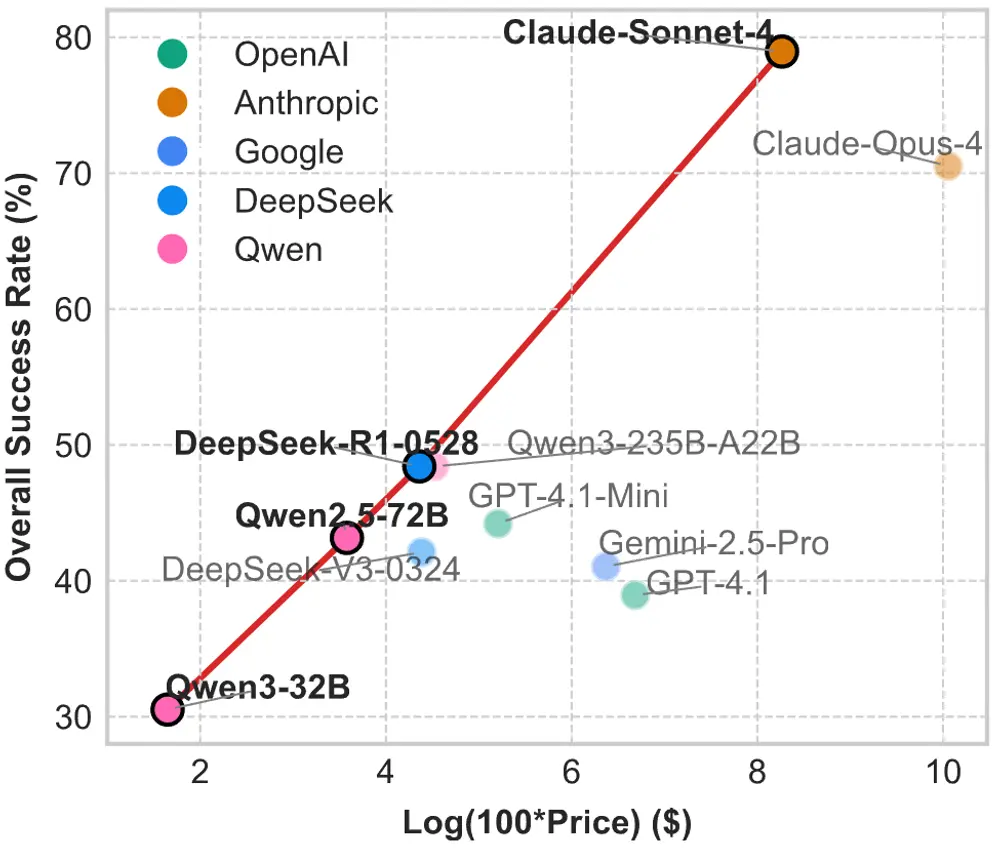
LiveMCPBench 的意义不仅在于“打分”,更在于它构建了一个贴近真实 MCP 生态的研究闭环:
它使得研究者可以: