
在众多衡量 AI 性能的基准测试中,一个看似“非正式”的实验正在引发关注:让大模型玩《宝可梦·蓝》——这款 1996 年发布的经典 RPG 游戏,正成为评估 AI 推理、规划与长期决策能力的新试验场。
据《华尔街日报》报道,谷歌、OpenAI 和 Anthropic 均已参与这一实践。它们的前沿模型——Gemini、GPT 和 Claude——被接入游戏环境,在 Twitch 上进行公开直播,名为“Gemini 玩宝可梦”“GPT 玩宝可梦”和“Claude 玩宝可梦”。
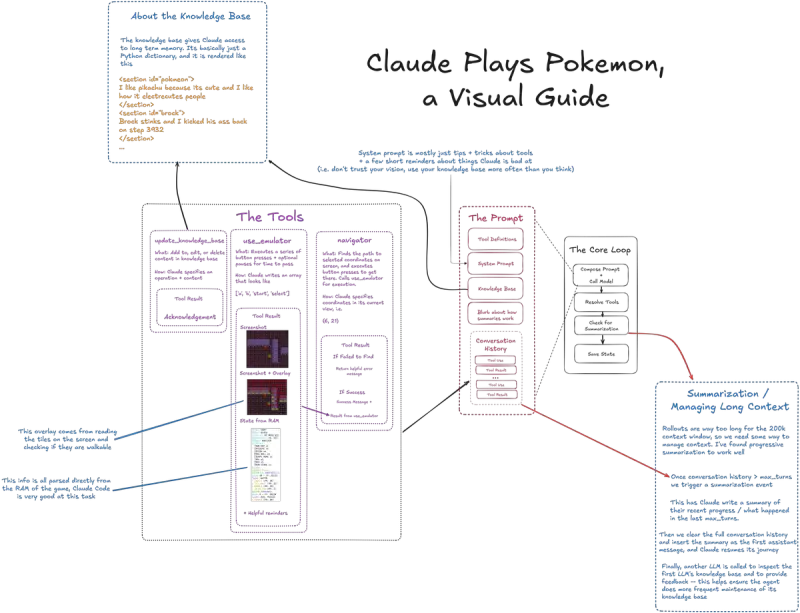
这一切始于 2024 年,当时 Anthropic 应用 AI 主管 David Hershey 在 Twitch 上直播了 Claude 尝试通关《宝可梦·蓝》。作为负责客户 AI 部署的工程师,Hershey 将此视为一种压力测试:“《宝可梦》比 Pong 或其他传统 AI 游戏复杂得多。它没有明确的规则边界,也没有单一最优解,对程序来说是个相当困难的问题。”
他的尝试迅速激发社区响应。自由开发者很快推出了 Gemini 和 GPT 的同类项目,并获得了各自公司的官方认可。据公开记录,Gemini 和 GPT 已成功通关《宝可梦·蓝》,目前正挑战续作;而 Claude 尚未完成首作通关,最新版本 Opus 4.5 仍在直播中推进。
- Claude:https://www.twitch.tv/claudeplayspokemon
- Gemini :https://www.twitch.tv/gemini_plays_pokemon
- GPT:https://www.twitch.tv/gpt_plays_pokemon
为什么是《宝可梦》?
《宝可梦》并非简单的线性任务。玩家需在开放世界中:
- 决定何时战斗、何时回避;
- 权衡是否挑战强敌以获取稀有宝可梦;
- 规划队伍配置、技能搭配与资源分配;
- 通过多个道馆考验,最终挑战宝可梦联盟。
这些决策涉及风险评估、长期规划、资源管理与上下文记忆——正是当前大模型在迈向通用人工智能(AGI)过程中亟需突破的能力。
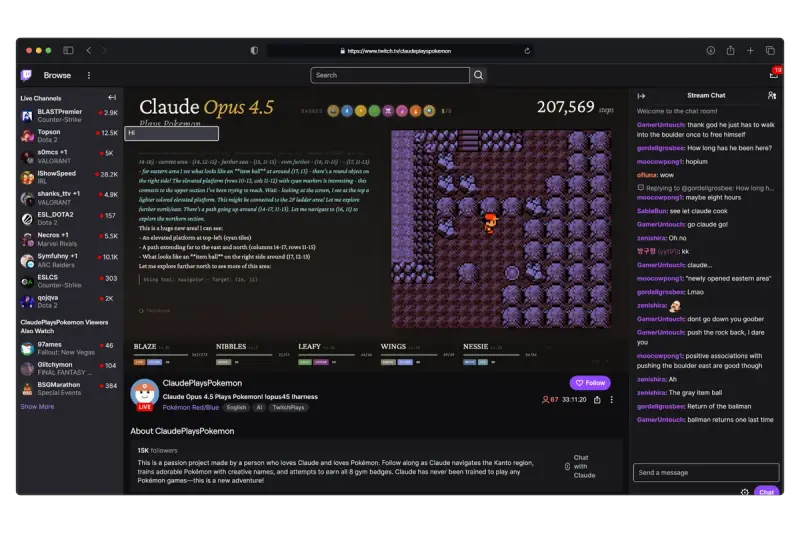
“这为我们提供了一个绝佳的观察窗口,”Hershey 表示,“不仅能定性感受模型表现,还能量化其进展:比如通关时间、战斗胜率、决策一致性等。”
从游戏到现实:控制框架的演进
Hershey 并非仅为娱乐。他将游戏中发现的模型行为模式,用于改进所谓的“控制框架”(control frameworks)——即围绕大模型构建的软件层,用于引导其注意力、约束输出范围、优化计算资源分配。
例如,当 Claude 在游戏中反复因错误判断而失败时,团队会分析其推理链,进而调整提示策略或引入外部记忆机制。这些经验随后被应用于客户的真实场景,如自动化客服、数据分析或代码生成,以提升效率与稳定性。
从《扫雷》到《宝可梦》:评估标准的升级
此前,AI 社区曾用更简单的任务测试模型能力,例如“让 AI 从零构建一个《扫雷》游戏”。在那场测试中,OpenAI 的 Codex 成功产出可运行版本,而 Gemini 未能交付可用结果。
相比之下,《宝可梦》的复杂度呈指数级上升:它要求模型在无明确指令、多目标并存、状态持续演变的环境中自主行动。这种“开放式任务”更能反映 AI 在现实世界中的适应能力。
随着大模型从“回答问题”转向“执行长期任务”,像《宝可梦》这样的游戏,正成为衡量其是否具备战略思维与持续推理能力的重要标尺。
目前,三款 AI 的《宝可梦》直播仍在 Twitch 持续进行。无论谁先通关续作,这场实验本身已证明:最古老的 RPG,或许正是测试未来智能的最佳沙盒。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











