字节跳动 Seed 团队正式发布 SeedEdit 3.0:支持 4K 图像编辑,编辑可用率显著提升今日,字节跳动 Seed 团队正式发布了新一代图像编辑模型 SeedEdit 3.0。该模型基于文生图模型 Seedream 3.0,融合多样化的训练数据与奖励机制,在图像主体与背景一致性、指令理解能...图像模型# SeedEdit 3.0# 字节跳动7个月前01890
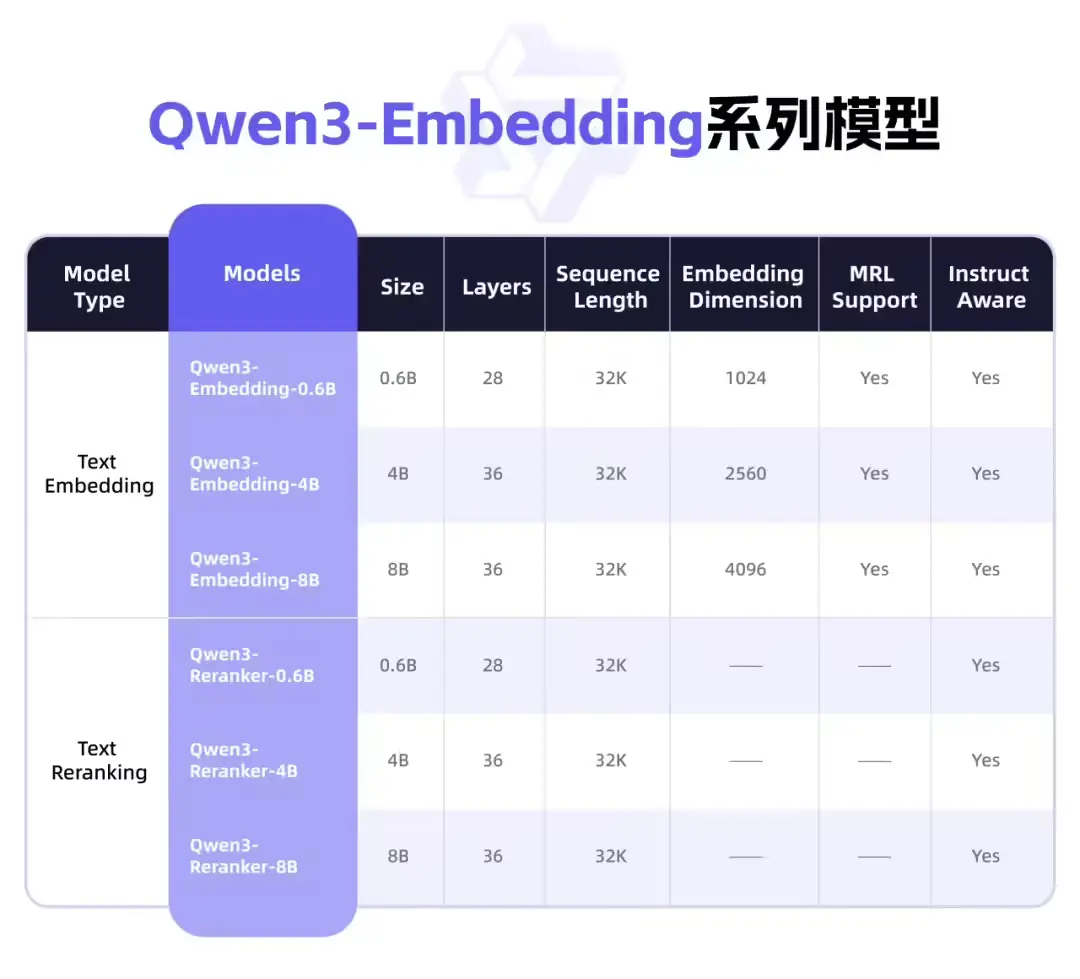
阿里正式发布 Qwen3 Embedding和Reranker 系列模型:专为文本表征与检索排序设计今天凌晨,阿里巴巴正式开源 Qwen3 Embedding 系列模型,作为 Qwen 模型家族的最新成员,该系列专注于文本语义表征、信息检索与排序任务,在多语言理解、跨语言检索和代码相关性建模等方面展...大语言模型# Qwen3 Embedding# Qwen3 Reranker# 阿里7个月前01450
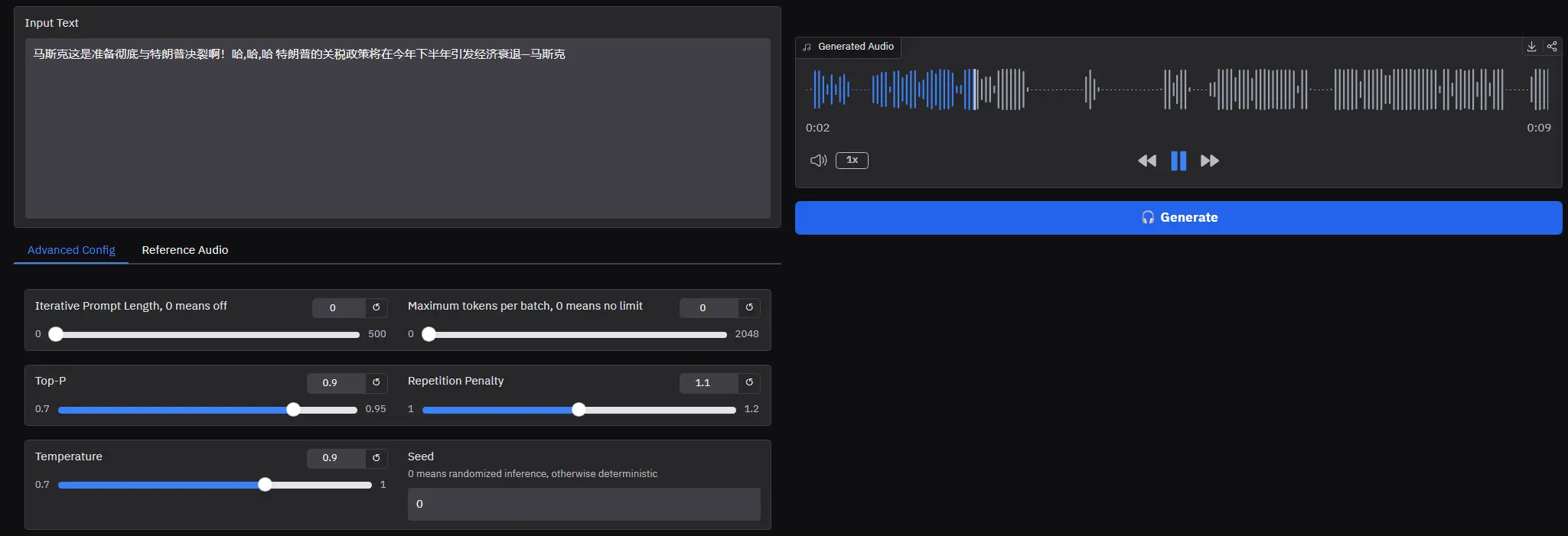
Fish Audio 发布 OpenAudio S1-mini:支持 14 种语言、50+ 情感语气的开源 TTS 模型文本转语音(TTS)领域迎来一位重量级开源选手 —— OpenAudio S1-mini。 这是由 Fish Audio 团队 推出的 S1 模型的轻量化版本,参数规模为 5亿(0.5B),基于超过 ...语音模型# Fish Audio# OpenAudio S1-mini# TTS 模型7个月前06240
英伟达推出面向文档理解的小而强视觉-语言模型 Llama Nemotron Nano VL英伟达正式发布了 Llama Nemotron Nano VL —— 一款专为高效处理复杂文档设计的轻量级视觉-语言模型(VLM)。该模型基于 Llama 3.1 架构构建,在保持高性能的同时兼顾推理...多模态模型# Llama Nemotron Nano VL# 英伟达7个月前02170
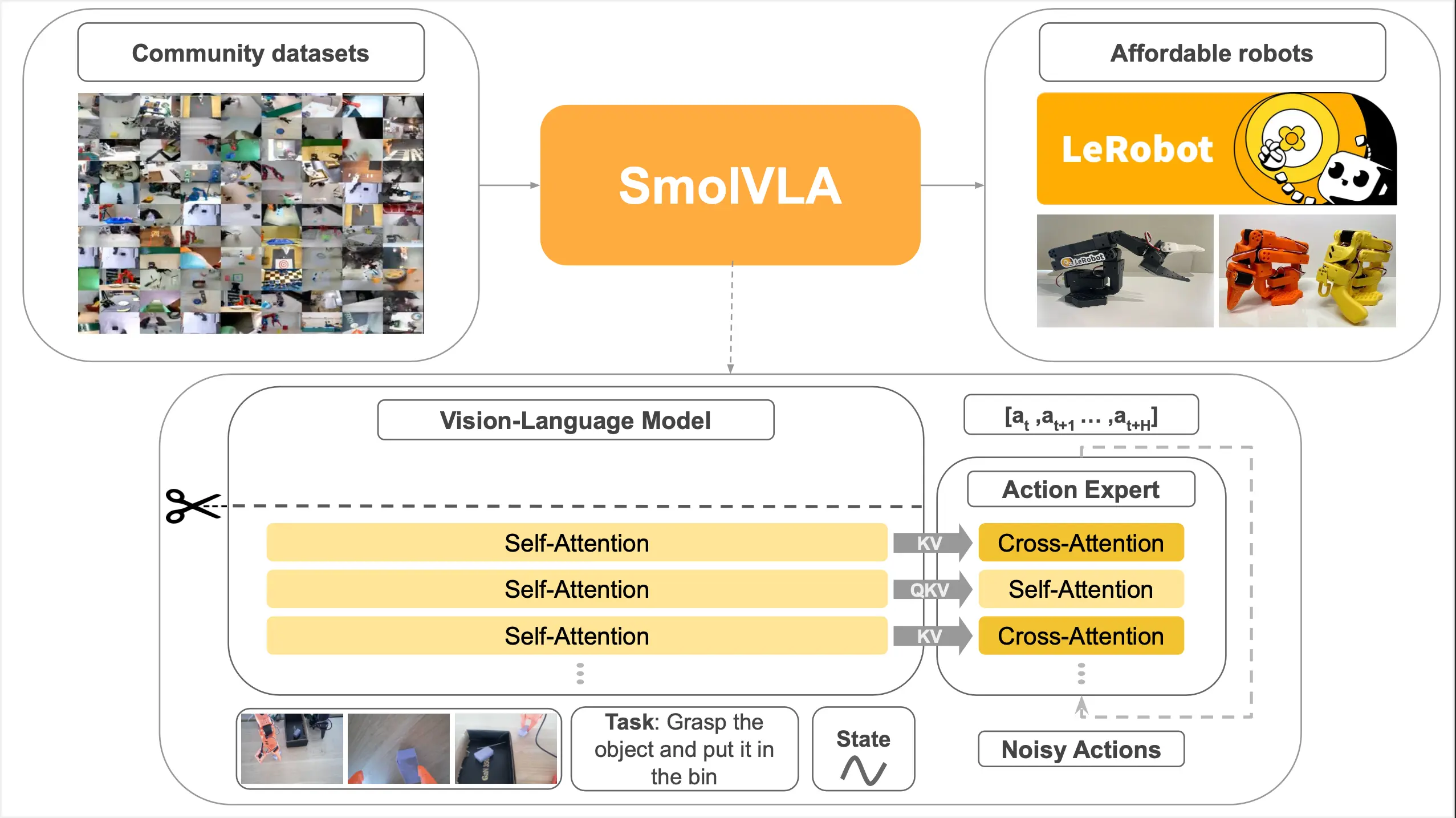
Hugging Face 推出轻量级机器人AI模型SmolVLA:可在MacBook运行随着AI与机器人技术的融合不断深入,构建个人机器人项目正变得前所未有的容易。近日,知名AI平台 Hugging Face 正式发布了其最新研发的机器人AI模型——SmolVLA,这一模型不仅小巧高效...多模态模型# Hugging Face# SmolVLA7个月前03190
Homunculus-12B:在消费级显卡上运行的高效推理模型随着大语言模型不断向轻量化和高性能方向演进,Arcee Homunculus-12B 成为一个值得关注的新成员。它是一款基于 Qwen3-235B 蒸馏而来、部署在 Mistral-Nemo 架构上的...大语言模型# Homunculus-12B# 推理模型7个月前02710
原生分辨率图像生成新范式NiT:原生分辨率扩散Transformer,实现任意分辨率和宽高比图像生成大语言模型(LLMs)凭借其在原生数据格式上训练的能力,能够高效处理可变长度文本。这种灵活的适应性启发我们思考一个关键问题: 扩散模型能否也具备类似的灵活性,在任意分辨率和宽高比下直接学习生成图像? ...图像模型# NiT# 原生分辨率生成7个月前03090
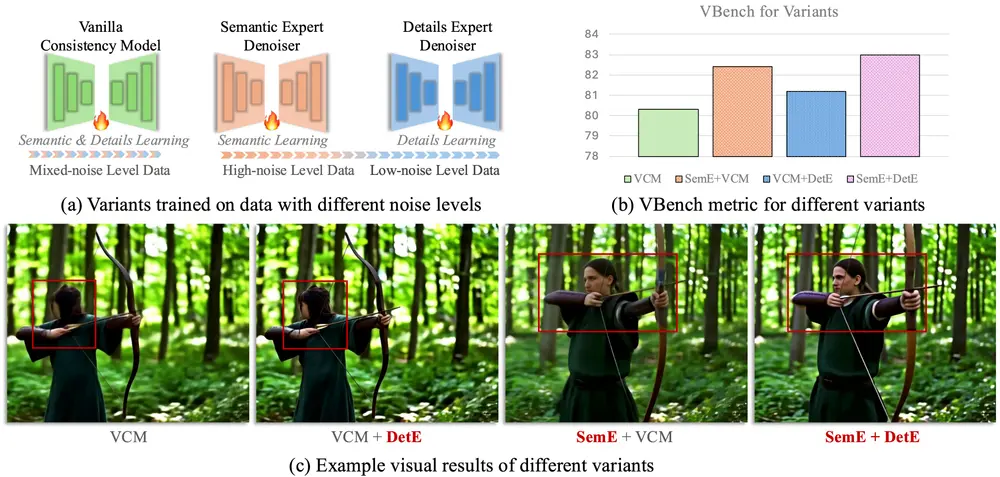
DCM:双专家一致性模型,实现高效高质量视频生成扩散模型在图像和视频合成任务中展现出卓越性能,但其依赖多步迭代去噪的过程,导致计算成本高昂。为解决这一问题,一致性模型(Consistency Models) 在加速扩散模型方面取得了重要进展。 然而...视频模型# DCM# 一致性模型7个月前02740
OpenAudio S1:Fish Audio 推出媲美语音演员的尖端文本转语音模型Fish Audio 重磅推出 OpenAudio S1 —— 一款在表现力、自然度和可控性方面达到新高度的文本转语音(TTS)模型。作为目前全球最先进的开源 TTS 模型之一,S1 在超过 200万...语音模型# Fish Audio# OpenAudio S1# TTS模型7个月前03080
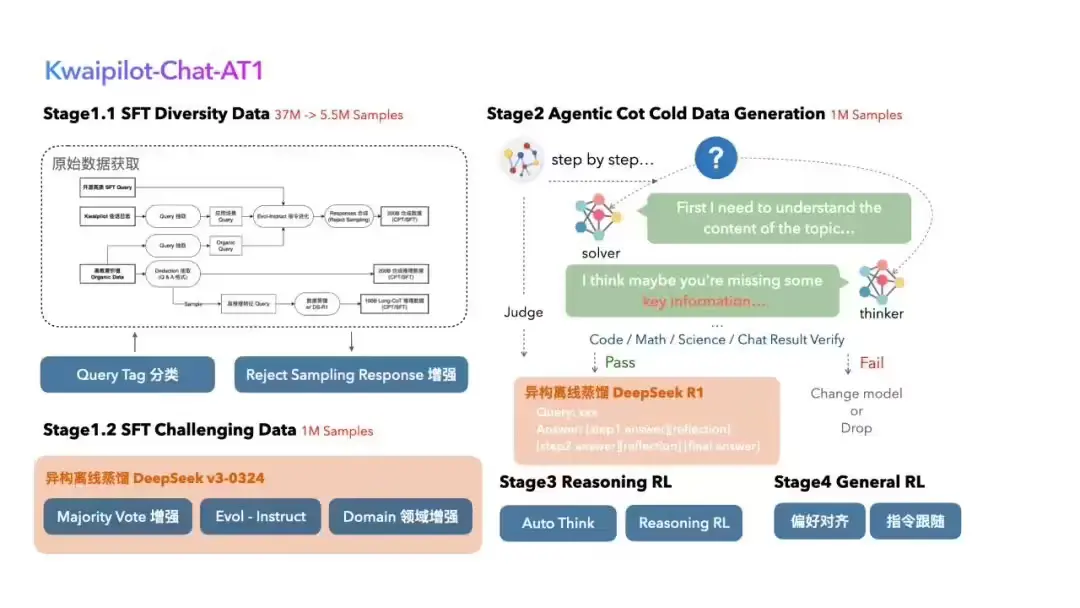
快手开源 KwaiCoder-AutoThink-preview:打造自动切换“思考模式”的大模型快手 Kwaipilot 团队正式开源了其最新研究成果——KwaiCoder-AutoThink-preview 自动思考大模型。该模型针对当前深度思考类大模型中普遍存在的“过度思考”问题,提出了一种...大语言模型# KwaiCoder-AutoThink-preview# 快手7个月前03010
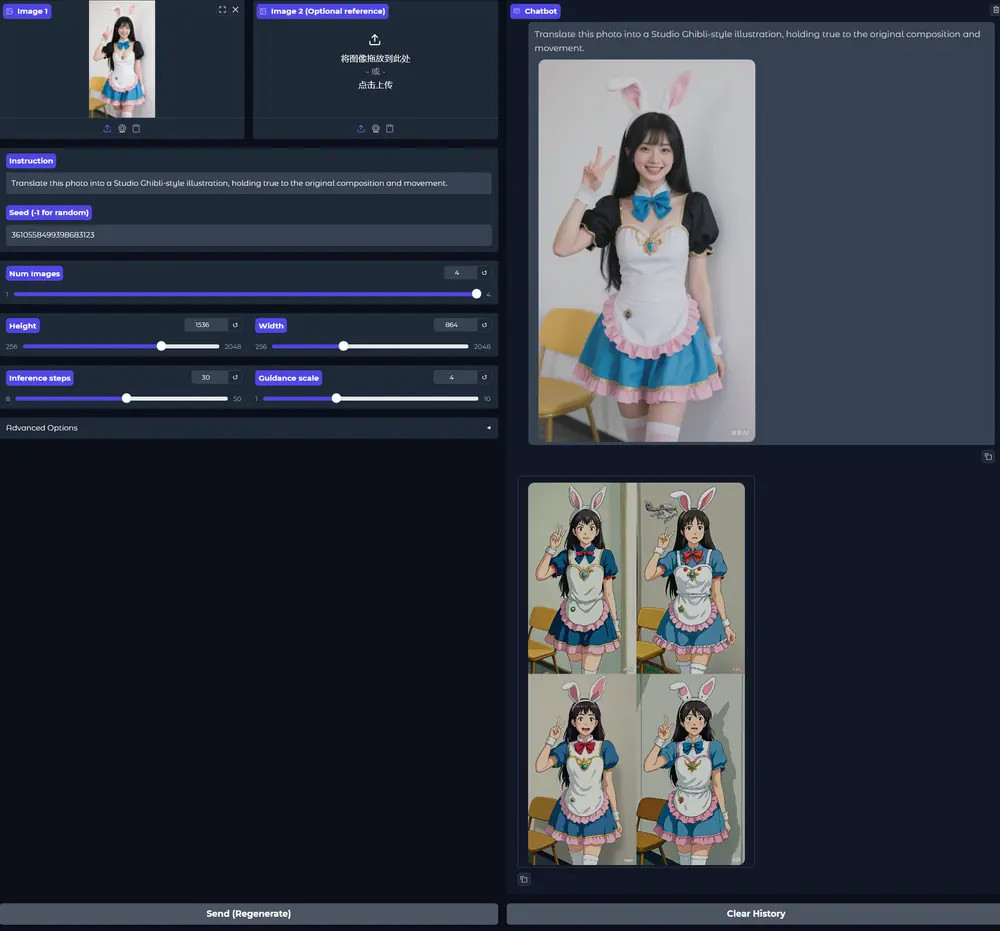
统一视觉理解与生成框架UniWorld:支持 20+语义图片编辑任务北京大学深圳研究生院、鹏城实验室、兔展AI的研究人员推出统一视觉理解与生成框架UniWorld,它基于强大的视觉-语言模型和对比语义编码器,能够同时处理图像感知和图像操控任务。 GitHub:http...图像模型# UniWorld# 图像生成# 图像编辑7个月前03450
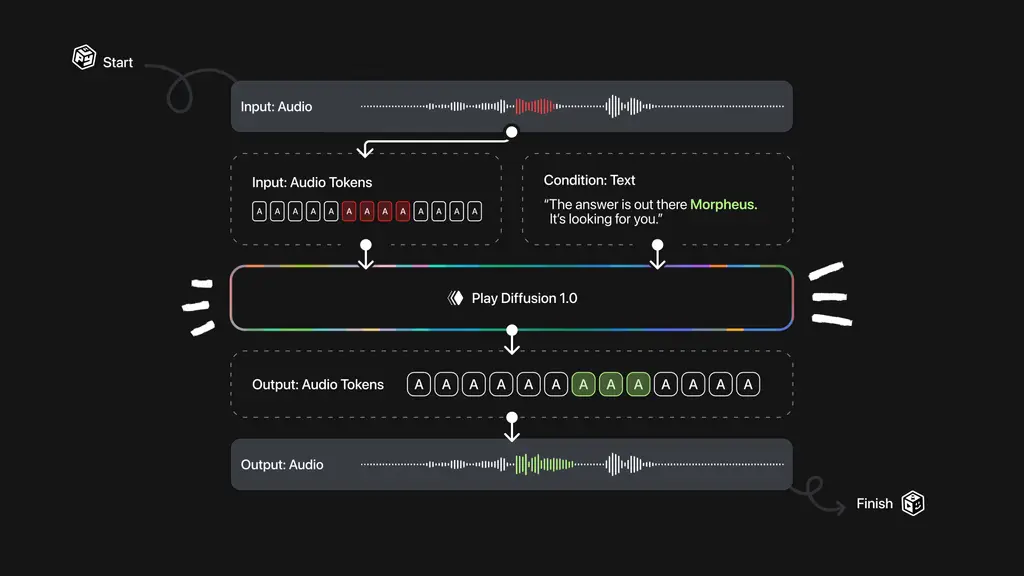
PlayAI 推出基于扩散机制的新型音频编辑模型 PlayDiffusion:能够实现对已有语音片段的精准修改,无需重新生成整段语音在语音合成领域,自回归变换器模型已被广泛应用于文本转语音(TTS)任务中,并取得了显著成果。然而,这些模型在处理一个关键问题时存在明显短板:如何在生成后的音频中进行局部修改(即“修补”),而不会破坏整...语音模型# PlayDiffusion# 音频编辑模型7个月前03090