视觉-语言模型中的“隐形损耗”:我们如何测量图像信息的丢失?视觉-语言模型(Vision-Language Models, VLMs)如 LLaVA、Qwen-VL 等,在图像理解、视觉问答和图文生成等任务中表现优异。这些模型通常依赖一个核心流程:将图像通过视...多模态模型# 视觉-语言模型4个月前01340
百度发布 PP-OCRv5:0.07亿参数模型,挑战百亿级大模型的OCR精度在通用视觉语言模型(VLM)主导多模态任务的当下,百度飞桨团队反其道而行之,推出新一代轻量级文字识别模型 PP-OCRv5 ——一个仅含 70万参数(0.07B)的超小模型,在多项 OCR 任务中表现...多模态模型# PP-OCRv5# 百度4个月前02770
Mistral AI 发布 Magistral Small 1.2:支持视觉输入的小型高效开源推理模型法国AI初创公司 Mistral AI 本周正式发布并开源其小型语言模型的新版本 —— Magistral Small 1.2。该模型在前代基础上全面升级,不仅提升了数学与编程任务的基准表现,还首次引...多模态模型# Magistral Small 1.2# Mistral AI4个月前02230
Moondream 团队推出 Moondream 3 预览版本:轻量架构下的高性能视觉推理模型Moondream 团队正式推出 Moondream 3 的预览版本——一款基于 9B 参数稀疏混合专家(MoE)架构的新模型,实际激活参数仅为 2B。它在保持极快推理速度和低运行成本的同时,实现了接...多模态模型# Moondream 3# 视觉推理模型4个月前05000
IBM 推出 Granite Docling:专为文档转换优化的轻量级多模态模型IBM Research 正式发布 Granite Docling-258M,一款基于 IDEFICS3 架构构建的新型多模态图像-文本到文本模型,专为高效、准确的文档理解与结构化转换而设计。 Git...多模态模型# Granite Docling-258M# 多模态模型# 文档转换4个月前0880
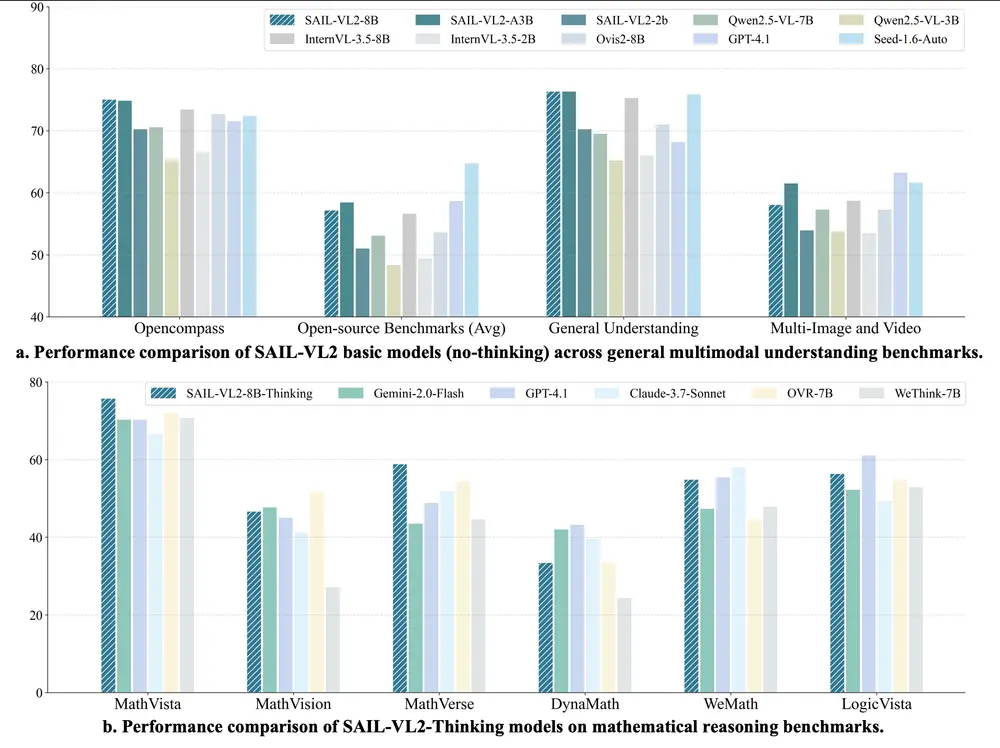
抖音推出SAIL-VL2:面向细粒度感知与复杂推理的新一代开源视觉语言模型由抖音 SAIL 团队与新加坡国立大学 LV-NUS 实验室联合研发,SAIL-VL2 是一款全新的开源视觉语言基础模型(Vision-Language Model, LVM),在 2B 和 8B 参...多模态模型# SAIL-VL2# 抖音# 视觉语言模型4个月前03100
浙大 × 通义实验室提出 UI-S1:用“半在线”训练让 MLLM 更懂图形界面在手机上完成一连串操作——比如从微信复制一段文字,粘贴到备忘录,再分享给钉钉好友——对人类来说是日常小事。但对 AI 来说,这是一次复杂的多步决策挑战。 近年来,基于多模态大语言模型(MLLM)的 G...多模态模型# UI-S1# 多模态大语言模型5个月前02650
宇树科技开源 UnifoLM-WMA-0:面向通用机器人的世界模型–动作架构宇树科技(Unitree)近日宣布开源其全新的机器人学习框架 —— UnifoLM-WMA-0,一个专为通用机器人学习设计的世界模型–动作(World Model–Action)架构。该模型跨越多种机...多模态模型# UnifoLM-WMA-0# 宇树科技5个月前01480
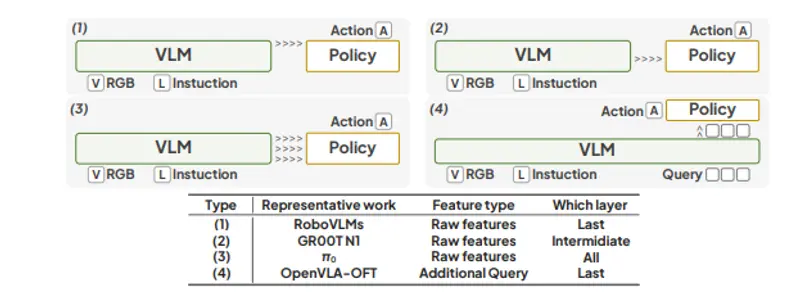
北邮、浙大等团队联合提出视觉-语言-动作模型 VLA-Adapter:用轻量桥接实现高效机器人控制在当前机器人智能领域,视觉-语言-动作(Vision-Language-Action, VLA)模型正成为连接感知与行为的核心技术。这类模型能让机器人“听懂指令”、“看懂场景”,并自主执行任务,例如...多模态模型# VLA-Adapter# 视觉-语言-动作模型5个月前03340
字节跳动 & 港大推出 Mini-o3:可扩展多轮推理的开源视觉智能体字节跳动与香港大学联合发布 Mini-o3 ——一个具备强大图像理解与长程多轮交互能力的开源多模态模型。该模型能够生成类似 OpenAI o3 风格的代理行为轨迹,在复杂视觉搜索任务中实现数十轮持续推...多模态模型# Mini-o3# 视觉智能体5个月前01990
POINTS-Reader:无需蒸馏、端到端的轻量级文档视觉语言模型腾讯、上海交通大学与清华大学联合推出 POINTS-Reader —— WePOINTS 家族最新成员,一款专为文档图像转文本设计的轻量级视觉-语言模型(VLM)。 GitHub:https://gi...多模态模型# POINTS-Reader# 文档视觉语言模型5个月前01960
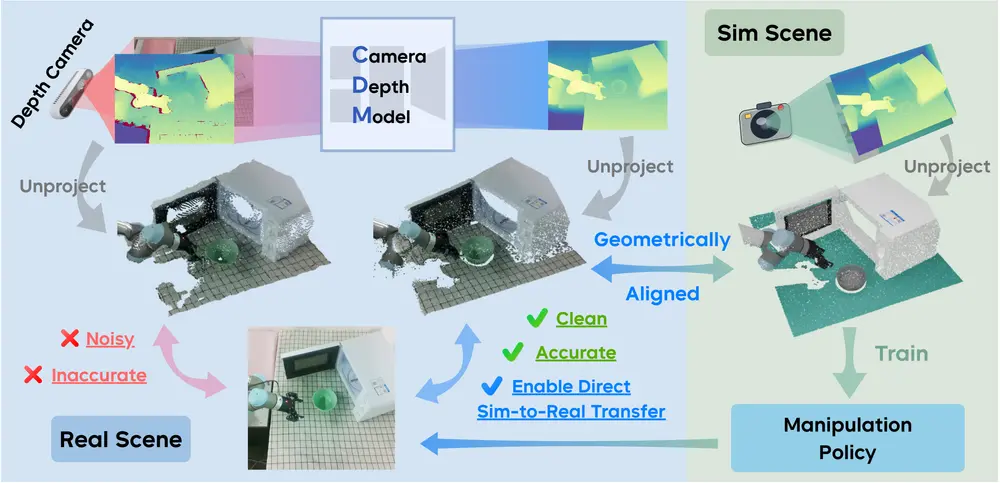
CDMs:让机器人“看清”三维世界,实现从仿真到现实的无缝迁移在机器人技能学习中,视觉感知是决策与操作的基础。然而,当前大多数方法依赖2D彩色图像作为输入——这种模式虽能捕捉纹理和颜色,却难以准确理解物体的距离、大小、形状等关键几何信息。 相比之下,人类在与环境...多模态模型# CDMs# 机器人5个月前0890