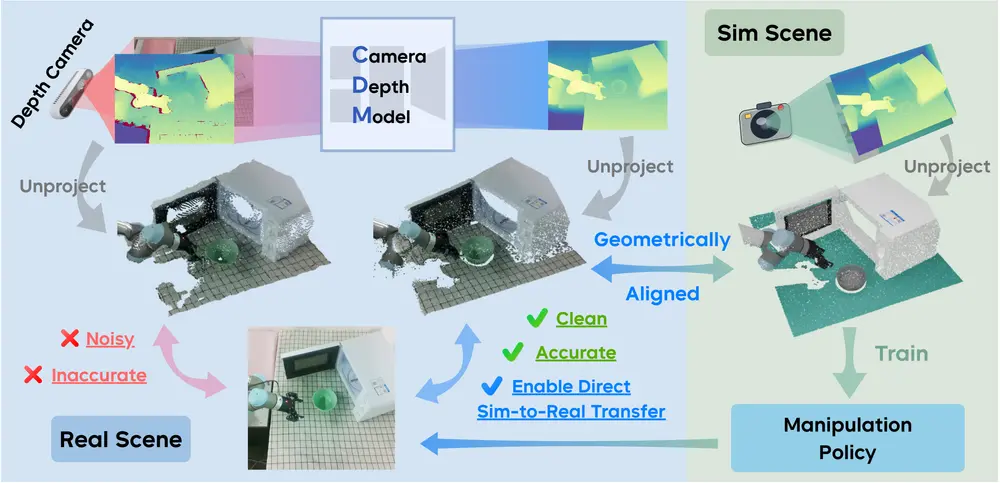
CDMs:让机器人“看清”三维世界,实现从仿真到现实的无缝迁移在机器人技能学习中,视觉感知是决策与操作的基础。然而,当前大多数方法依赖2D彩色图像作为输入——这种模式虽能捕捉纹理和颜色,却难以准确理解物体的距离、大小、形状等关键几何信息。 相比之下,人类在与环境...多模态模型# CDMs# 机器人5个月前0890
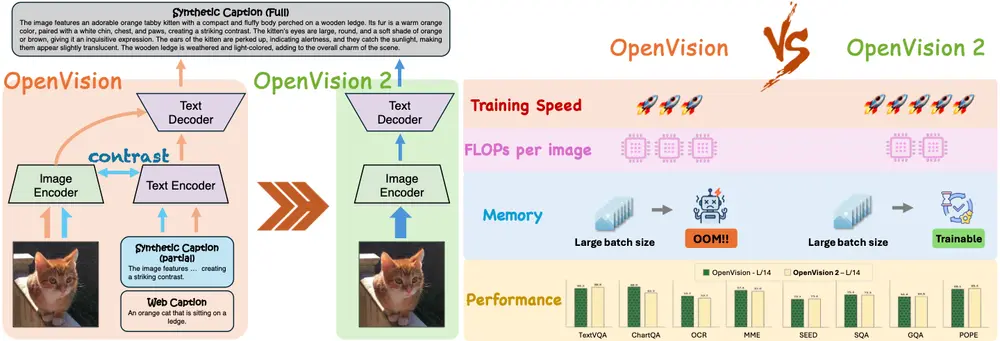
OpenVision 2:更高效、更对齐的生成式视觉编码器在多模态大模型(MLLM)快速发展的今天,一个核心问题日益凸显:预训练视觉编码器的训练方式是否真的适配下游任务? 传统方法依赖图像-文本对比学习(如 CLIP),但这类模型在接入 LLM 进行微调时...多模态模型# OpenVision 2# 视觉编码器5个月前01490
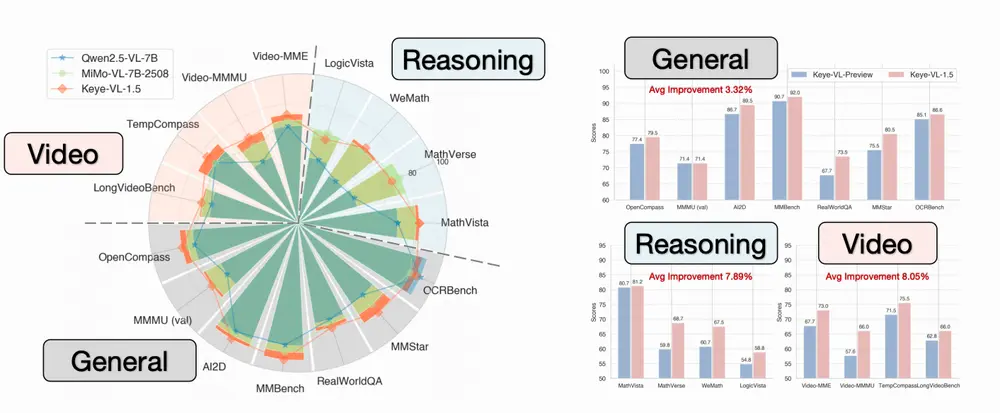
快手 Keye 团队发布Keye-VL-1.5 :支持 128K 上下文的视频理解大模型在多模态大模型的竞争中,视频理解正成为下一个关键战场。相比图像,视频包含更丰富的时空信息——动作的起止、事件的因果、场景的演变。要让AI真正“看懂”一段视频,不仅需要识别画面内容,还要理解时间逻辑与行...多模态模型# Keye-VL-1.5# 快手# 视频理解大模型5个月前0710
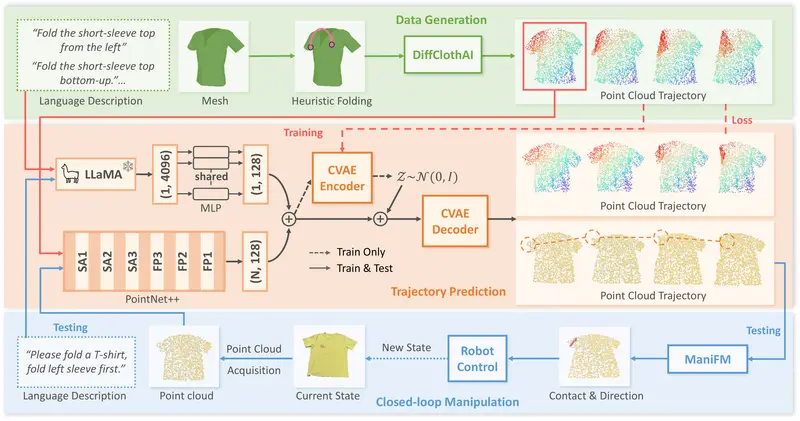
MetaFold:用语言指导机器人叠衣服,还能通用于不同衣物让机器人叠衣服,听起来简单,做起来极难。 布料柔软、易变形,同一件T恤每次摆放的形态都不同。这种高度的可变性使得机器人难以像抓取刚性物体那样,靠预设动作完成操作。更别说还要应对不同款式——无袖、短袖...多模态模型# MetaFold5个月前0880
蚂蚁集团开源医学智能体MedResearcher-R1:以知识引导技术破解领域AI推理难题蚂蚁集团正式开源医学智能体 MedResearcher-R1,同时对外公开模型及合成数据生成方法。这一智能体聚焦医学领域AI推理的核心痛点,通过“知识图谱构建-轨迹生成-评估验证”的全流程框架,为领域...多模态模型# MedResearcher-R1# 医学智能体# 蚂蚁集团5个月前0800
苹果发布 MobileCLIP2:更小、更快、更高效的移动端多模态模型苹果近期推出了新一代轻量级图像-文本模型家族 —— MobileCLIP2,在保持高精度的同时,显著降低模型体积与推理延迟,专为移动设备上的实时多模态理解任务而设计。 GitHub:https://g...多模态模型# MobileCLIP2# 图像-文本模型# 苹果5个月前0760
苹果推出视觉语言模型FastVLM:用更少的视觉 Token,更快理解高分辨率图像苹果近期发布了 FastVLM系列视觉语言模型,并首次引入其自研混合视觉编码器 FastViTHD。该模型解决当前多模态系统在处理高分辨率图像时面临的效率瓶颈,尤其在移动端和实时交互场景中展现出显著优...多模态模型# FastVLM# 苹果# 视觉语言模型5个月前0850
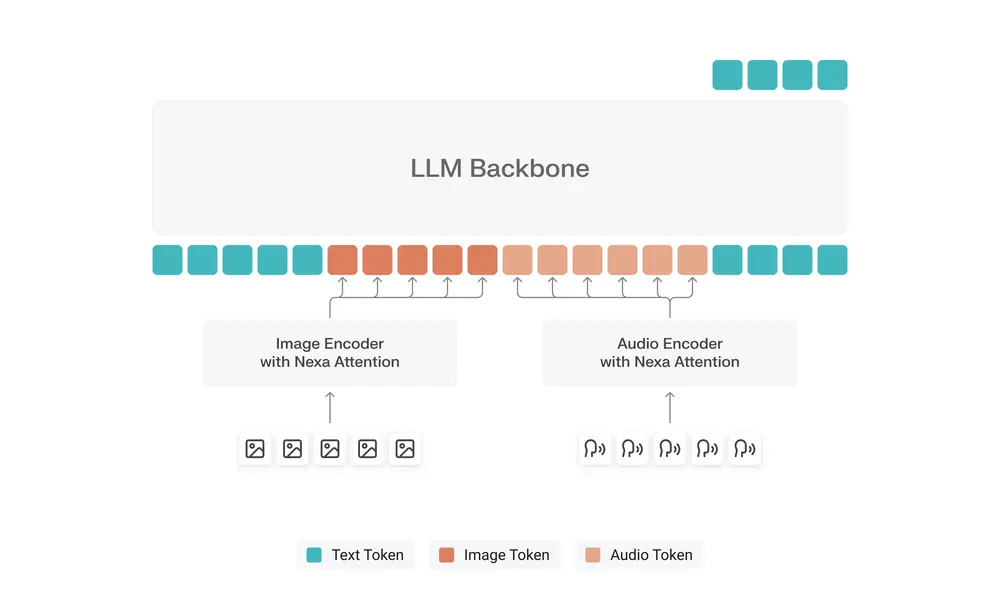
NEXA AI推出OmniNeural-4B:全球首个为 NPU 原生设计的多模态 AI 模型当AI模型需要在手机、PC等终端设备上处理文本、图像、音频时,“速度慢、耗电高、依赖网络”往往是难以回避的问题——多数模型最初为GPU设计,移植到终端的NPU(神经网络处理单元)时需“强行适配”,导致...多模态模型# Nexa AI# NPU# OmniNeural-4B5个月前0940
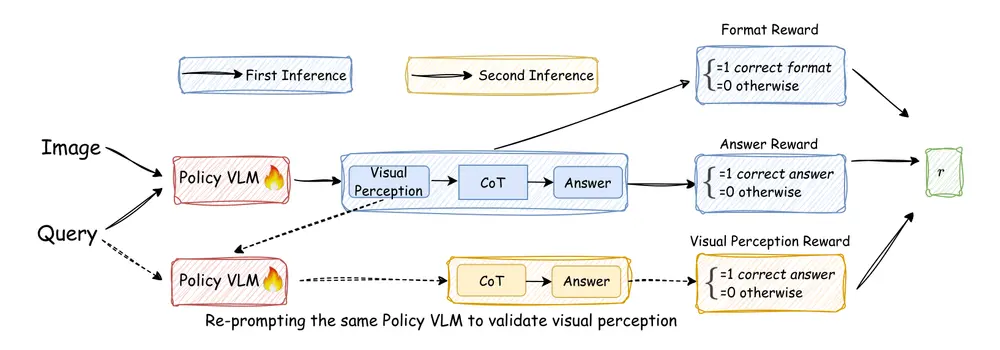
腾讯AI实验室联合两校发布Vision-SR1:自我奖励+推理分解,破解VLM视觉推理难题腾讯AI实验室联合马里兰大学帕克分校、华盛顿大学圣路易斯分校的研究团队,共同发布了新型视觉-语言模型(VLM)——Vision-SR1。该模型聚焦于解决传统VLM的核心痛点,通过创新的“自我奖励机制...多模态模型# Vision-SR1# 视觉-语言模型5个月前02440
面壁智能发布 MiniCPM-V 4.5:8B 参数模型实现多模态能力新突破面壁智能正式推出其最新视觉语言模型 MiniCPM-V 4.5,这是 MiniCPM-V 系列中性能最强、功能最全面的版本。该模型在保持 80 亿参数规模的前提下,实现了在视觉理解、视频处理、文档解析...多模态模型# MiniCPM-V 4.5# 面壁智能5个月前05460
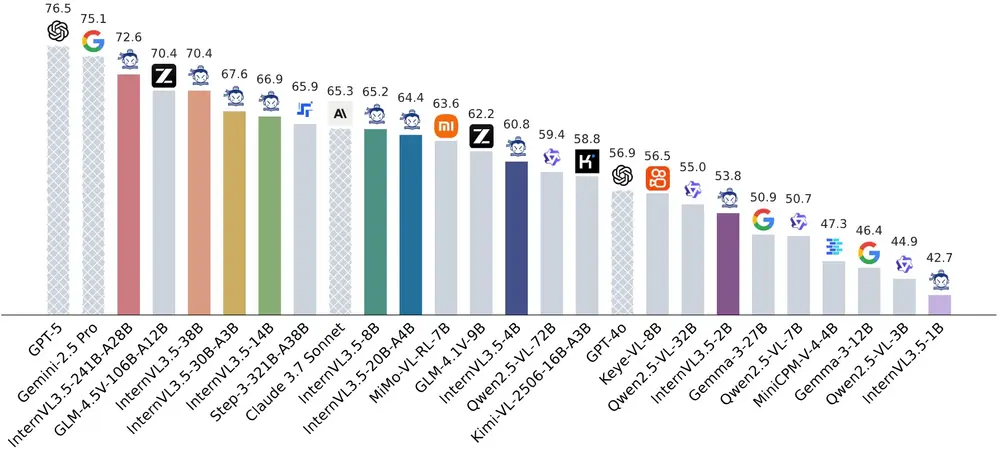
上海AI实验室InternVL项目组发布多模态大语言模型系列InternVL3.5上海AI实验室InternVL项目组推出 InternVL3.5,这是一个开源的多模态大语言模型(MLLM)系列,旨在提升模型在多功能性、推理能力和效率方面的表现。 GitHub:https://gi...多模态模型# InternVL3.5# 上海AI实验室5个月前01240
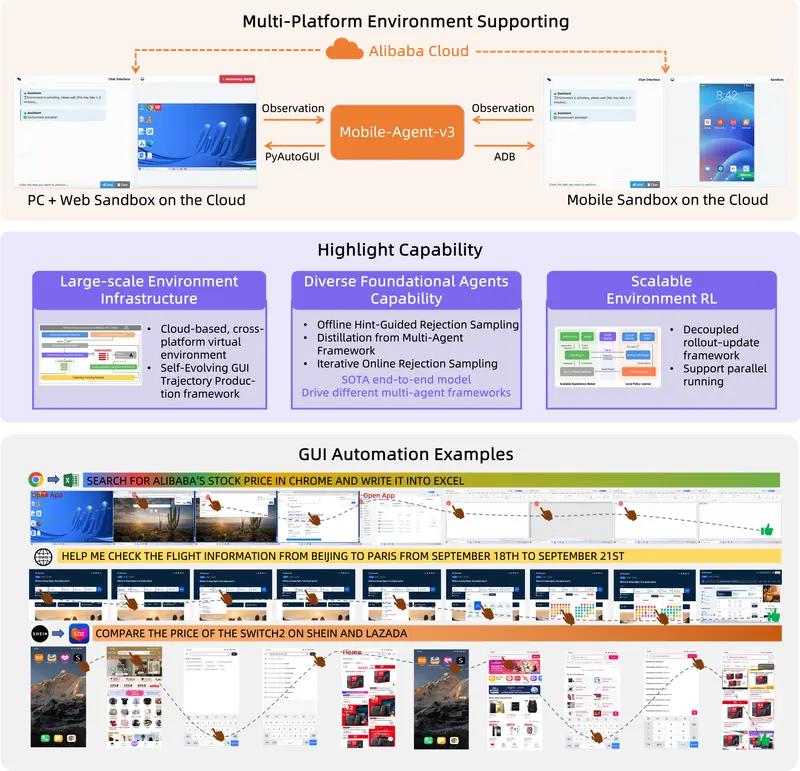
阿里通义实验室推出 Mobile-Agent-v3 框架:为图形用户界面(GUI)任务的自动化带来了全新的解决方案在当今数字化时代,自动化技术的发展日新月异。阿里通义实验室作为行业内的创新先锋,于近期推出了令人瞩目的Mobile-Agent-v3框架,为图形用户界面(GUI)任务的自动化带来了全新的解决方案。 G...多模态模型# Mobile-Agent-v3# 图形用户界面# 通义实验室5个月前09380