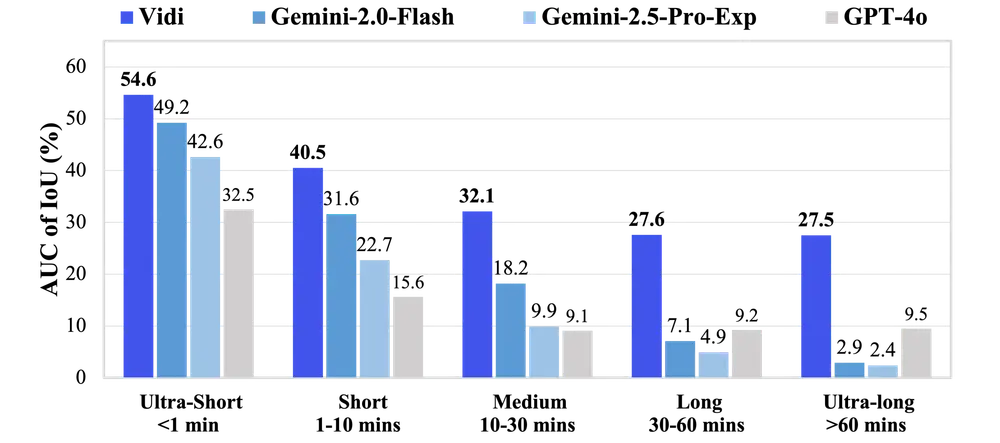
字节跳动推出多模态模型Vidi:专门用于视频理解和编辑字节跳动推出多模态模型Vidi,专门用于视频理解和编辑。Vidi 的主要目标是支持高质量、大规模视频内容的创作,通过处理原始输入材料(如未编辑的视频片段)和编辑组件(如视觉效果),帮助用户更高效地完成...多模态模型# Vidi# 多模态模型# 字节跳动10个月前02200
英伟达推出多模态大语言模型Describe Anything 3B:为图像和视频局部描述量身定制的多模态 AI 模型英伟达、加州大学伯克利分校和加州大学旧金山分校的研究人员推出了 Describe Anything 3B (DAM-3B),这是一个专门用于生成细粒度图像和视频字幕的多模态大语言模型(LLM)。DAM...多模态模型# Describe Anything 3B# 多模态大语言模型# 英伟达10个月前05960
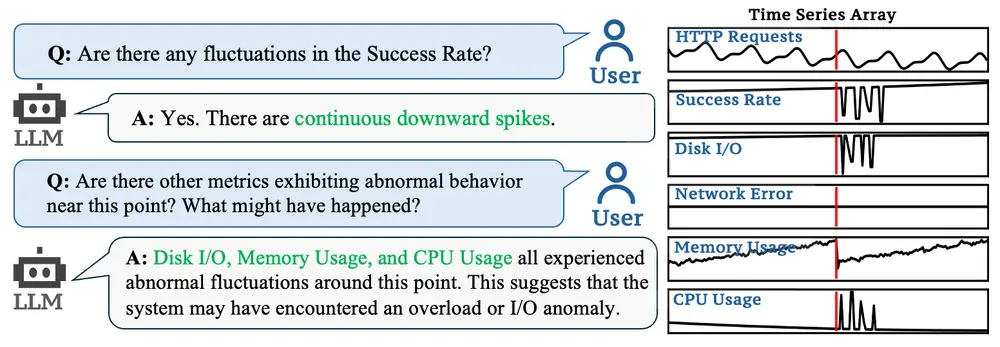
字节跳动推出多模态大语言模型ChatTS:专门用于时间序列分析清华大学和字节跳动的研究人员推出多模态大语言模型ChatTS ,专门用于时间序列分析。它通过自然语言命令帮助用户快速理解时间序列数据,执行日常任务,并处理复杂的推理问题。ChatTS 的核心优势在于其...多模态模型# ChatTS# 多模态大语言模型# 字节跳动10个月前02650
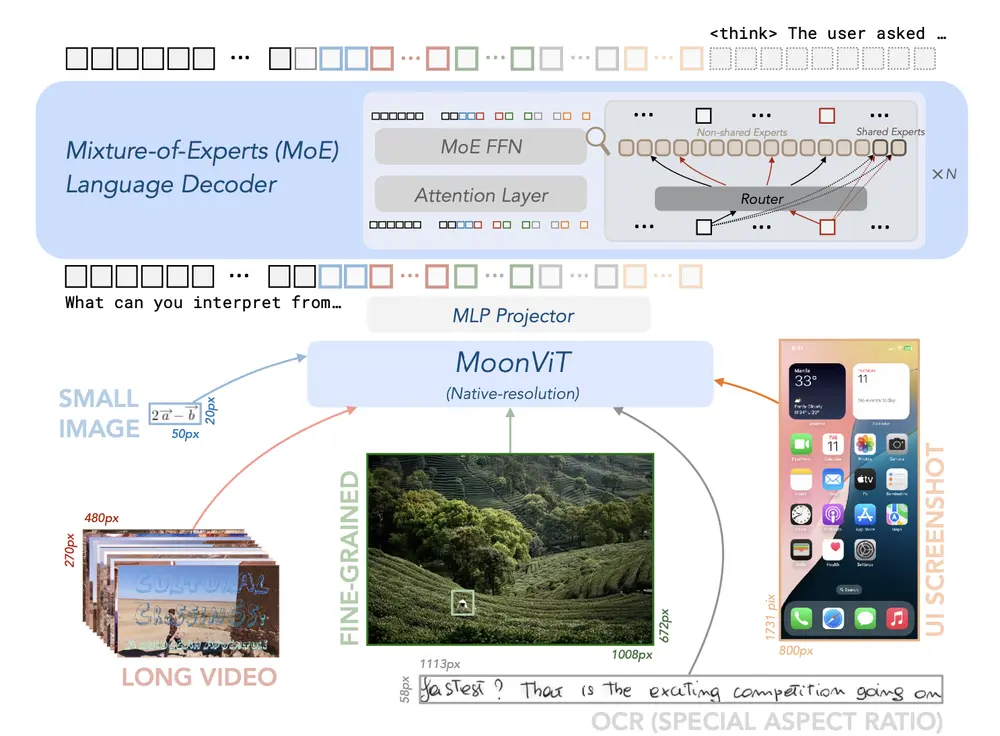
月之暗面推出高效开源视觉-语言模型Kimi-VL随着AI技术的快速发展,视觉-语言模型(VLM)在多模态任务中的应用越来越广泛。然而,如何在保持高性能的同时降低计算成本,一直是研究者面临的挑战。近日,国内知名AI公司“月之暗面”推出了 一款高效的开...多模态模型# Kimi-VL# 月之暗面10个月前04110
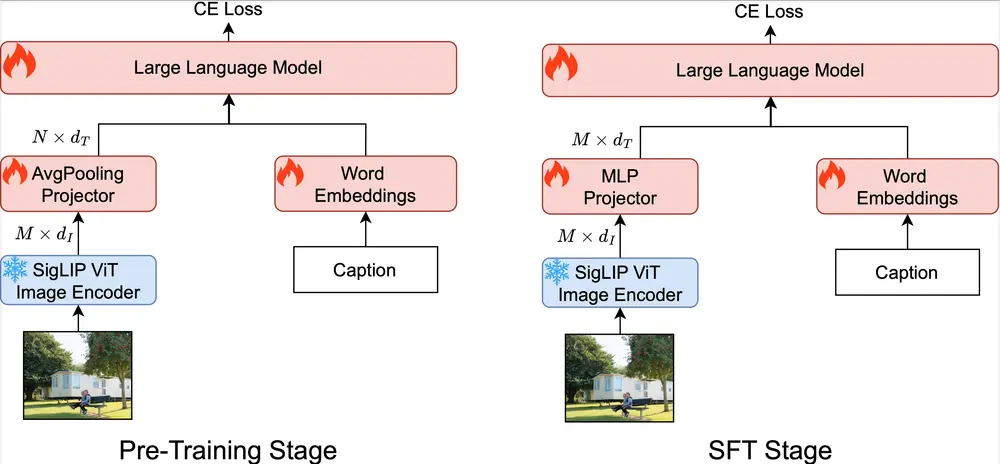
拥有20亿参数的多模态大语言模型Open-Qwen2VL在多模态大语言模型(MLLMs)的研究与应用中,视觉与文本模态的融合正在不断拓展其边界,从图像描述到视觉问答,再到复杂文档的解读,这些模型展现出了强大的能力。然而,这一领域的进一步发展面临着诸多挑战...多模态模型# Open-Qwen2VL# 多模态大语言模型11个月前01890
统一视觉自回归模型 VARGPT-v1.1:统一视觉理解和图像生成任务北京大学和香港中文大学的研究人员推出先进统一视觉自回归模型 VARGPT-v1.1 ,该模型在多模态理解和文本到图像生成任务中表现出色。它通过迭代指令微调和强化学习等创新训练策略,显著提升了模型的性能...多模态模型# VARGPT-v1.1# 统一视觉自回归模型11个月前03810
腾讯推出AnimeGamer:通过多模态大语言模型实现无限动漫生活模拟近年来,图像和视频合成技术的发展为生成游戏带来了新的可能性。特别是将动漫电影中的角色转化为可互动、可玩的实体,让玩家能够以自己喜爱的角色身份沉浸在动态的动漫世界中,通过语言指令进行生活模拟。这种游戏被...多模态模型# AnimeGamer# 多模态大语言模型# 无限动漫生活模拟11个月前04360
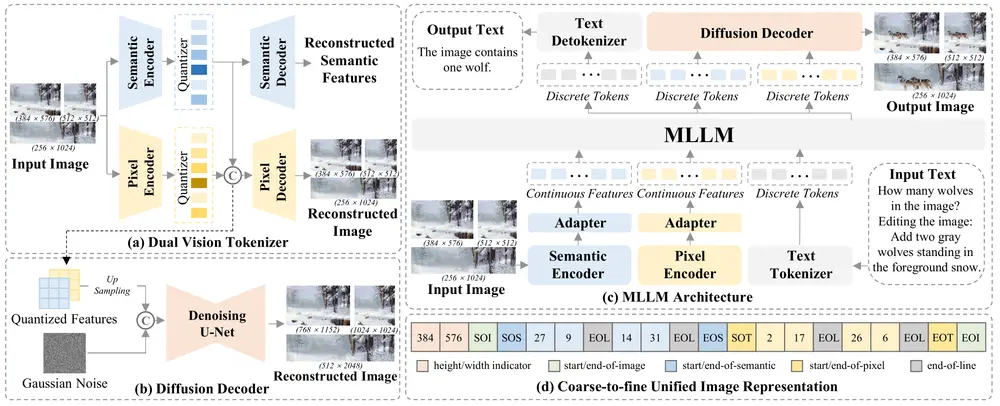
增强版多模态大语言模型ILLUME+ :通过双视觉标记化和扩散解码器来提升深度语义理解和高保真图像生成的能力近年来,多模态大语言模型(MLLMs)在图像理解、生成和编辑任务中取得了显著进展。然而,现有的统一模型在同时处理这三种任务时面临挑战。例如,早期的模型(如 Chameleon 和 EMU3)使用 VQ...多模态模型# ILLUME# 图像生成# 多模态大语言模型11个月前05240
阿里巴巴发布 QVQ-Max:能看、能理解、能思考的视觉推理模型阿里巴巴推出一款名为 QVQ-Max 的全新视觉推理模型,这是其 Qwen模型系列中的最新成员。QVQ-Max 的独特之处在于它能够理解照片和视频的内容,并对这些信息进行分析和推理,从而提供解决方案...多模态模型# QVQ-Max# 视觉推理模型# 阿里巴巴11个月前02800
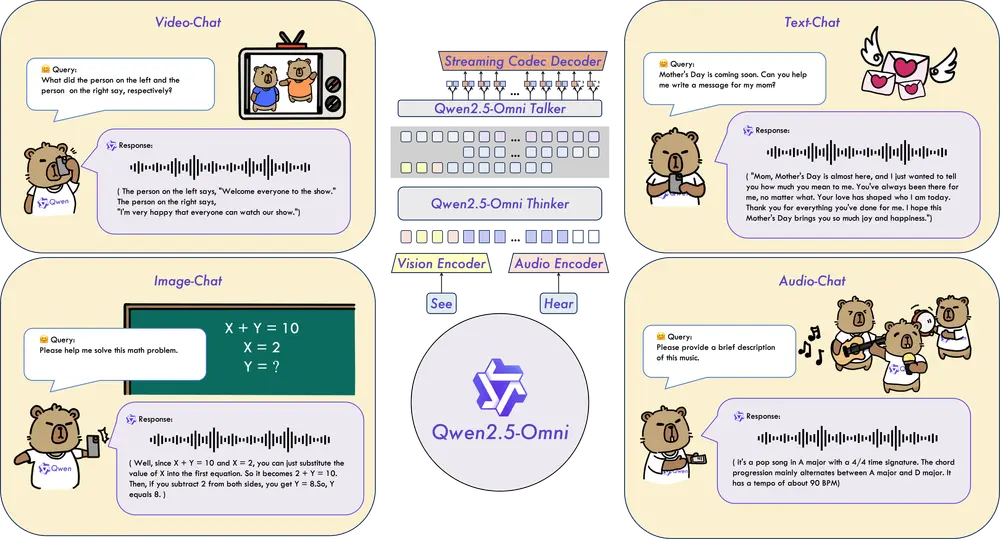
阿里通义实验室发布新一代端到端多模态旗舰模型Qwen2.5-Omni阿里通义实验室发布了 Qwen2.5-Omni,这是 Qwen 模型家族中的新一代端到端多模态旗舰模型。Qwen2.5-Omni 专为全方位多模态感知设计,能够无缝处理文本、图像、音频和视频等多种输入...多模态模型# Qwen2.5-Omni# 多模态模型11个月前02650
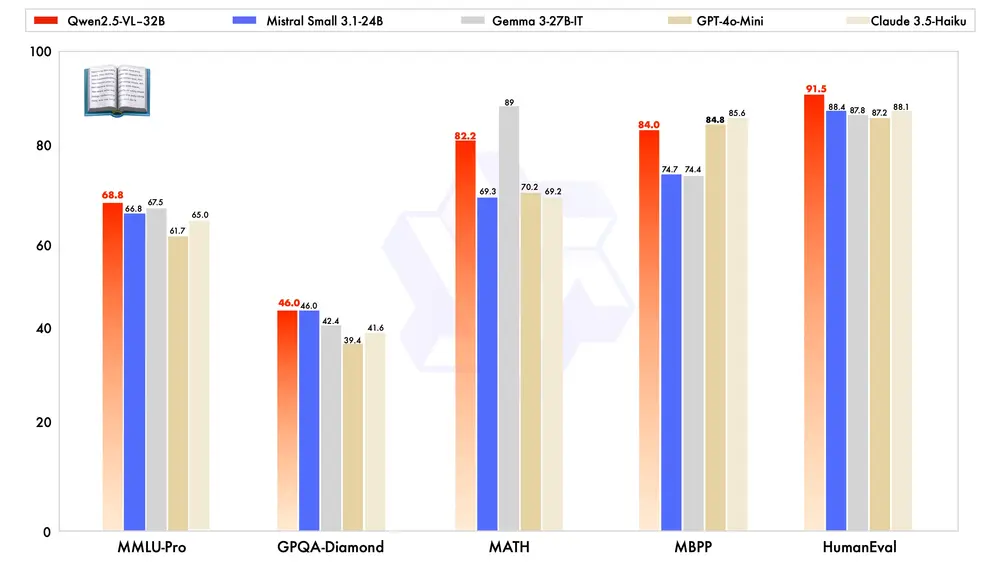
阿里通义实验室开源32B参数的多模态模型 Qwen2.5-VL-32B-Instruct今年一月底,阿里通义实验室推出了 Qwen2.5-VL 系列模型,凭借其卓越的性能和广泛的应用潜力,迅速获得了社区的广泛关注和积极反馈。在此基础上,团队通过强化学习持续优化模型,并于近期开源了备受期待...多模态模型# Qwen2.5-VL-32B-Instruct# 多模态模型# 阿里通义实验室11个月前03150
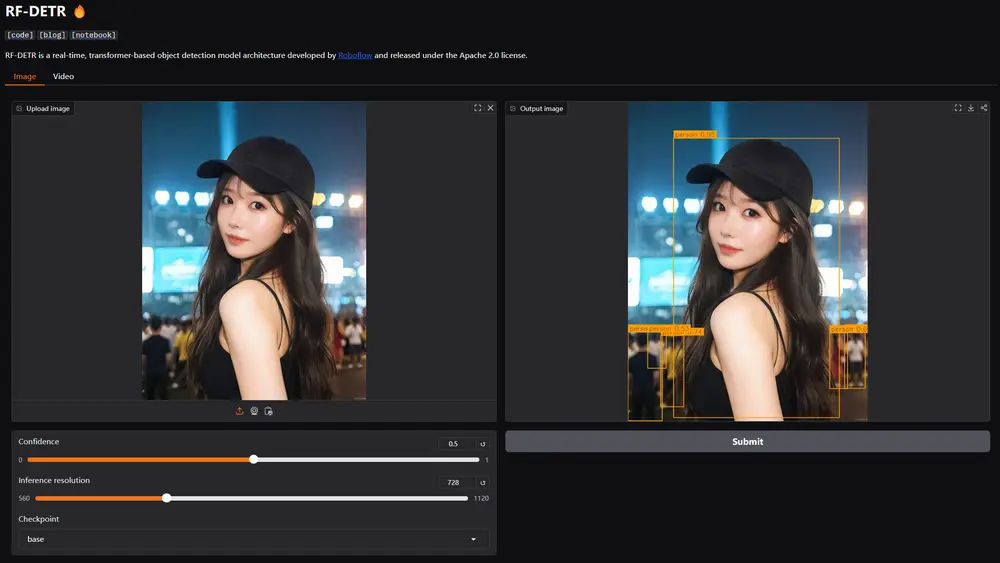
Roboflow开源基于Transformer的实时目标检测模型 RF-DETRRoboflow 近日正式发布了 RF-DETR,一种基于Transformer的实时目标检测模型。RF-DETR 在多个现实世界数据集上的表现超越了所有现有的目标检测模型,并且是首个在 COCO 数...多模态模型# RF-DETR# Roboflow# 实时目标检测模型11个月前02650