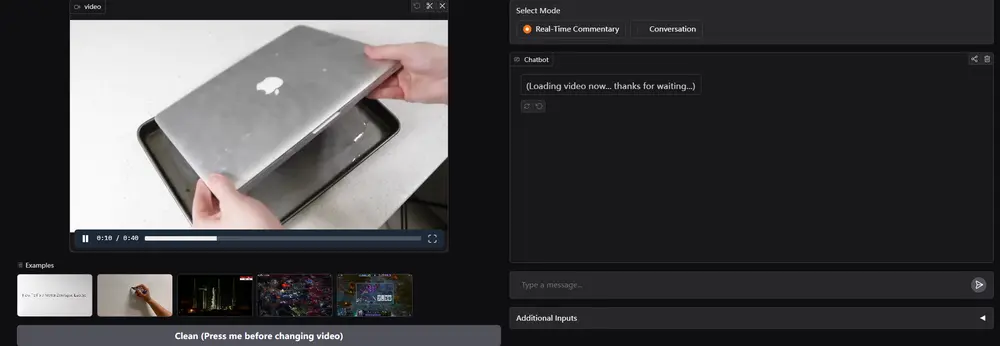
基于 Qwen2-VL-7B 开发的实时视频理解大模型LiveCC:快速分析视频内容,并同步生成自然流畅的语音或文字解说新加坡国立大学和字节跳动的研究人员推出基于 Qwen2-VL-7B 开发的实时视频理解大模型LiveCC,能够像专业解说员一样快速分析视频内容,并同步生成自然流畅的语音或文字解说。特别适合需要即时反馈...多模态模型# LiveCC# Qwen2-VL-7B# 视频理解大模型8个月前03060
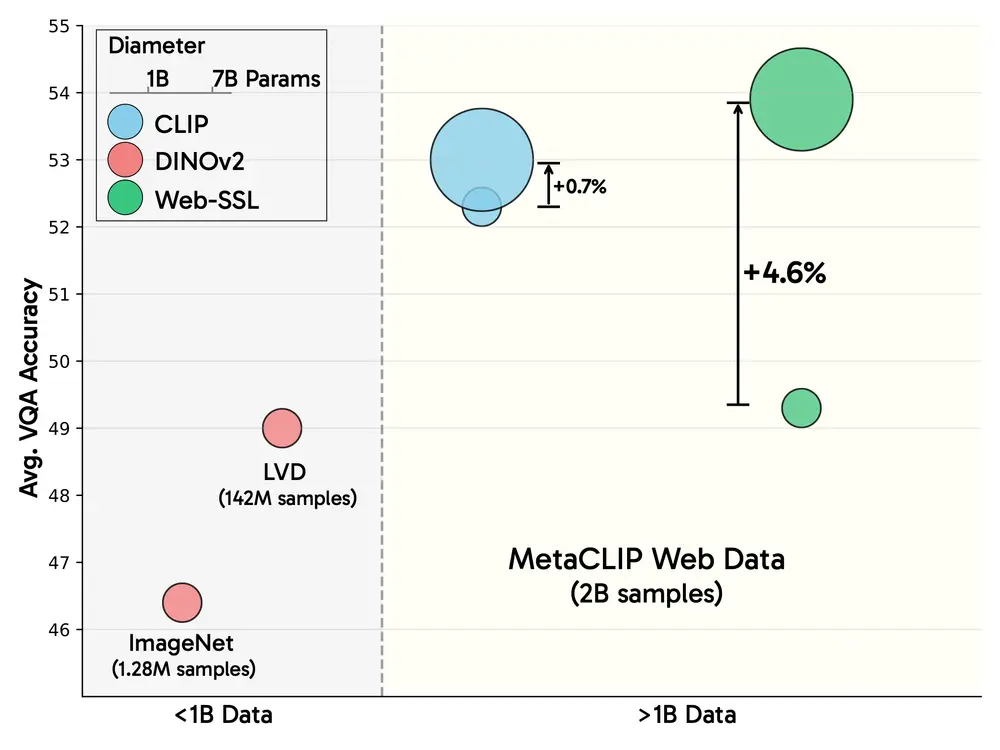
Meta发布Web-SSL系列模型:无语言也能学视觉,探索纯视觉自监督学习的潜力近年来,对比语言-图像模型(如CLIP)在多模态任务中表现出色,成为学习视觉表征的主流选择。这些模型通过大规模的图像-文本对进行训练,利用语言监督来融入语义信息,广泛应用于视觉问答(VQA)、文档理解...大语言模型# Meta# Web-SSL8个月前02260
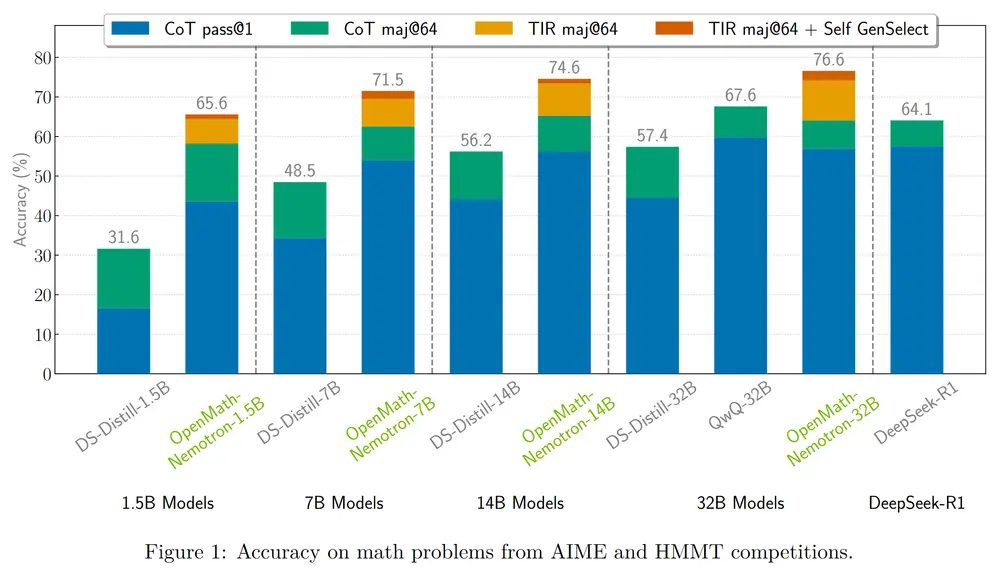
英伟达发布数学推理模型 OpenMath-Nemotron 系列,基于Qwen2.5-32B训练长期以来,数学推理一直是人工智能领域的一项重大挑战。尽管传统的语言模型在生成自然语言文本方面表现出色,但在解决需要深入领域知识和多步骤逻辑推导的复杂数学问题时,它们往往显得力不从心。为了弥合这一差距...大语言模型# OpenMath-Nemotron# Qwen2.5-32B# 数学推理模型8个月前02040
Meta AI推出一款通过单一对比学习目标训练的通用视觉编码器Perception Encoder随着AI系统逐渐向多模态方向发展,视觉感知模型的角色也变得更加复杂。传统的视觉编码器通常针对特定任务进行优化,例如图像分类、目标检测或语言生成,但这种碎片化的方法不仅增加了模型的复杂性,还限制了其在开...多模态模型# Meta AI# Perception Encoder# 感知编码器8个月前02810
IBM 首个开源的语音转文本(STT)和自动语音翻译(AST)模型Granite Speech 3.3 8B随着AI在企业系统中的深度集成,对灵活性、效率和透明度兼具的模型需求日益增加。然而,当前市场上的解决方案往往难以满足这些要求:开源模型可能缺乏特定领域的能力,而专有系统则可能限制访问或适应性。尤其在语...语音模型# AST# Granite Speech 3.3 8B# IBM8个月前03510
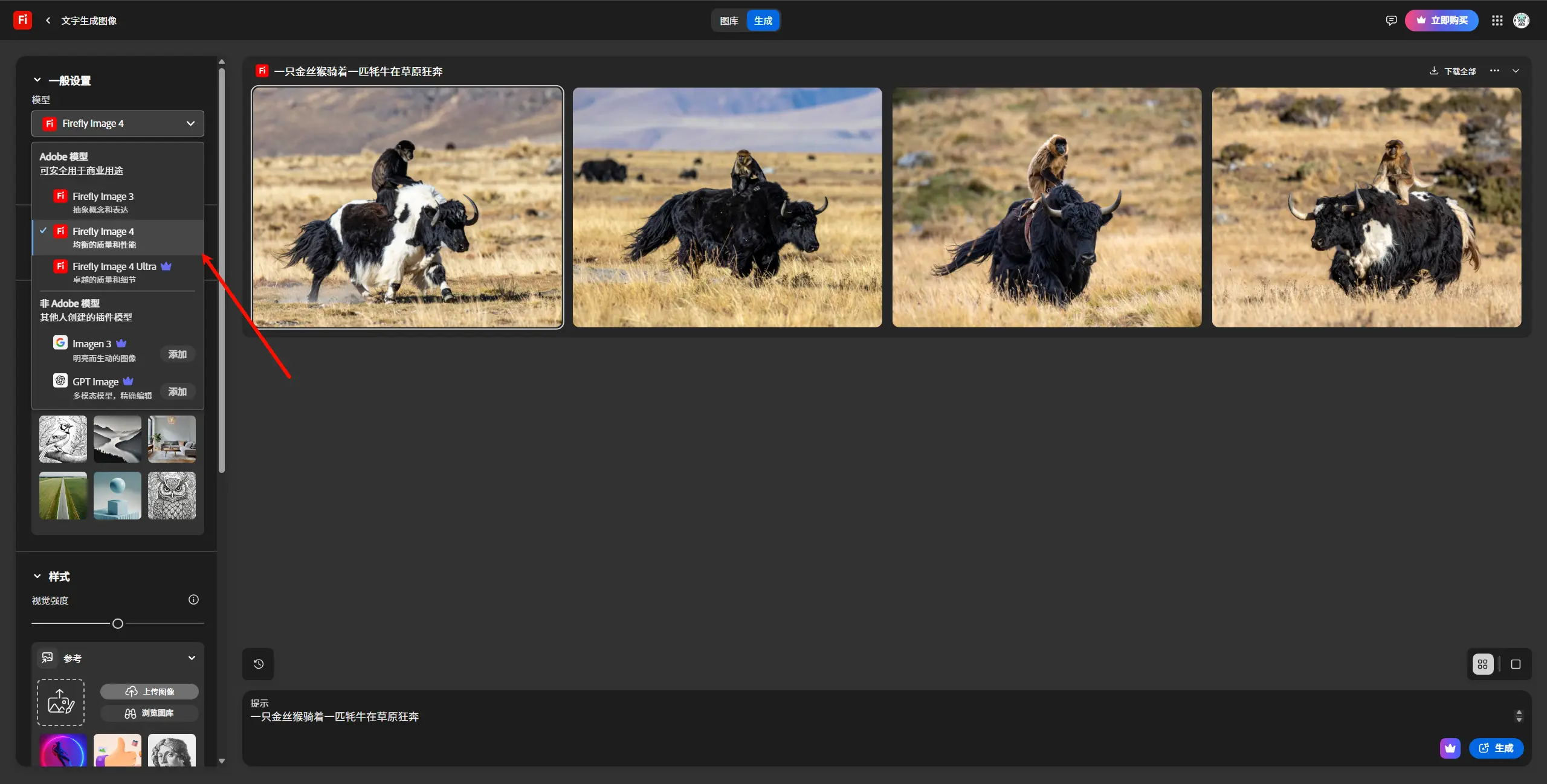
Adobe 推出 Firefly 系列新模型与重新设计的 Web 应用Adobe 在生成式 AI 领域再次迈出重要一步,推出了 Firefly 系列图像生成模型的最新迭代版本、一个全新的 矢量生成模型(Firefly Vector Model),以及一个经过重新设计的 ...图像模型# Adobe# Firefly Image 4# Image 4 Ultra8个月前03030
TNG科技微调 olmOCR推出olmOCR-7B-faithful:更忠实的 OCR 模型,适用于业务场景中的全面信息提取光学字符识别(OCR)技术在文档数字化和信息提取领域扮演着重要角色。然而,传统的基于流水线的 OCR 系统虽然功能强大,却常常因无法处理复杂布局而受到限制。最近,艾伦人工智能研究所推出的 olmOCR...多模态模型# olmOCR# olmOCR-7B-faithful8个月前02010
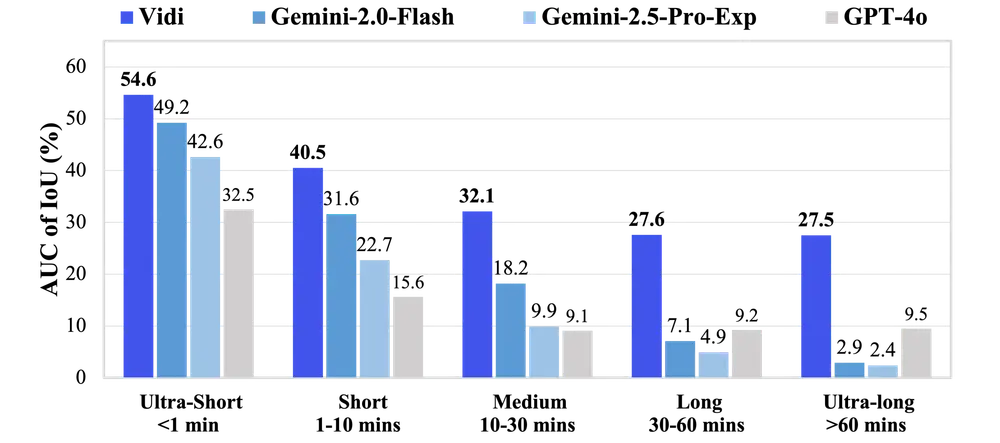
字节跳动推出多模态模型Vidi:专门用于视频理解和编辑字节跳动推出多模态模型Vidi,专门用于视频理解和编辑。Vidi 的主要目标是支持高质量、大规模视频内容的创作,通过处理原始输入材料(如未编辑的视频片段)和编辑组件(如视觉效果),帮助用户更高效地完成...多模态模型# Vidi# 多模态模型# 字节跳动8个月前01900
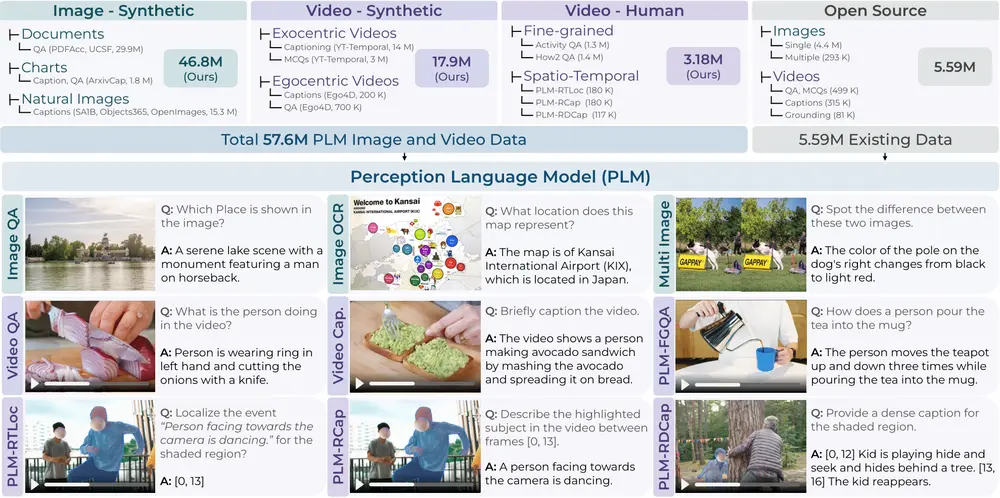
英伟达推出多模态大语言模型Describe Anything 3B:为图像和视频局部描述量身定制的多模态 AI 模型英伟达、加州大学伯克利分校和加州大学旧金山分校的研究人员推出了 Describe Anything 3B (DAM-3B),这是一个专门用于生成细粒度图像和视频字幕的多模态大语言模型(LLM)。DAM...多模态模型# Describe Anything 3B# 多模态大语言模型# 英伟达8个月前05690
Flex.2-preview:基于 Flux.1 Schnell 微调而成的开源 80 亿参数文生图模型Flex.2-preview 是一款开源的文本到图像扩散模型,具有 80 亿参数,支持通用控制和图像修复功能。它基于 Flux.1 Schnell 微调而成,旨在为用户提供更灵活、更强大的图像生成能力...图像模型# Flex.2-preview# FLUX.1 [schnell]# 文生图模型8个月前05860
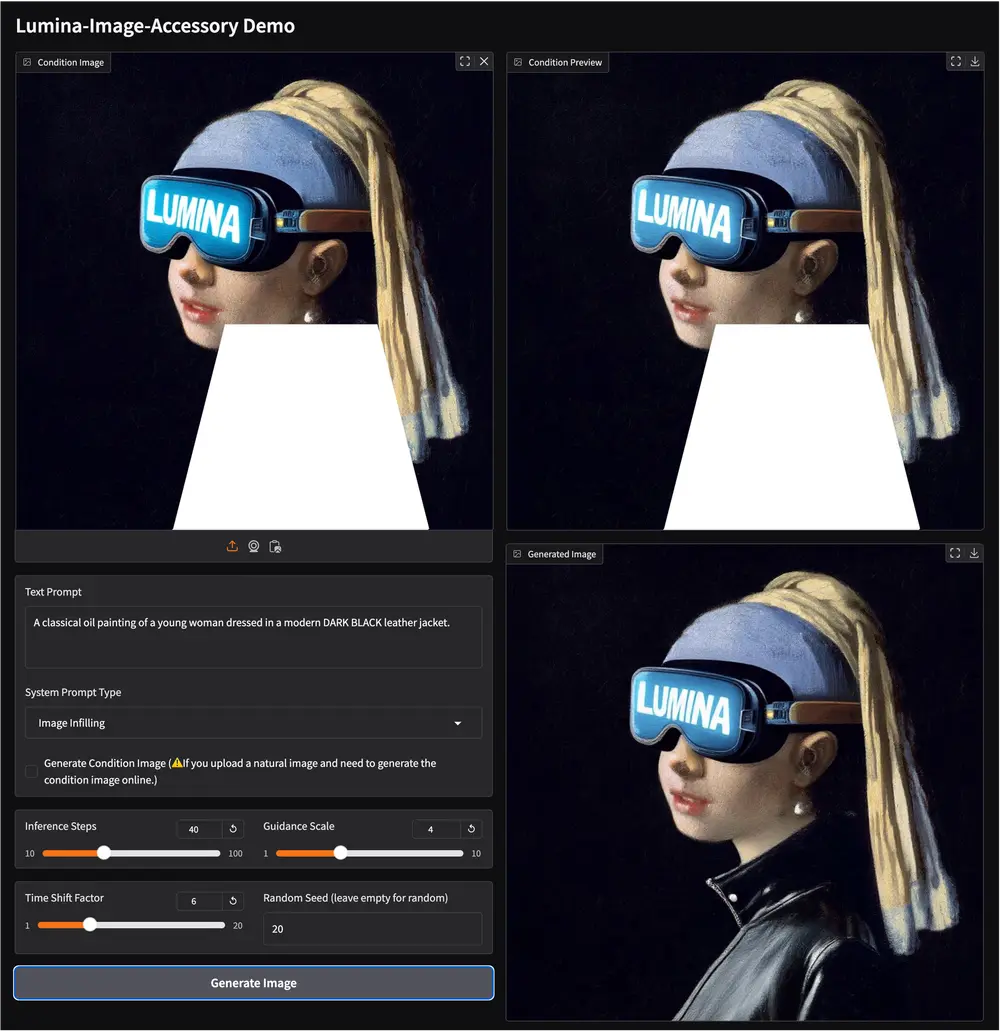
Lumina-Accessory:专为 Lumina 系列模型设计的多任务指令微调框架Lumina-Accessory 是一个专为 Lumina 系列模型设计的多任务指令微调框架,目前支持 Lumina-Image-2.0。该框架通过一系列创新设计,为图像生成和编辑任务提供了强大的支持...图像模型# Lumina-Accessory# Lumina-Image 2.0# 图像生成8个月前02900
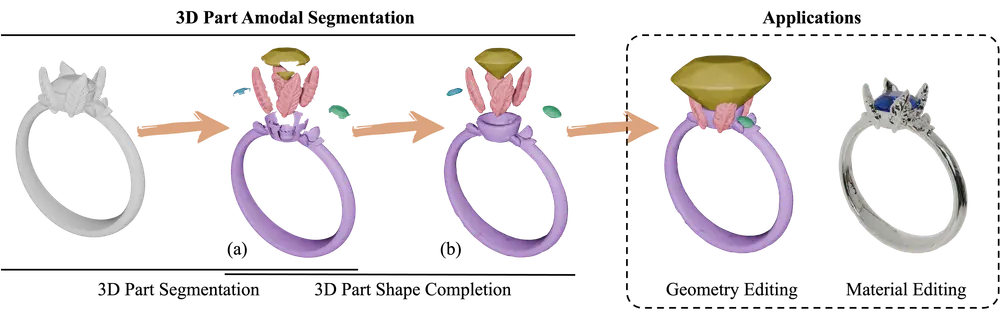
新型3D部件非模态分割模型HoloPart:将3D形状分解为完整的、语义上有意义的部件香港大学和VAST的研究人员推出新型3D部件非模态分割模型HoloPart 。该模型旨在将3D形状分解为完整的、语义上有意义的部件,即使这些部件被部分或完全遮挡。这一任务被称为 3D部件非模态分割,是...3D模型# 3D部件非模态分割模型# HoloPart8个月前04050