
谷歌于周五在其 Gemini 开发者 API 中添加了一款新的实验性文本“嵌入”模型——Gemini Embedding。这款新型嵌入模型旨在将文本输入(如单词和短语)转化为数值表示,即嵌入(embeddings),以便捕捉文本的深层含义,并广泛应用于文档检索、分类等场景中。
Gemini Embedding 的特点与优势
- 继承 Gemini 模型的优势:作为首个基于 Gemini 系列 AI 模型训练的嵌入模型,Gemini Embedding 继承了 Gemini 对语言及其细微差别的深刻理解。这使得它在各种应用场景中表现卓越,特别是在金融、科学、法律及搜索等领域。
- 性能提升:谷歌宣称 Gemini Embedding 在流行的嵌入基准测试中表现出色,其性能超过了之前最先进的嵌入模型 text-embedding-004。此外,Gemini Embedding 可以一次性处理更大的文本和代码块,并支持超过 100 种语言,是 text-embedding-004 支持语言数量的两倍多。
- 应用广泛:由于其强大的通用性和对多种语言的支持,Gemini Embedding 预计将在多个行业中找到用武之地,帮助降低运营成本并提高响应速度。

官方介绍全文:
今天,我们通过 Gemini API 推出了一款新的实验性 Gemini 嵌入文本模型(gemini-embedding-exp-03-07)。
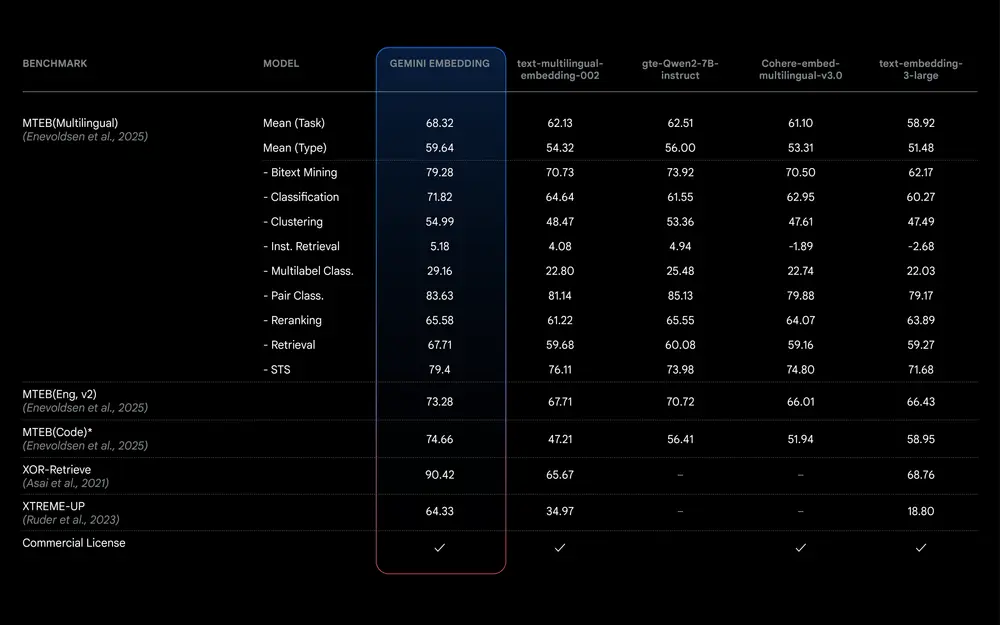
该嵌入模型基于 Gemini 模型本身训练,继承了 Gemini 对语言和细微上下文的理解,使其适用于广泛的用途。这款新嵌入模型的性能超越了我们之前最先进的模型(text-embedding-004),在 Massive Text Embedding Benchmark (MTEB) 多语言排行榜 上名列前茅,并具备更长的输入 token 长度等新功能!
我们迄今为止最强大的文本嵌入模型
我们训练了该模型以具备显著的通用性,在金融、科学、法律、搜索等多个领域提供卓越的性能。它开箱即用,无需针对特定任务进行大量微调。
MTEB(多语言)排行榜通过对检索和分类等多样化任务对文本嵌入模型进行排名,为模型比较提供了全面的基准。我们的 Gemini 嵌入模型在 MTEB(多语言)排行榜上取得了 68.32 的平均(任务)得分,比下一个竞争模型高出 +5.81。
为什么需要嵌入?
从构建智能检索增强生成(RAG)和推荐系统到文本分类,大型语言模型(LLM)理解文本背后含义的能力至关重要。嵌入通常对于构建更高效的系统至关重要,它可以降低成本并减少延迟,同时通常比关键字匹配系统提供更好的结果。嵌入通过数据的数值表示来捕捉语义和上下文。具有相似语义的数据在嵌入空间中更接近。嵌入支持广泛的应用,包括:
- 高效检索:通过比较查询和文档的嵌入,在大型数据库(如法律文档检索或企业搜索)中查找相关文档。
- 检索增强生成(RAG):通过检索并将上下文相关信息整合到模型的上下文中,提高生成文本的质量和相关性。
- 聚类和分类:将相似的文本分组,识别数据中的趋势和主题。
- 分类:根据内容自动分类文本,例如情感分析或垃圾邮件检测。
- 文本相似性:识别重复内容,支持网页去重或抄袭检测等任务。
您可以在 Gemini API 文档 中了解更多关于嵌入和常见 AI 用例的信息。
开始使用 Gemini 嵌入
开发者现在可以通过 Gemini API 访问我们新的实验性 Gemini 嵌入模型。
除了在所有维度上提升质量外,Gemini 嵌入还具有以下特点:
- 8K token 的输入限制:我们改进了上下文长度,允许您嵌入大块文本、代码或其他数据。
- 3K 维度的输出:高维嵌入,token 数量比之前的嵌入模型多近 4 倍。
- Matryoshka 表示学习(MRL):MRL 允许您截断原始的 3K 维度以缩小规模,从而满足所需的存储成本。
- 扩展的语言支持:我们将支持的语言数量增加了一倍,达到 100 多种。
- 统一模型:该模型超越了之前针对特定任务的多语言、仅英语和代码专用模型的质量。
虽然目前处于实验阶段且容量有限,但此次发布为您提供了早期探索 Gemini 嵌入功能的机会。与所有实验性模型一样,它可能会发生变化,我们正在努力在未来几个月内推出稳定且普遍可用的版本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











