视频多模态大语言模型RynnEC:专为具身认知任务设计阿里达摩院、湖畔实验室和浙江大学的研究人员推出视频多模态大语言模型RynnEC,专为具身认知任务设计。它通过结合区域编码器和掩码解码器,能够灵活地处理视频中的区域级交互,从而为具身代理提供对物理世界的...多模态模型# RynnEC# 视频多模态大语言模型5个月前0930
Thyme:会生成代码的多模态模型,突破“图像思考”边界由快手联合中科院自动化所、南京大学、清华大学、中国科学技术大学共同研发的Thyme,重新定义了视觉多模态模型的能力边界。它不再局限于传统的“用图像思考”,而是通过自主生成、执行代码,完成多样化的图像处...多模态模型# Thyme# 多模态模型5个月前01200
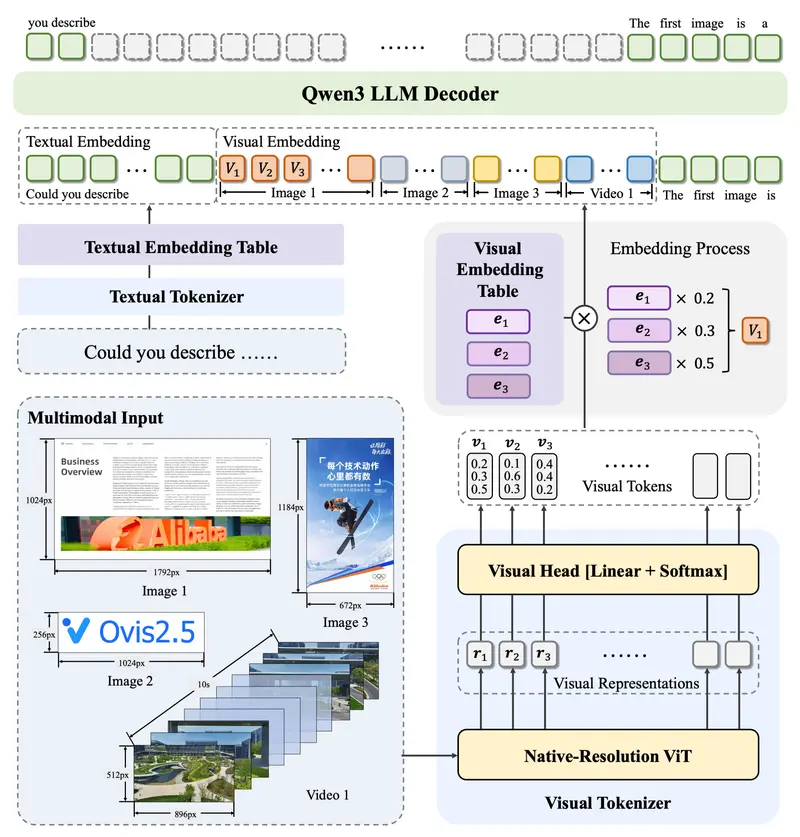
阿里国际发布多模态大语言模型Ovis2.5:原生分辨率视觉感知与深度推理的双重突破阿里国际正式推出 Ovis2.5 —— Ovis2 的继任者,一款在原生分辨率视觉理解和多模态推理能力上实现显著跃升的开源多模态大语言模型(MLLM)。 GitHub:https://github.c...多模态模型# Ovis2.5# 多模态大语言模型# 阿里国际6个月前03050
视觉语言模型ClipTagger-12B:开源视频理解新标杆,性能对标 GPT-4.1,成本低至 1/15程序化视频理解正在成为构建智能视觉系统的基础设施。从内容审核到自动化标注,从辅助功能到视频搜索引擎,开发者需要一种高效、可靠的方式,将原始视频帧转化为结构化、可搜索、可操作的数据。 为此,Infere...多模态模型# ClipTagger-12B# 视觉语言模型6个月前04390
基于多模态大语言模型的高性能UI智能体UI-Venus蚂蚁集团推出基于多模态大语言模型(MLLM)的高性能UI智能体(UI Agent)UI-Venus,它仅以屏幕截图作为输入,通过强化微调(Reinforcement Fine-Tune, RFT)技术...多模态模型# UI-Venus# UI智能体6个月前02320
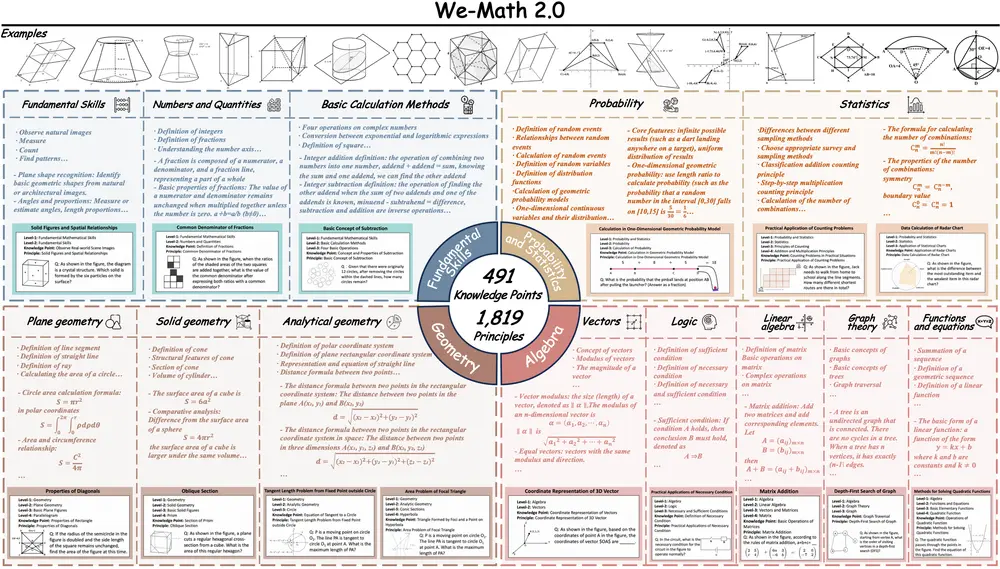
北邮、清华、腾讯联合推出 We-Math 2.0:构建有“知识体系”的数学推理智能体在当前多模态大模型(MLLM)普遍依赖数据驱动“试错式”解题的背景下,北京邮电大学、清华大学与腾讯的研究团队提出了一条不同的技术路径:让模型真正理解数学。 他们联合发布了 We-Math 2.0 ...多模态模型# We-Math 2.0# 数学推理智能体6个月前05180
字节跳动推出具备长期记忆的多模态智能体 M3-Agent字节跳动 Seed 团队推出新型多模态智能体框架M3-Agent ,首次实现了以实体为中心、支持长期记忆积累的自主推理能力。 项目主页:https://m3-agent.github.io GitHu...多模态模型# M3-Agent# 多模态智能体# 字节跳动6个月前02580
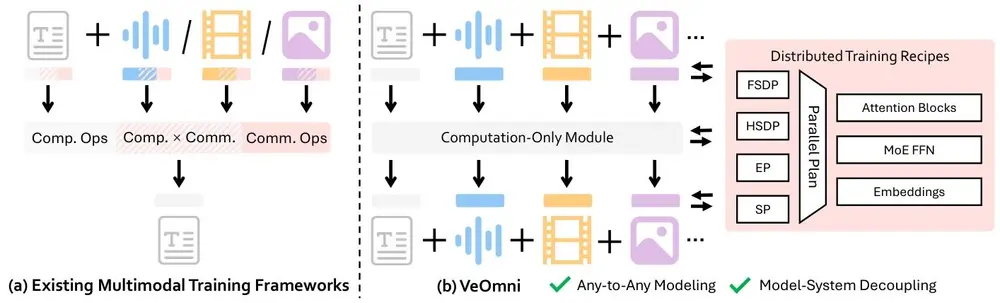
字节跳动开源 VeOmni:一个面向全模态大模型的 PyTorch 原生训练框架在大模型从“能说”向“能看、能听、能理解”演进的当下,多模态统一模型(Omni-Modal LLMs)正成为技术前沿。然而,训练一个同时处理文本、图像、语音和视频的全能模型,仍面临工程复杂、扩展困难...多模态模型# VeOmni# 多模态统一模型# 字节跳动6个月前01890
阿里通义实验室推出多模态深度研究智能体WebWatcher:通过结合视觉和语言推理能力,解决复杂的多模态信息检索问题阿里通义实验室推出多模态深度研究智能体WebWatcher,通过结合视觉和语言推理能力,解决复杂的多模态信息检索问题。 GitHub:https://github.com/Alibaba-NLP/We...多模态模型# WebWatcher# 多模态深度研究智能体6个月前02400
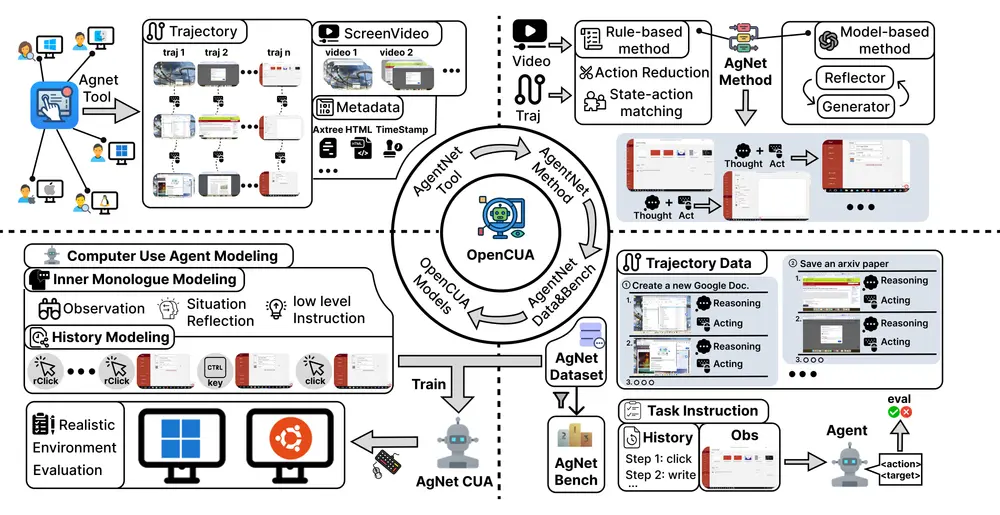
OpenCUA:首个开源的计算机使用智能体框架发布你是否曾希望有一个 AI 助手,能像你一样操作电脑——打开浏览器查资料、在 Excel 中整理数据、切换应用完成多步骤任务?如今,这类被称为“计算机使用智能体”(Computer Use Agents...多模态模型# OpenCUA# 智能体框架6个月前09220
LFM2-VL:轻量高效、面向设备端的视觉-语言模型在多模态大模型不断追求更高参数量和更强性能的当下,效率与部署可行性正成为实际应用的关键瓶颈。许多视觉-语言模型(VLM)虽在基准测试中表现优异,但其高计算成本和长推理延迟,使其难以在手机、可穿戴设备或...多模态模型# LFM2-VL# 视觉-语言模型6个月前03230
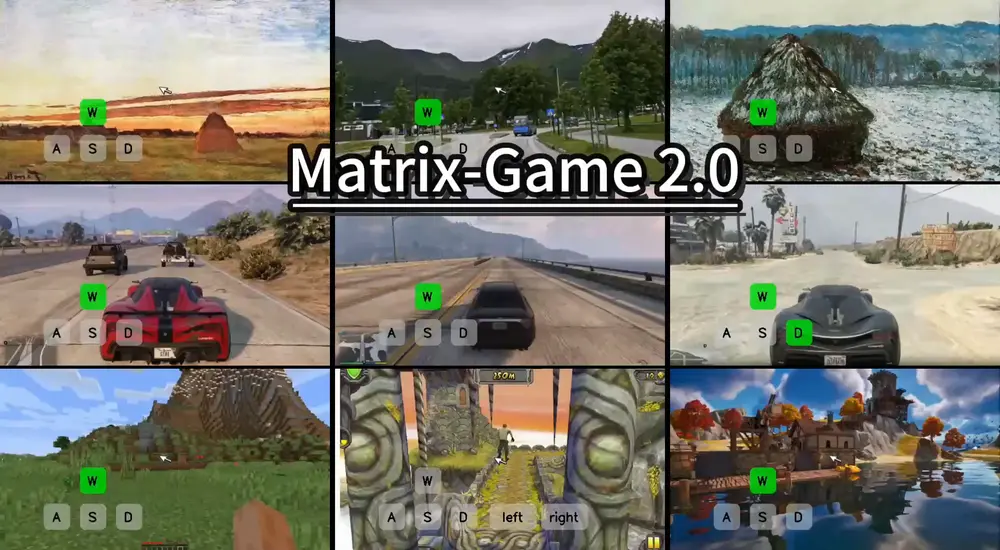
昆仑万维发布 Matrix-Game 2.0:首个开源通用交互式世界模型,把“虚拟世界”推向生产线DeepMind 最近发布的 Genie 3 让世界再次看到了“交互式世界模型”的潜力:一个模型,即可生成可玩、可控、长序列的虚拟环境。用户只需按下方向键,就能在一个由 AI 实时渲染的世界中自由探索...多模态模型# Matrix-Game 2.0# 交互式世界模型# 昆仑万维6个月前02570