中科院+腾讯提出AudioStory:LLM+TTA协同,破解长篇叙事音频“不连贯”痛点文本到音频(TTA)技术已能生成高质量短音频片段,但面对“雨中追逐场景”“视频配音旁白”这类需要时间连贯性、情感一致性的长篇叙事需求时,传统模型常出现“声音断层”“氛围割裂”等问题。 GitHub:h...语音模型# AudioStory# TTA4个月前01690
字节跳动推出 USO:统一风格与主体生成模型,开源全方案赋能创作字节跳动智能创作实验室UXO项目组近期发布了UXO家族的新成员——USO(统一风格-主体优化定制模型)。这款模型打破了现有技术中“风格驱动”与“主体驱动”生成相互孤立的困境,能在单一框架下自由组合任意...图像模型# USO# 字节跳动# 统一风格与主体生成模型4个月前04470
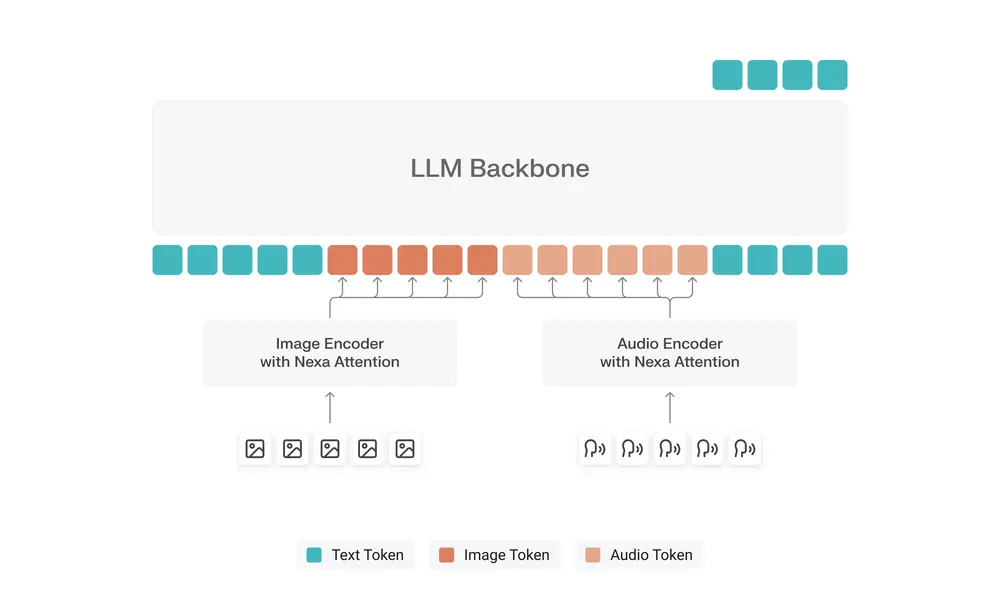
NEXA AI推出OmniNeural-4B:全球首个为 NPU 原生设计的多模态 AI 模型当AI模型需要在手机、PC等终端设备上处理文本、图像、音频时,“速度慢、耗电高、依赖网络”往往是难以回避的问题——多数模型最初为GPU设计,移植到终端的NPU(神经网络处理单元)时需“强行适配”,导致...多模态模型# Nexa AI# NPU# OmniNeural-4B4个月前0730
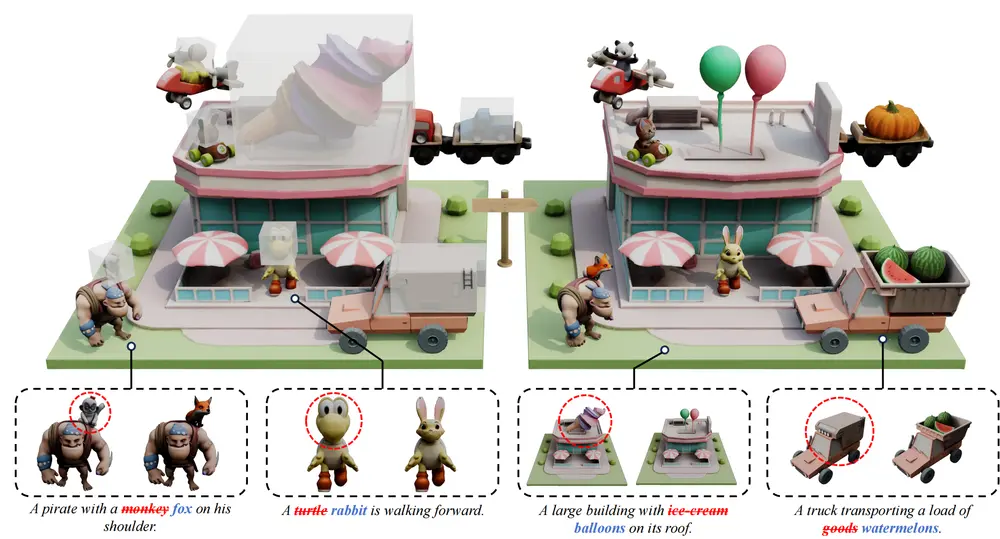
北航、人大等联合腾讯混元提出VoxHammer:无需训练,实现3D模型精准局部编辑3D指定区域的局部编辑,是游戏资产制作、机器人交互场景中的核心需求——比如给游戏角色更换装备、调整机器人零件结构,都需要在修改目标区域的同时,确保未编辑部分的几何形态与纹理不被破坏。 近期,北京航空航...3D模型# 3D模型精准局部编辑# VoxHammer4个月前01790
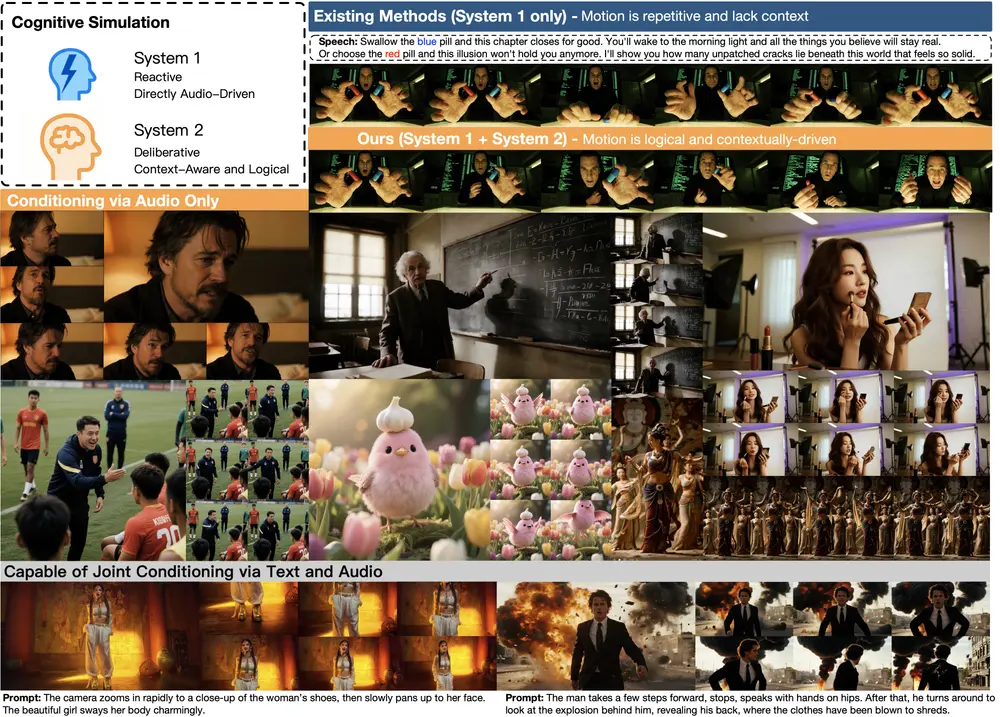
字节跳动发布OmniHuman-1.5:模拟人类双重认知,生成语义连贯的高逼真角色动画字节跳动近期推出新型视频角色生成框架 OmniHuman-1.5,核心突破在于模拟人类“系统1(快速直觉反应)+系统2(缓慢深思规划)”的双重认知过程,实现从“单一图像+语音轨道”到“物理逼真、语义连...视频模型# OmniHuman-1.5# 字节跳动4个月前0700
腾讯优图实验室发布Youtu-agent:开源、高性能的自主智能体框架,开箱即用多场景能力腾讯优图实验室近期推出了自主智能体框架 Youtu-agent——一款以“灵活、高性能、低成本”为核心的工具,不仅能支持自主智能体的构建、运行与评估,还在多项权威基准测试中表现突出。更重要的是,它针对...大语言模型# Youtu-agent# 智能体框架4个月前01390
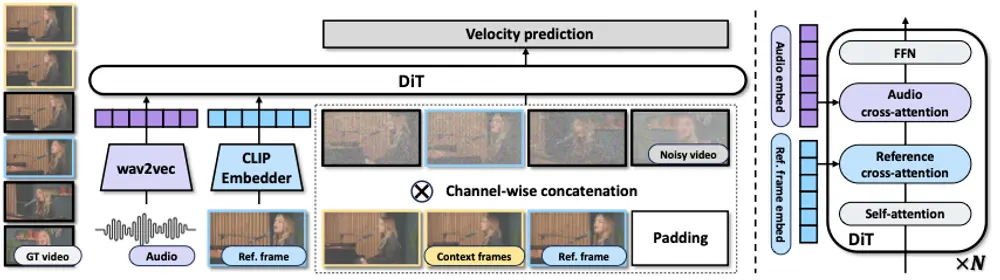
InfiniteTalk:支持稀疏帧输入的全动态音频驱动视频生成,实现全身协调的说话视频生成在虚拟人、影视后期、跨语言内容本地化等场景中,理想的配音技术不仅要实现精准的唇部同步,还需让头部运动、面部表情、身体姿态自然地跟随语音节奏变化,同时保持人物身份一致性。 项目主页:https://me...视频模型# InfiniteTalk# 对口型4个月前01000
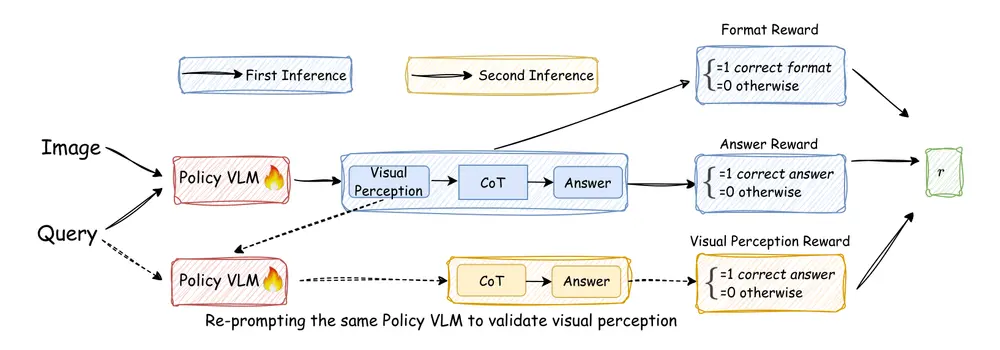
腾讯AI实验室联合两校发布Vision-SR1:自我奖励+推理分解,破解VLM视觉推理难题腾讯AI实验室联合马里兰大学帕克分校、华盛顿大学圣路易斯分校的研究团队,共同发布了新型视觉-语言模型(VLM)——Vision-SR1。该模型聚焦于解决传统VLM的核心痛点,通过创新的“自我奖励机制...多模态模型# Vision-SR1# 视觉-语言模型4个月前02000
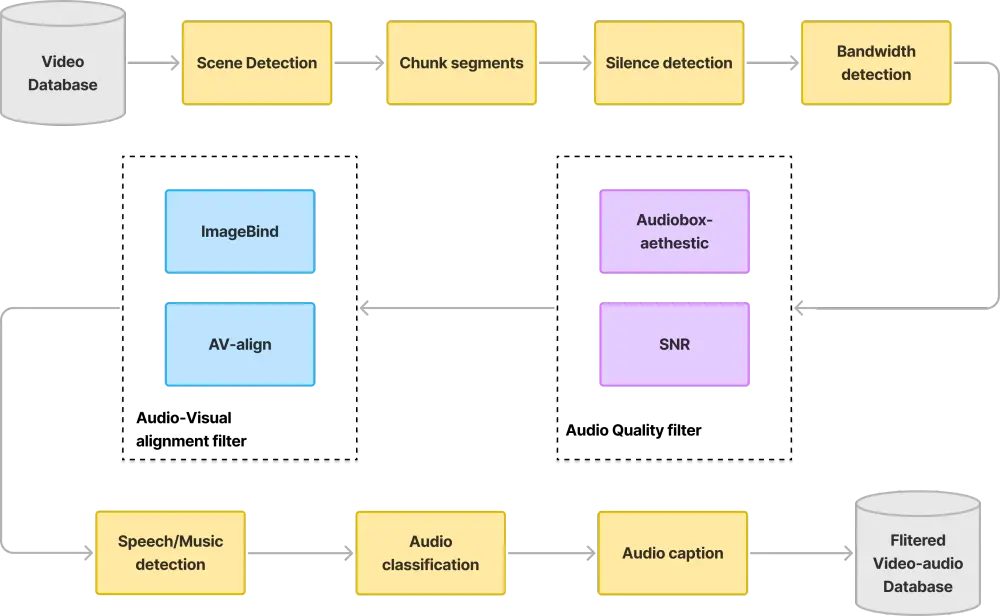
腾讯开源混元视频音效生成模型HunyuanVideo-Foley:端到端TV2A模型,为创作者打造高保真音视频体验腾讯今天正式开源 HunyuanVideo-Foley —— 一个端到端的文本-视频-音频(Text-Video-to-Audio, TV2A)生成模型,专注于为视频内容自动生成高保真、语义对齐的音效...视频模型# HunyuanVideo-Foley# 混元视频音效生成模型# 腾讯4个月前0900
阿里开源 Wan2.2-S2V-14B:输入一张图 + 一段音频,生成电影级数字人视频阿里Wan团队正式开源音频驱动视频生成模型Wan2.2-S2V-14B。这款模型打破了传统视频生成对复杂输入的依赖——用户仅需提供一张静态图像与一条音频,即可生成面部表情自然、口型精准同步、肢体动作流...视频模型# Wan2.2-S2V-14B# 数字人# 阿里4个月前04460
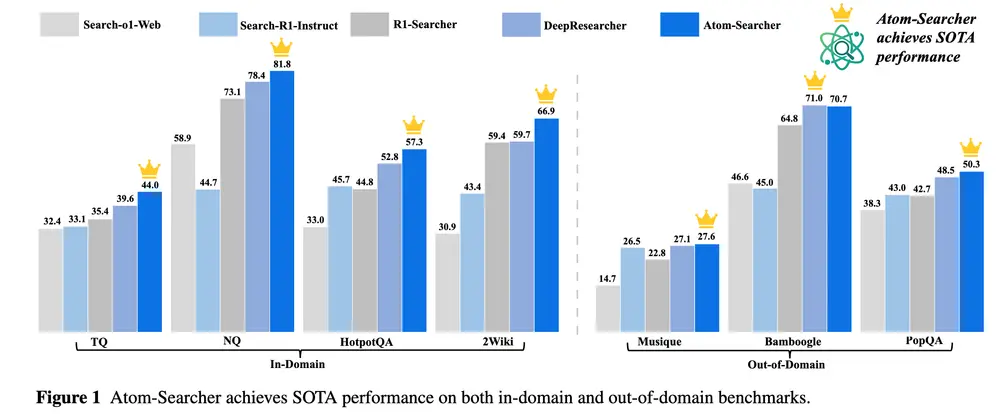
蚂蚁集团新框架Atom-Searcher:用“原子化思想”破解LLMs深度研究难题大语言模型(LLM)在开放域问答、信息检索等任务中展现出强大潜力。然而,面对需要多步骤推理、工具调用和外部验证的复杂任务,仅靠模型的静态知识和简单提示工程往往力不从心。 现有方法如检索增强生成(RAG...大语言模型# Atom-Searcher# 蚂蚁集团4个月前01730
MV-RAG:用检索增强实现更可靠的文本到3D生成近年来,基于预训练2D扩散模型的文本到3D生成方法取得了显著进展。这类方法通过“蒸馏”2D先验知识,能够生成视觉质量高、多视角一致的3D内容。然而,当面对罕见或未见过的概念(如“博洛尼亚犬”或“Lab...3D模型# 3D生成# MV-RAG4个月前01810