
在语音合成领域,自回归变换器模型已被广泛应用于文本转语音(TTS)任务中,并取得了显著成果。然而,这些模型在处理一个关键问题时存在明显短板:如何在生成后的音频中进行局部修改(即“修补”),而不会破坏整体的连贯性和自然度?
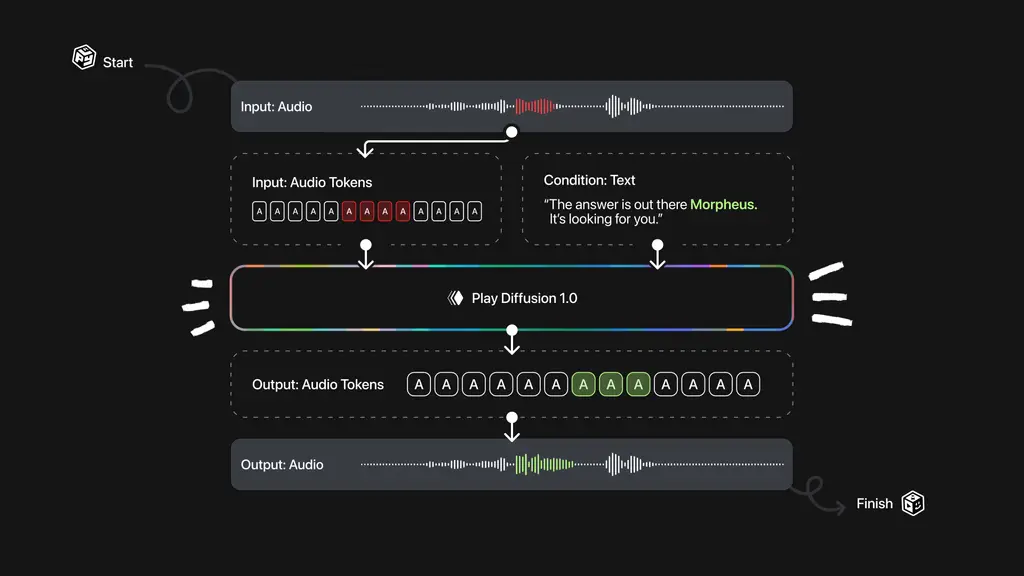
考虑这样一个场景:
“Neo, I can no longer tell you what it is. Morpheus. It's looking for you.”
假设你希望将其中的“Neo”替换为“Morpheus”,你会面临几个选择:
- 重新生成整句:虽然可以确保一致性,但计算成本高,且可能改变原句语调。
- 仅替换目标词:容易在边界处引入不自然的断点或音调突变。
- 从中间位置继续生成:可能会破坏未编辑部分的语音节奏。
所有这些方式都会影响最终输出的语音质量。因此,我们需要一种新的方法来实现更灵活、更自然的语音编辑。
PlayDiffusion:让语音编辑更自然
PlayAI 推出了 PlayDiffusion,这是一种基于扩散机制的新型音频编辑模型。它能够实现对已有语音片段的精准修改,无需重新生成整段语音,也不会破坏上下文的连续性。
- 官网:http://play.ai
- GitHub:https://github.com/playht/PlayDiffusion
- Demo:https://huggingface.co/PlayHT/PlayDiffusion
- Demo:https://huggingface.co/spaces/PlayHT/PlayDiffusion
核心流程如下:
- 编码音频序列:将原始音频转换为离散表示形式,每个单位称为“令牌”。
- 掩码目标区域:指定需要修改的部分并进行掩码处理。
- 扩散模型去噪:根据更新后的文本条件,逐步重建被掩码的音频部分。
- 保留上下文信息:确保编辑前后语音风格、语调一致。
- 解码回波形:使用 BigVGAN 解码器将修复后的令牌序列还原为高质量音频。
这种方法的优势在于:非自回归架构使得模型可以在保持上下文的同时一次性生成多个音频块,从而避免传统方法中的断裂与失真问题。
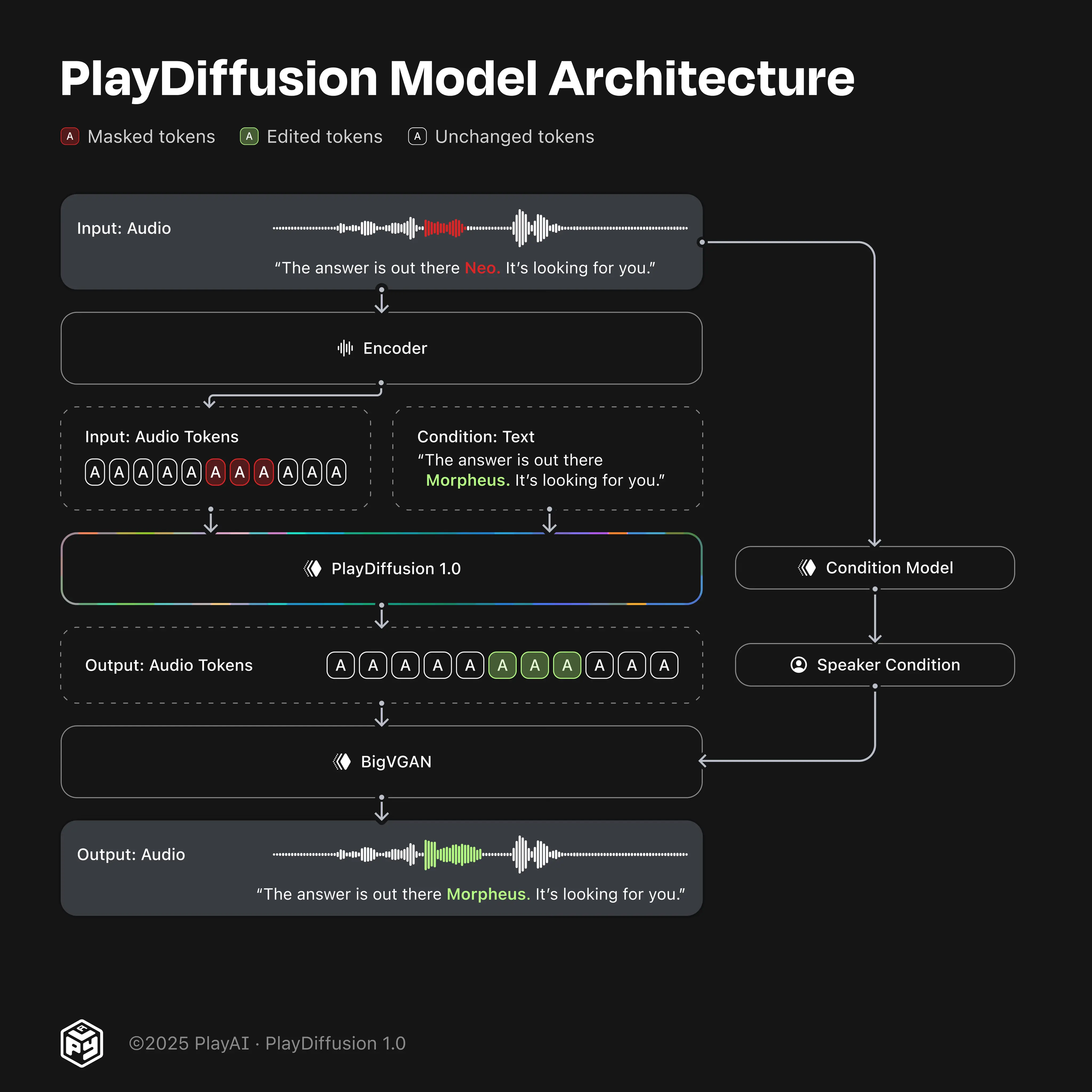
图 1. PlayDiffusion 1.0 模型 1) 包含语音“The answer is out there Neo. Go grab it!”的输入音频被编码为离散音频令牌。 2) 对应于目标编辑语音的令牌被掩码,这里我们掩码“Neo”的令牌。 3) 给定更新文本和完整的输入令牌序列(即掩码和未掩码部分),PlayDiffusion 生成编辑后的输出序列。 4) 该序列通过我们的 BigVGAN 转换为波形,条件基于从原始片段提取的说话者嵌入。
离散扩散也能做 TTS?
当整个音频都被掩码时,PlayDiffusion 同样可以作为一个高效的文本转语音系统。
传统的自回归模型依赖逐个生成令牌的方式,效率较低;而 PlayDiffusion 使用的扩散机制是非自回归的,可以在固定步数内同时预测所有令牌,极大提升了生成速度和稳定性。

举例说明:使用运行在 50 Hz 的音频编解码器,生成 20 秒的语音在自回归设置中需要 1000 个步骤。而扩散模型可以一次性生成所有 1000 个令牌,并仅通过 20 个迭代步骤进行优化——在生成步骤上效率提高了高达 50 倍,同时不影响输出的质量或可理解性。
模型训练与优化
我们在一个预训练的解码器架构基础上进行了多项定制化改进,以适应语音生成任务:
1. 非因果注意力机制
不同于 GPT 类模型使用的因果注意力,我们采用非因果机制,使模型能同时关注前、后上下文,提升编辑准确性。
2. 自定义分词器与嵌入压缩
为了提升效率,我们设计了一个仅包含 10,000 个文本令牌的 BPE 分词器,大幅减小嵌入表体积,同时不影响语音质量。
3. 说话者条件建模
通过引入 e(w) 模型提取说话人特征向量,确保生成的语音在不同编辑操作中保持一致的身份感。
4. 掩码训练策略
在训练过程中,我们随机掩码部分音频令牌,并要求模型基于剩余信息和文本条件进行重建。这一策略有效模拟了真实编辑场景。
解码过程:逐步优化,精准还原
推理阶段采用迭代式解码:
- 初步预测:模型基于当前文本和上下文生成初始预测。
- 置信度评分:为每个预测分配置信度,确定哪些区域最需优化。
- 自适应重掩码:逐步减少不确定性最高的区域,聚焦于最难预测的部分。
这一过程持续迭代,直至完成所有修复步骤,最终输出自然流畅的语音结果。

立即体验 PlayDiffusion
为了让用户快速上手,我们已在 Studio 平台上线了语音编辑器功能。这是探索 PlayDiffusion 能力的最佳入口,无论你是想尝试语音修补、调整发音,还是创作全新的语音内容,都可以轻松实现。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











