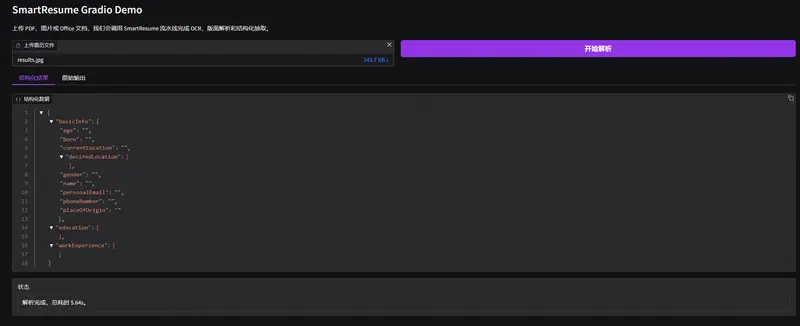
阿里巴巴推出 SmartResume:一个能“读懂”复杂简历版式的智能解析系统在企业招聘中,自动化处理海量简历是刚需,但简历格式千奇百怪——多栏排版、图文混排、表格嵌套,传统文本提取工具常会打乱语义顺序,导致关键信息错位。 针对这一难题,阿里巴巴企业智能团队发布了 SmartR...多模态模型# SmartResume# 智能简历解析# 阿里巴巴3个月前01530
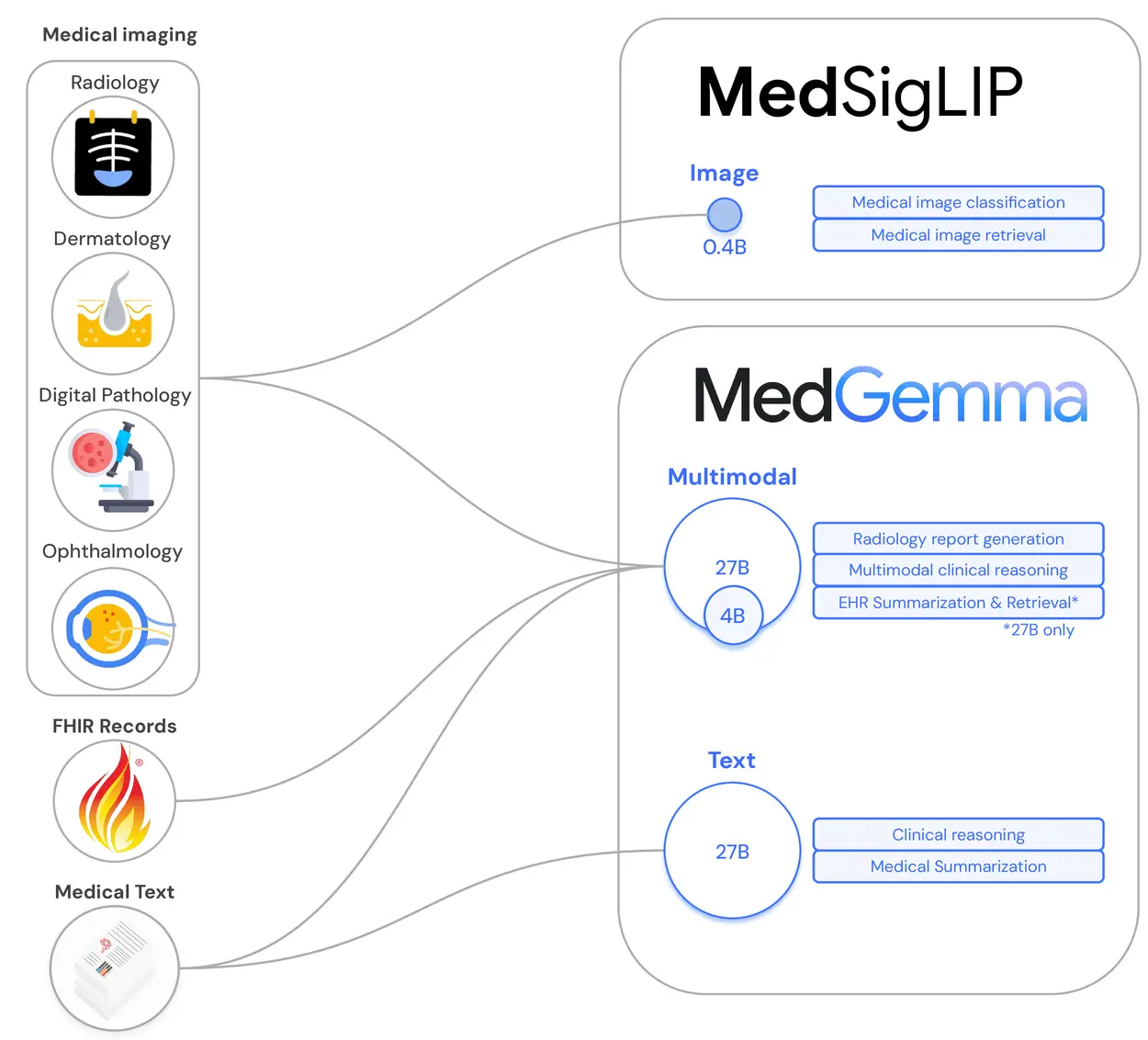
谷歌推出开源医疗 AI 模型系列MedGemma及轻量级图像编码器 MedSigLIP谷歌近日宣布推出其最新的开源医疗 AI 模型系列——MedGemma,并同时发布了轻量级图像编码器 MedSigLIP。这是继健康 AI 开发者基础(HAI-DEF)项目之后,谷歌在医疗 AI 领域迈...多模态模型# MedGemma# MedSigLIP# 谷歌7个月前01520
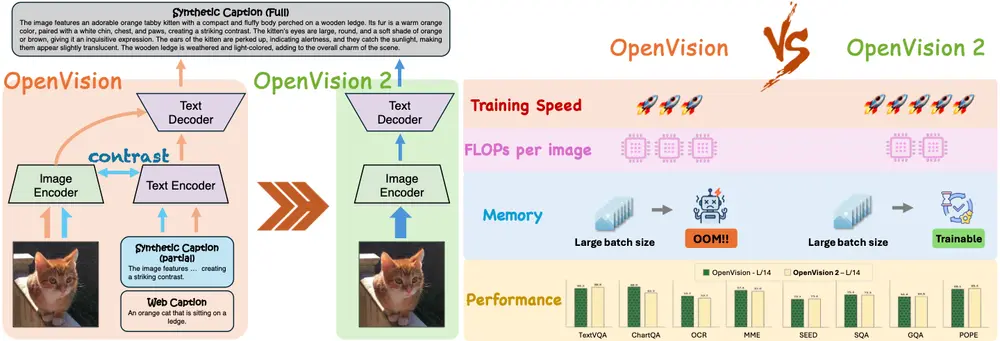
OpenVision 2:更高效、更对齐的生成式视觉编码器在多模态大模型(MLLM)快速发展的今天,一个核心问题日益凸显:预训练视觉编码器的训练方式是否真的适配下游任务? 传统方法依赖图像-文本对比学习(如 CLIP),但这类模型在接入 LLM 进行微调时...多模态模型# OpenVision 2# 视觉编码器5个月前01490
宇树科技开源 UnifoLM-WMA-0:面向通用机器人的世界模型–动作架构宇树科技(Unitree)近日宣布开源其全新的机器人学习框架 —— UnifoLM-WMA-0,一个专为通用机器人学习设计的世界模型–动作(World Model–Action)架构。该模型跨越多种机...多模态模型# UnifoLM-WMA-0# 宇树科技5个月前01480
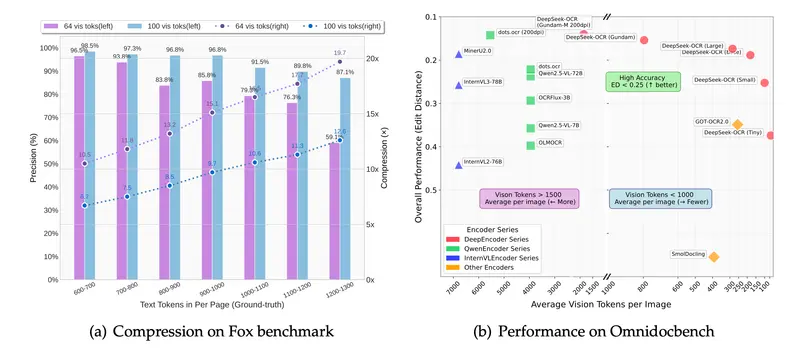
DeepSeek 开源DeepSeek-OCR :用视觉模态压缩文本,3B 小模型撬动长上下文新思路DeepSeek 开源了 DeepSeek-OCR,一个仅 30 亿参数的视觉语言模型(VLM),却在 OCR 与文本压缩领域展现出令人瞩目的创新力。其核心并非追求更大参数量,而是提出一种“光学压缩...多模态模型# DeepSeek# DeepSeek-OCR3个月前01410
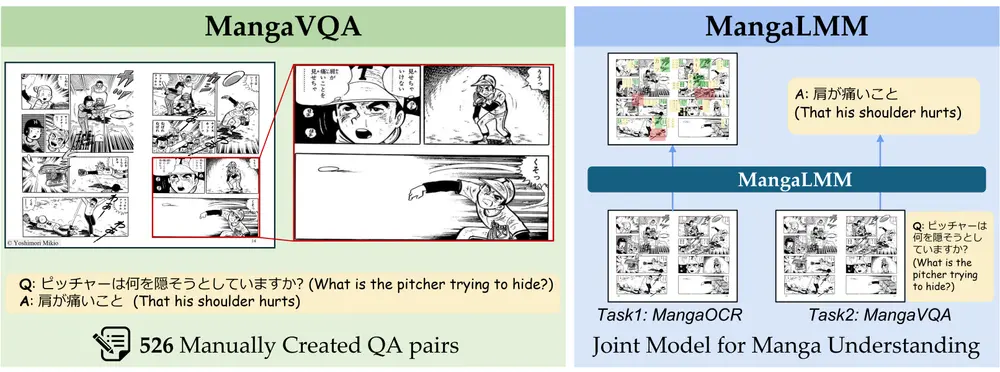
东京大学推出基准测试MangaVQA和多模态漫画理解模型MangaLMM东京大学的研究人员推出一个名为 MangaVQA 的基准测试和一个名为 MangaLMM 的专门模型,用于多模态漫画理解。漫画(Manga)是一种将图像和文本以复杂方式结合的叙事形式,理解漫画需要同时...多模态模型# MangaLMM# MangaVQA# 东京大学6个月前01410
视觉-语言模型中的“隐形损耗”:我们如何测量图像信息的丢失?视觉-语言模型(Vision-Language Models, VLMs)如 LLaVA、Qwen-VL 等,在图像理解、视觉问答和图文生成等任务中表现优异。这些模型通常依赖一个核心流程:将图像通过视...多模态模型# 视觉-语言模型4个月前01340
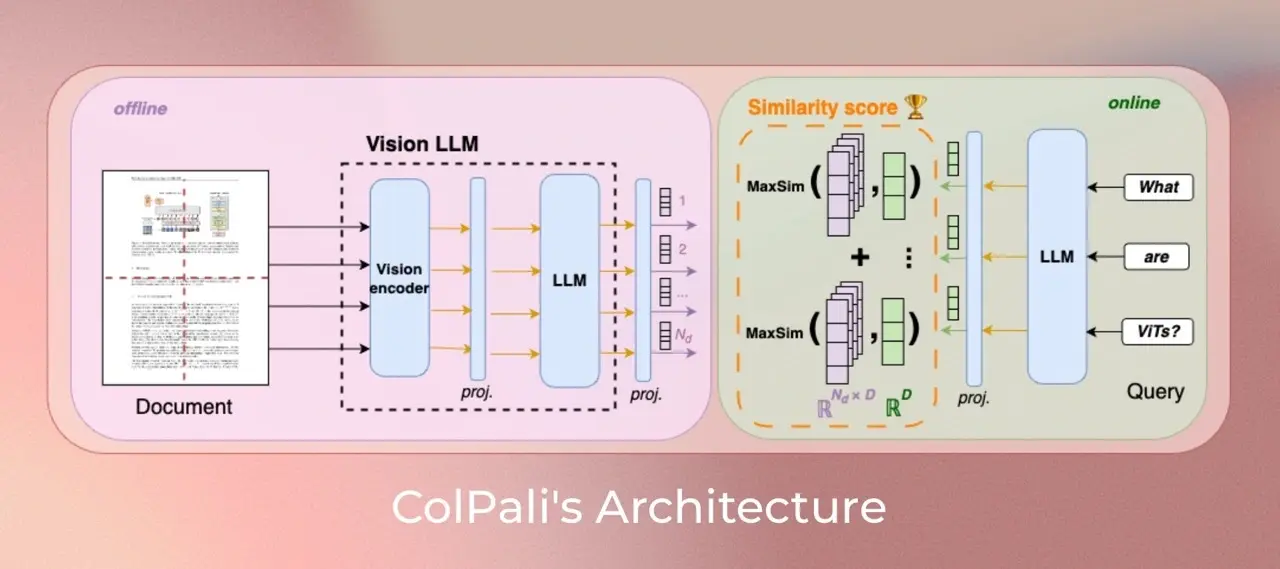
ColPali:基于视觉语言模型的新型高效文档检索系统由 Illuin科技、Equall.ai、巴黎-萨克雷大学和苏黎世联邦理工学院 联合提出,ColPali 是一种基于视觉语言模型(VLMs)的文档检索模型,能够直接从文档图像中提取信息,实现快速、准确...多模态模型# ColPali# 文档检索7个月前01310
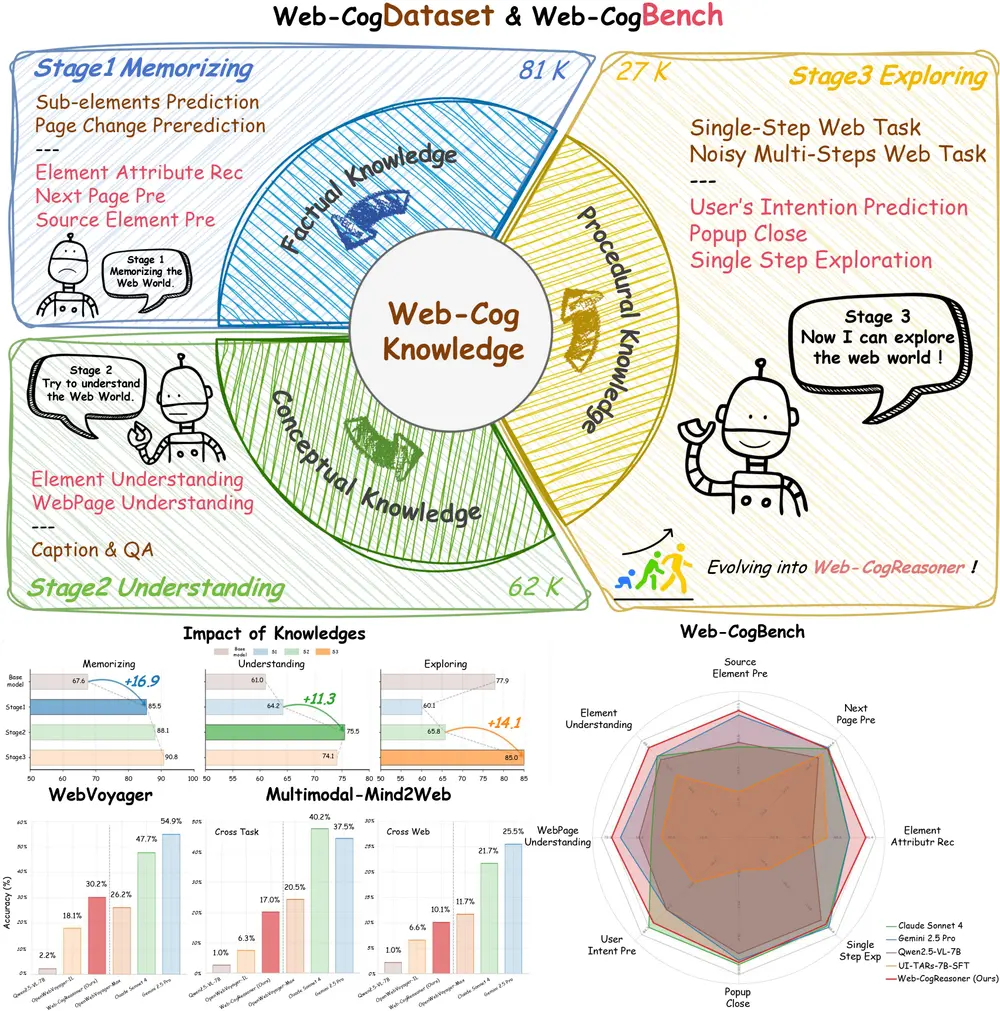
多模态智能体的“认知升级”:Web-CogReasoner 如何让网络代理真正“会思考”联合研究团队:西南财经大学、上海交通大学、中南大学、Hithink研究院、西湖大学、哈尔滨工业大学、曼彻斯特大学、加州大学洛杉矶分校、阿德莱德大学、复旦大学、中国科学院深圳先进技术研究院 当AI开始替...多模态模型# Web-CogReasoner# 多模态智能体6个月前01280
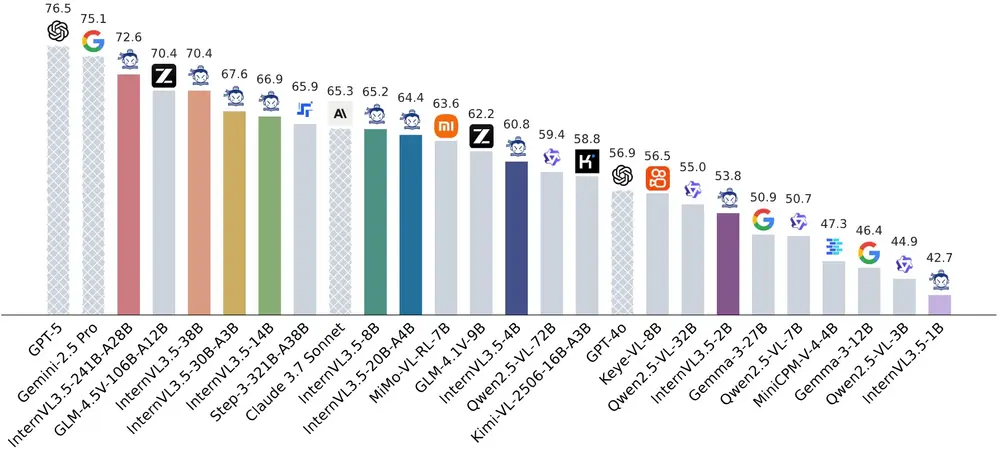
上海AI实验室InternVL项目组发布多模态大语言模型系列InternVL3.5上海AI实验室InternVL项目组推出 InternVL3.5,这是一个开源的多模态大语言模型(MLLM)系列,旨在提升模型在多功能性、推理能力和效率方面的表现。 GitHub:https://gi...多模态模型# InternVL3.5# 上海AI实验室5个月前01260
字节跳动发布Vidi2:攻克细粒度时空定位,视频检索性能领先GPT - 5字节跳动智能创作团队推出的第二代多模态视频模型Vidi2,凭借在时空定位、时间检索和视频问答三大核心能力上的突破,打破了传统视频模型在长视频理解和精细交互上的局限。该模型不仅在核心任务中实现对Gemi...多模态模型# Vidi2# 多模态视频模型# 字节跳动2个月前01200
Thyme:会生成代码的多模态模型,突破“图像思考”边界由快手联合中科院自动化所、南京大学、清华大学、中国科学技术大学共同研发的Thyme,重新定义了视觉多模态模型的能力边界。它不再局限于传统的“用图像思考”,而是通过自主生成、执行代码,完成多样化的图像处...多模态模型# Thyme# 多模态模型5个月前01200