Cohere 推出 Command A Vision:专为企业打造的高效多模态 AI今天,AI 不再只是“读文字”的工具。越来越多的企业需要系统能“看懂”图像——从产品手册、工程图纸到财务报表、现场照片。 为此,Cohere 正式发布 Command A Vision —— 一款专为...多模态模型# Cohere# Command A Vision6个月前01170
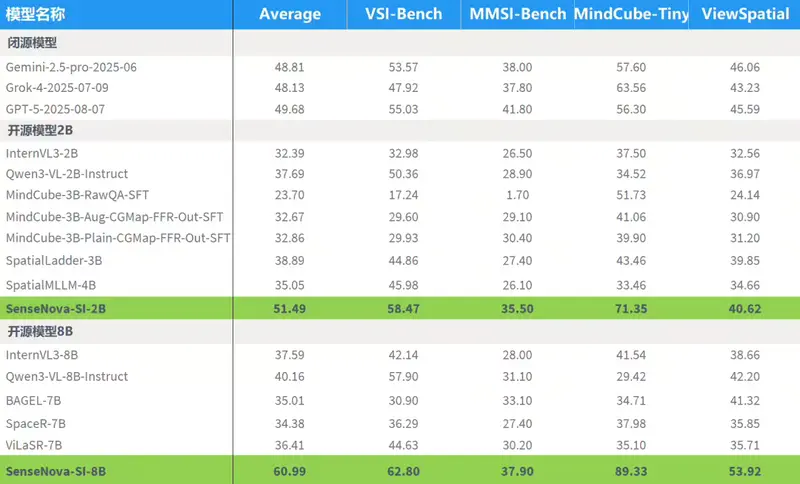
商汤开源SenseNova-SI:面向空间智能的多模态模型当前主流多模态基础模型在文本、图像理解、推理和生成任务上已取得显著进展,但在空间智能(Spatial Intelligence)方面仍存在系统性短板。具体表现为: 对物体尺度、距离、比例的估计不准确 ...多模态模型# SenseNova-SI# 商汤# 空间智能3个月前01140
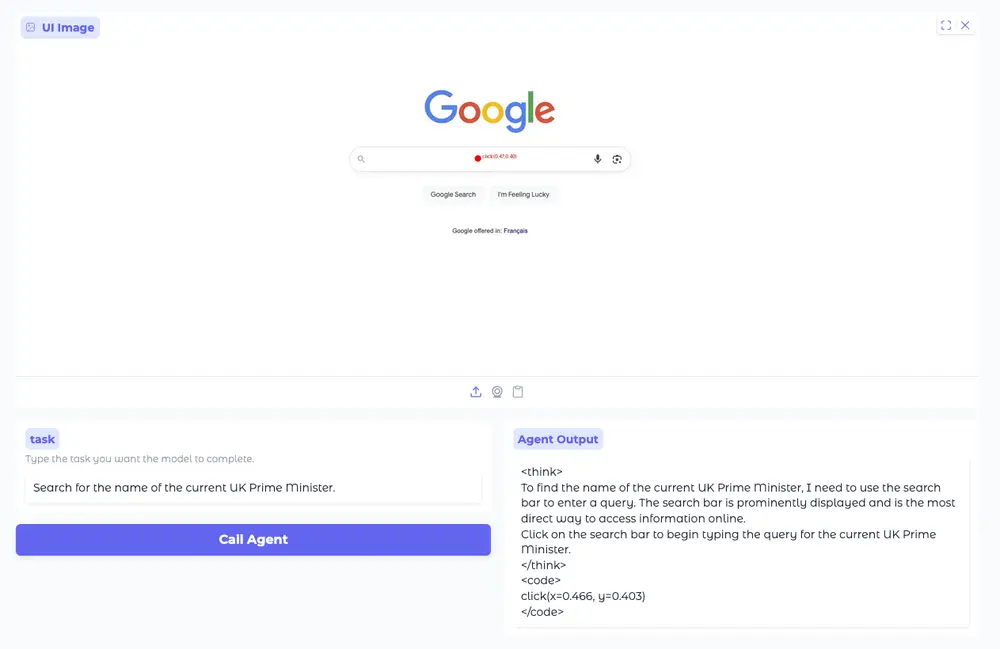
Hugging Face推出Smol2Operator:让小模型学会操作图形界面在人机交互日益复杂的今天,一个长期被忽视的问题是: 我们能让AI像人类一样“使用”计算机吗? 不是生成文本或识别图像,而是真正理解屏幕上的按钮、输入框、菜单,并通过点击、滑动、输入等动作完成任务——这...多模态模型# Hugging Face# Smol2Operator4个月前01130
Qianfan-VL:百度推出的多模态大模型系列,面向企业级视觉语言任务由百度 AI 云团队研发,Qianfan-VL 是一系列参数规模从 3B 到 70B 的多模态大语言模型(MLLM),专注于提升企业在文档理解、OCR识别和数学推理等高频场景下的自动化能力。 项目主页...多模态模型# Qianfan-VL# 多模态大模型# 百度4个月前01110
苹果发布多模态统一模型Manzano:能够同时理解和生成视觉内容苹果发布多模态统一模型Manzano,它能够同时理解和生成视觉内容。该模型通过结合一个混合图像标记化器和精心设计的训练方案,显著减少了在理解和生成能力之间的性能权衡。Manzano 在统一模型中实现了...多模态模型# Manzano# 多模态统一模型4个月前01040
Dolphin-v2:字节跳动发布支持21类元素的通用文档解析模型在办公自动化、知识管理与智能体工作流中,将非结构化文档转化为结构化数据是关键第一步。然而,现实中的文档来源复杂:既有干净的 PDF、Word,也有手机拍摄的带畸变、阴影、模糊的纸质文件。现有解析模型往...多模态模型# Dolphin-v2# 字节跳动# 文档解析模型2个月前01010
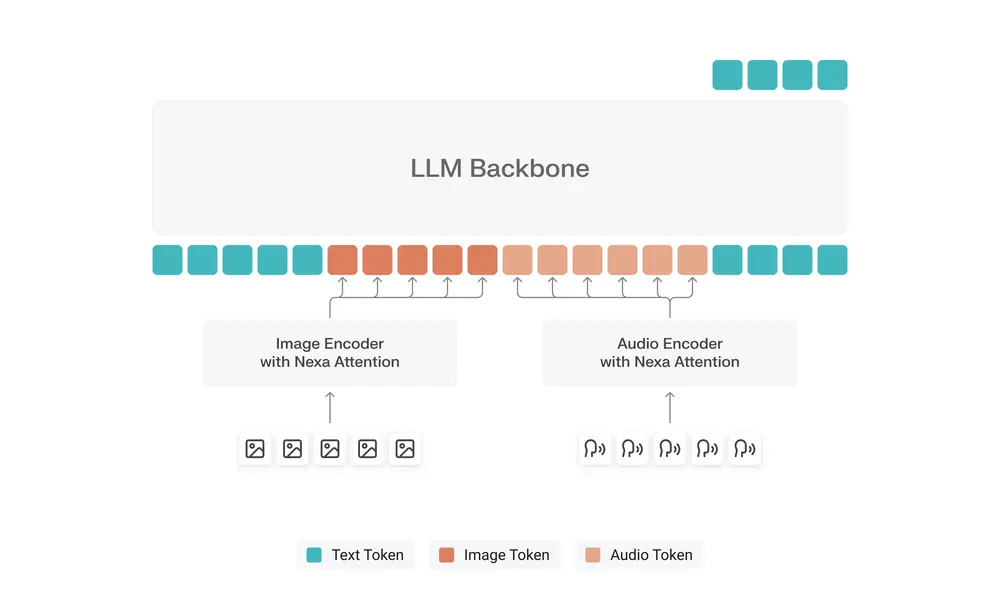
NEXA AI推出OmniNeural-4B:全球首个为 NPU 原生设计的多模态 AI 模型当AI模型需要在手机、PC等终端设备上处理文本、图像、音频时,“速度慢、耗电高、依赖网络”往往是难以回避的问题——多数模型最初为GPU设计,移植到终端的NPU(神经网络处理单元)时需“强行适配”,导致...多模态模型# Nexa AI# NPU# OmniNeural-4B5个月前0940
视频多模态大语言模型RynnEC:专为具身认知任务设计阿里达摩院、湖畔实验室和浙江大学的研究人员推出视频多模态大语言模型RynnEC,专为具身认知任务设计。它通过结合区域编码器和掩码解码器,能够灵活地处理视频中的区域级交互,从而为具身代理提供对物理世界的...多模态模型# RynnEC# 视频多模态大语言模型5个月前0930
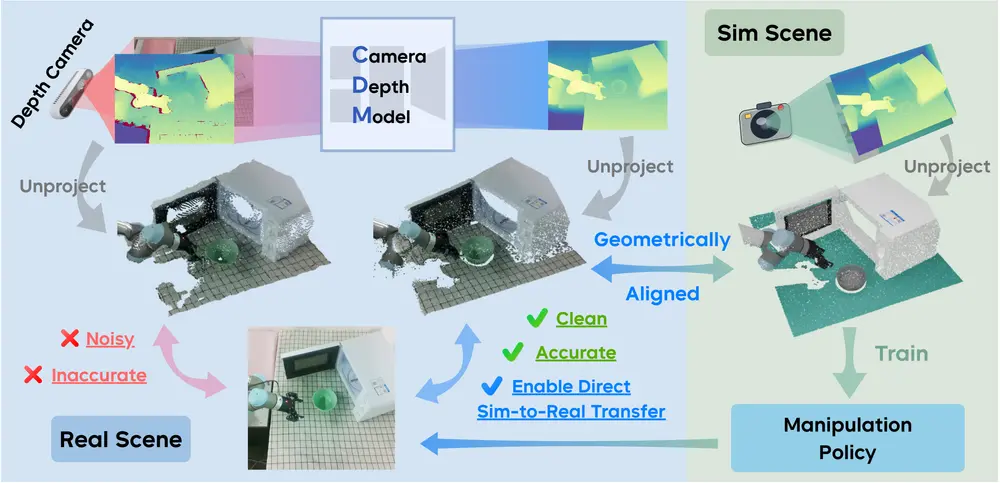
CDMs:让机器人“看清”三维世界,实现从仿真到现实的无缝迁移在机器人技能学习中,视觉感知是决策与操作的基础。然而,当前大多数方法依赖2D彩色图像作为输入——这种模式虽能捕捉纹理和颜色,却难以准确理解物体的距离、大小、形状等关键几何信息。 相比之下,人类在与环境...多模态模型# CDMs# 机器人5个月前0890
IBM 推出 Granite Docling:专为文档转换优化的轻量级多模态模型IBM Research 正式发布 Granite Docling-258M,一款基于 IDEFICS3 架构构建的新型多模态图像-文本到文本模型,专为高效、准确的文档理解与结构化转换而设计。 Git...多模态模型# Granite Docling-258M# 多模态模型# 文档转换4个月前0880
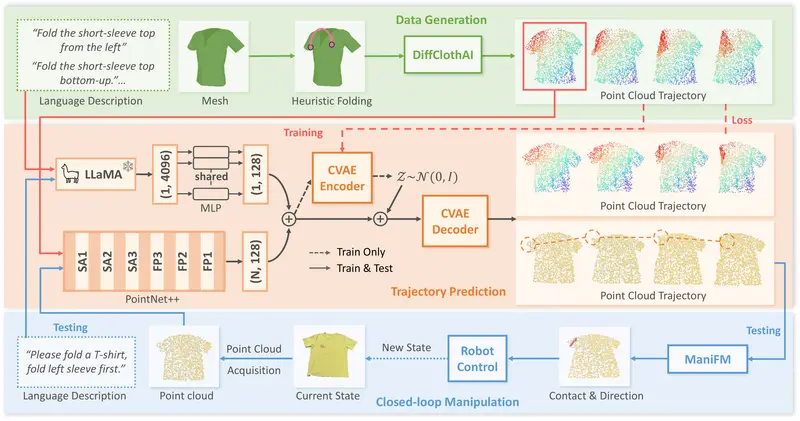
MetaFold:用语言指导机器人叠衣服,还能通用于不同衣物让机器人叠衣服,听起来简单,做起来极难。 布料柔软、易变形,同一件T恤每次摆放的形态都不同。这种高度的可变性使得机器人难以像抓取刚性物体那样,靠预设动作完成操作。更别说还要应对不同款式——无袖、短袖...多模态模型# MetaFold5个月前0880
苹果推出视觉语言模型FastVLM:用更少的视觉 Token,更快理解高分辨率图像苹果近期发布了 FastVLM系列视觉语言模型,并首次引入其自研混合视觉编码器 FastViTHD。该模型解决当前多模态系统在处理高分辨率图像时面临的效率瓶颈,尤其在移动端和实时交互场景中展现出显著优...多模态模型# FastVLM# 苹果# 视觉语言模型5个月前0850