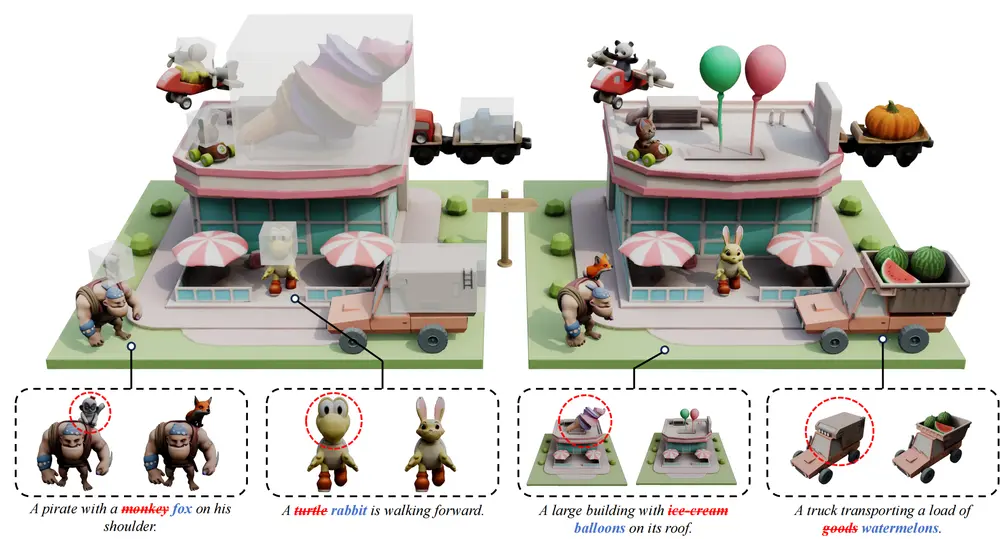
3D指定区域的局部编辑,是游戏资产制作、机器人交互场景中的核心需求——比如给游戏角色更换装备、调整机器人零件结构,都需要在修改目标区域的同时,确保未编辑部分的几何形态与纹理不被破坏。
近期,北京航空航天大学、中国人民大学、清华大学联合腾讯混元项目组,提出了一种无需训练的3D编辑新方法VoxHammer。它跳出传统“先编辑2D图像、再重建3D模型”的思路,直接在3D潜在空间中操作,既能精准修改指定区域,又能完美保留未编辑部分的一致性,还为后续上下文3D生成提供了高质量数据支撑。
为什么需要VoxHammer?传统3D编辑的两大核心痛点
在VoxHammer出现前,主流3D局部编辑方法多遵循“2D→3D”的流程:先对3D模型的多视角渲染图进行编辑(比如用图像工具修改角色衣服颜色),再通过重建算法还原成3D模型。这种方式存在难以解决的问题:
- 未编辑区域易失真:2D编辑过程中,难免会影响到目标区域外的像素(如修改衣服时蹭到背景),重建3D后会导致未编辑部分的几何或纹理出现偏差;
- 整体一致性难保证:不同视角的2D编辑结果可能存在差异(如正面看衣服颜色一致,侧面出现色差),重建后的3D模型容易出现“视角矛盾”,比如零件衔接处不连贯。
VoxHammer的设计初衷,正是通过“直接操作3D潜在空间”,从根源上解决这两个痛点——无需依赖2D图像中转,让编辑过程更精准、结果更连贯。
核心能力:覆盖多场景的3D编辑需求
VoxHammer不仅能解决传统方法的痛点,还支持多种实用编辑场景,可直接适配游戏、机器人、3D内容创作等领域的需求:
1. 两种核心编辑模式
- 基于图像的3D编辑:若用户已有编辑好的2D参考图(如“角色戴帽子的正面图”),VoxHammer可结合原始3D模型与参考图,在3D空间中精准复现编辑效果,避免多视角不一致;
- 基于文本的3D编辑:无需手动绘制,仅通过文本提示即可完成编辑。例如输入“给3D狗模型添加黄色雨衣和靴子”,模型会自动定位到“身体”“脚部”等指定区域,生成符合描述的3D结构,同时保留狗的原有姿态与毛发纹理。
2. 三大典型应用场景
- 部件感知对象编辑:针对3D资产的特定部件进行修改,比如给椅子更换扶手样式、给汽车调整轮毂形状。模型能精准识别“部件边界”,避免修改时影响到椅子座面或汽车车身;
- 组合3D场景编辑:支持多物体组成的复杂场景编辑,比如在“书桌+台灯+书本”的3D场景中,仅修改台灯的灯罩颜色,同时保证书桌纹理、书本摆放位置完全不变;
- NeRF/3DGS编辑:可扩展到神经辐射场(NeRF)、3D高斯 splatting(3DGS)等新兴3D表示形式的编辑,比如调整NeRF渲染的房间场景中“窗户的大小”,保持房间整体光影效果连贯。
技术创新:无需训练,靠三大设计实现精准编辑
VoxHammer的核心优势是“无需额外训练”——直接基于预训练的3D生成模型(TRELLIS)进行操作,通过三大关键设计实现精准且一致的编辑:
1. 精准3D反转:获取“可回溯”的潜在特征
要在3D潜在空间编辑,首先需要将原始3D模型“拆解”为模型能理解的潜在特征。VoxHammer会:
- 预测3D模型在扩散过程中的“反转轨迹”:相当于反向推演模型生成3D资产的过程,记录下每个时间步的潜在表示(描述几何、纹理的核心数据)和键值令牌(注意力机制中的关键匹配信息);
- 将这些特征缓存下来:后续编辑时,未编辑区域的特征可直接复用,避免重新生成导致的失真。
2. 特征替换策略:锁定未编辑区域的一致性
编辑阶段,VoxHammer采用“替换而非重绘”的思路,确保未编辑部分不变:
- 从反转得到的“终止噪声”开始去噪(扩散模型生成内容的常规流程);
- 遇到未编辑区域时,不进行新的去噪计算,而是直接替换为之前缓存的“反转潜在表示”和“键值令牌”;
- 这种方式相当于“给未编辑区域上了锁”,无论编辑过程如何操作,其几何和纹理都与原始模型完全一致。
3. 两阶段编辑:兼顾结构与细节的高保真
VoxHammer基于预训练模型TRELLIS的两阶段架构,实现“先定结构、再补细节”的编辑逻辑:
- 结构阶段(ST):先处理3D模型的稀疏结构(如角色的骨骼、家具的框架),确保编辑区域的结构与整体匹配(比如给角色加翅膀时,翅膀与身体的连接结构合理);
- 稀疏潜在阶段(SLAT):再优化细粒度细节(如翅膀的羽毛纹理、衣服的褶皱),让编辑部分的细节质量与原始模型保持统一,避免“结构连贯但细节粗糙”的问题。
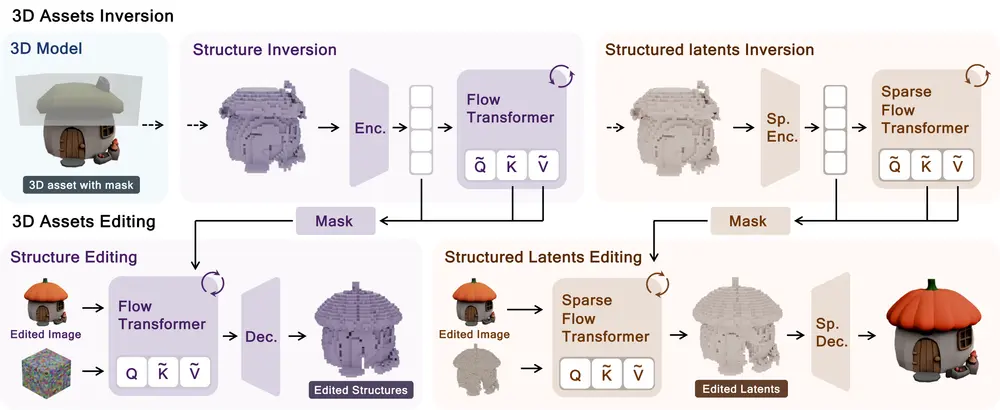
工作原理:四步完成3D模型的精准编辑
VoxHammer的工作流程清晰,从输入到输出可分为四个核心步骤,全程在3D潜在空间中完成:
- 输入接收:获取用户提供的原始3D模型、指定编辑区域(如通过坐标标注“角色上衣区域”)、编辑参考(文本提示或2D参考图);
- 3D反转与特征缓存:基于预训练模型TRELLIS,反向推演原始3D模型的扩散过程,记录每个时间步的潜在表示和键值令牌,缓存至数据库;
- 去噪与特征替换:从“终止噪声”开始去噪,生成编辑后的内容:
- 编辑区域:结合文本/图像参考,生成符合需求的新潜在特征;
- 未编辑区域:直接替换为缓存的原始潜在特征和键值令牌;
- 输出编辑结果:将处理后的潜在特征转换为可使用的3D模型格式(如GLB),完成编辑。
测试表现:多维度领先,用户认可度高
为验证VoxHammer的性能,研究团队不仅采用了常规评估指标,还构建了专门的3D编辑基准数据集Edit3D-Bench(包含100个高质量3D模型,每个模型都有详细的编辑提示和人工标注的编辑区域),测试结果全面优于现有方法:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...