
Stability AI在今天发布了一款名为 Stable Virtual Camera 的新 AI 模型,能够将 2D 图像转化为具有真实深度和视角的“沉浸式”视频。这一创新工具为数字电影制作和 3D 动画开辟了新的可能性,将生成式 AI 与虚拟相机技术相结合,提供了更大的控制力和可定制性。

当前版本的 Stable Virtual Camera 是一个研究预览版,可在非商业许可下供研究使用。用户可以从 Hugging Face 下载模型权重,并在 GitHub 上访问代码。
- GitHub:https://github.com/Stability-AI/stable-virtual-camera
- 模型:https://huggingface.co/stabilityai/stable-virtual-camera
功能亮点
动态相机控制
Stable Virtual Camera 支持用户定义的相机轨迹和多种动态相机路径,包括:
- 360° 全景
- ∞ 形路径(Lemniscate)
- 螺旋
- 变焦推入和变焦拉出
- 放大、缩小、前移、后移
- 上移、下移、左移、右移和旋转
这些功能让用户能够轻松生成沿着复杂路径移动的视频,创造出极具视觉冲击力的效果。
灵活输入
该模型可以从单张输入图像或最多 32 张图像生成 3D 视频,提供了极大的灵活性。无论是从一张照片还是多张图像中提取信息,Stable Virtual Camera 都能生成一致且平滑的 3D 视频输出。
多种宽高比
Stable Virtual Camera 支持生成方形(1:1)、竖屏(9:16)、横屏(16:9)以及其他自定义宽高比的视频,无需额外训练。这一特性使其能够满足不同场景和平台的需求。
长视频生成
该模型能够生成高达 1000 帧的视频,确保 3D 一致性,支持无缝循环和平滑过渡。即使重新访问相同视角,视频也能保持高质量和连贯性。
技术细节
模型架构
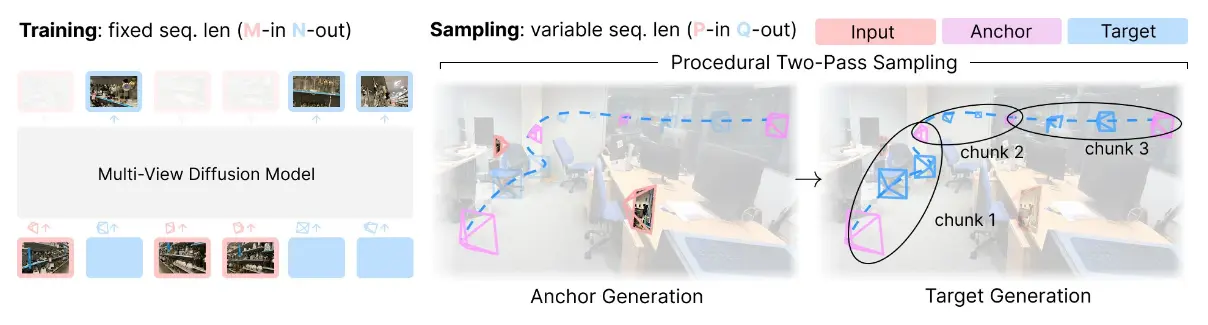
Stable Virtual Camera 是一个多视角扩散模型,训练时使用固定序列长度和一组固定的输入及目标视角(M-in, N-out)。在采样时,它作为一个灵活的生成渲染器运行,适应可变的输入和输出长度(P-in, Q-out)。这一过程通过两步采样程序实现:首先生成锚视角,然后分块渲染目标视角,以确保平滑一致的结果。
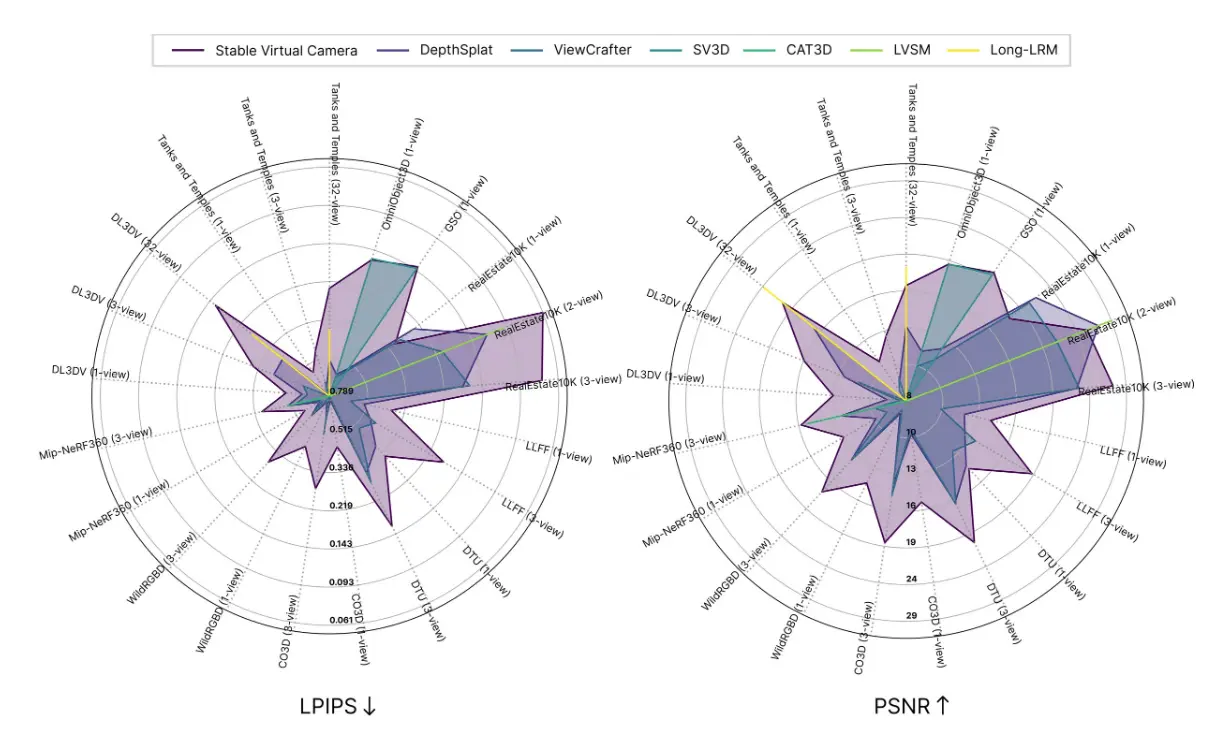
性能表现
在新颖视角合成(NVS)基准测试中,Stable Virtual Camera 取得了最先进的成果,超越了 ViewCrafter 和 CAT3D 等模型。它在大视角 NVS(强调生成能力)和小视角 NVS(优先考虑时间平滑性)中均表现出色。
模型局限性
尽管 Stable Virtual Camera 提供了许多强大的功能,但在某些场景下可能会生成较低质量的结果。具体问题包括:
- 动态纹理:包含人类、动物或像水这样的动态纹理的输入图像可能导致输出质量下降。
- 复杂相机路径:高度模糊的场景、与物体或表面相交的复杂相机路径以及不规则形状的物体可能会导致闪烁伪影,尤其是在目标视角与输入图像差异较大时。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











