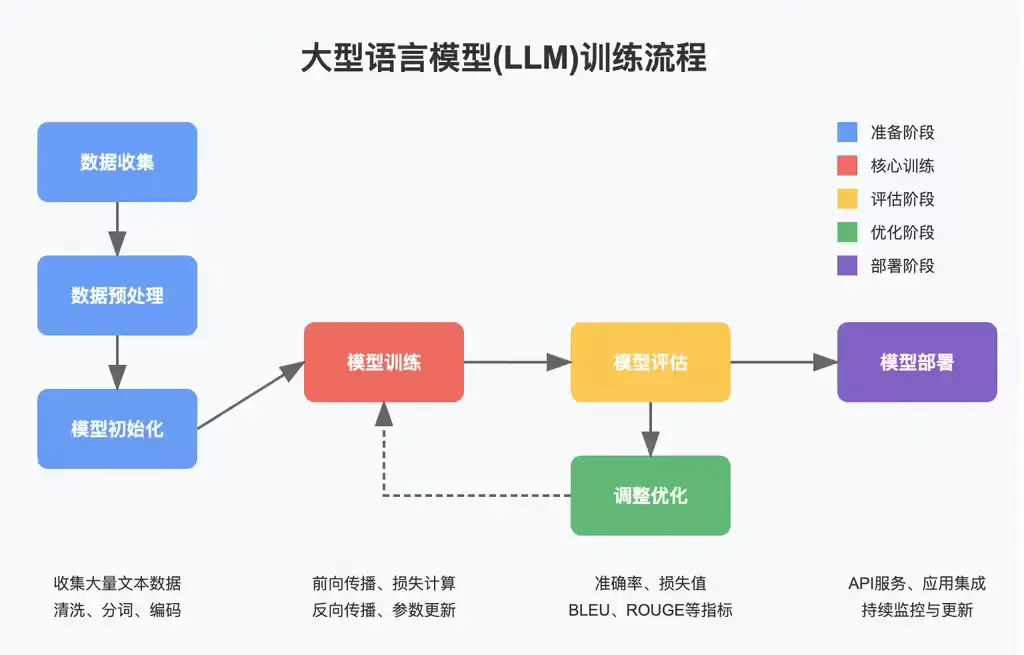
智谱发布新一代 GLM-4-32B-0414 系列模型:高性能、多功能、易部署4 月 14 日,智谱发布了一则重磅消息:推出新一代 GLM-4-32B-0414 系列模型。这一系列模型凭借 320 亿参数的强大性能,效果直逼 OpenAI 的 GPT 系列和 DeepSeek ...大语言模型# GLM-4-32B-0414# 智谱AI1年前04280
OpenAI发布全新GPT-4.1系列模型:GPT-4.1、GPT-4.1 mini和GPT-4.1 nano本周一,OpenAI发布了全新的模型系列——GPT-4.1,包括GPT-4.1、GPT-4.1 mini和GPT-4.1 nano。这些模型在编程和指令遵循方面表现出色,标志着OpenAI在打造“代理...大语言模型早报# GPT-4.1# GPT-4.1 mini# GPT-4.1 nano1年前05770
字节跳动推出视频生成模型Seaweed-7B:以较低的计算成本实现高效的训练和生成近年来,随着视频生成技术的快速发展,如何在资源有限的情况下实现高性能的模型训练成为研究热点。字节跳动提出了一种创新的训练策略,推出了一个中等规模的视频生成模型——Seaweed-7B。这个模型拥有约7...视频模型# Seaweed-7B# 字节跳动# 视频生成模型1年前02900
Hi3DGen:通过法线图作为中间表示,从二维图像生成高保真度的3D几何模型香港中文大学(深圳)、字节跳动和清华大学的研究人员推出通过法线桥接从图像生成高保真度3D几何模型Hi3DGen,通过法线图作为中间表示,从二维图像生成高保真度的三维几何模型。该框架通过解决现有方法在生...3D模型# 3D模型# Hi3DGen1年前04650
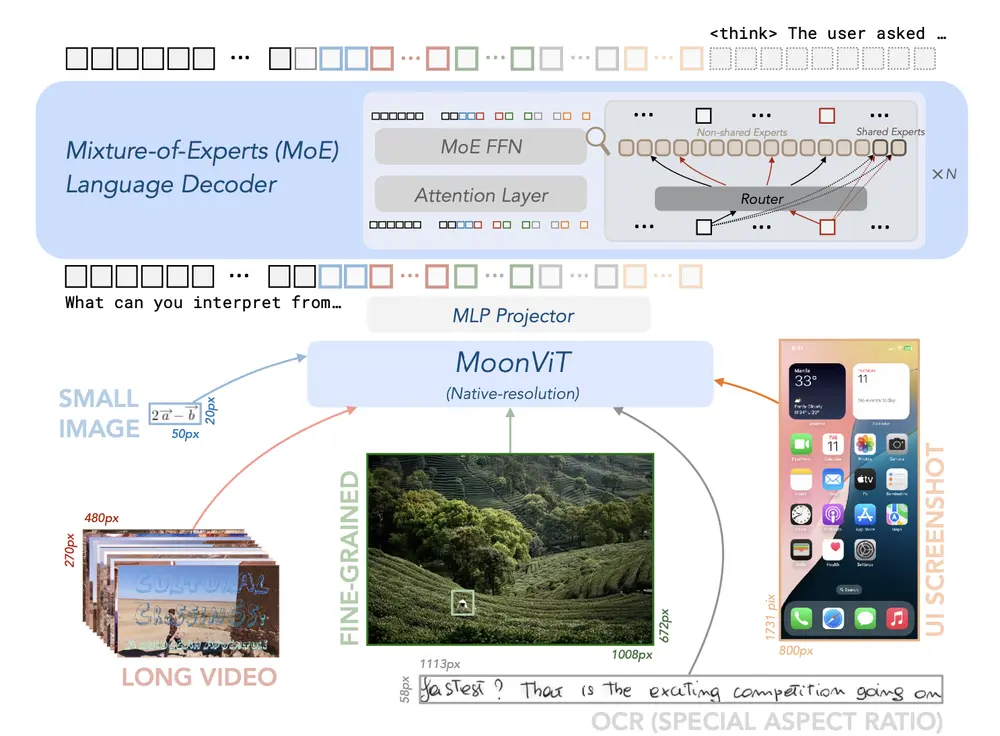
月之暗面推出高效开源视觉-语言模型Kimi-VL随着AI技术的快速发展,视觉-语言模型(VLM)在多模态任务中的应用越来越广泛。然而,如何在保持高性能的同时降低计算成本,一直是研究者面临的挑战。近日,国内知名AI公司“月之暗面”推出了 一款高效的开...多模态模型# Kimi-VL# 月之暗面1年前04480
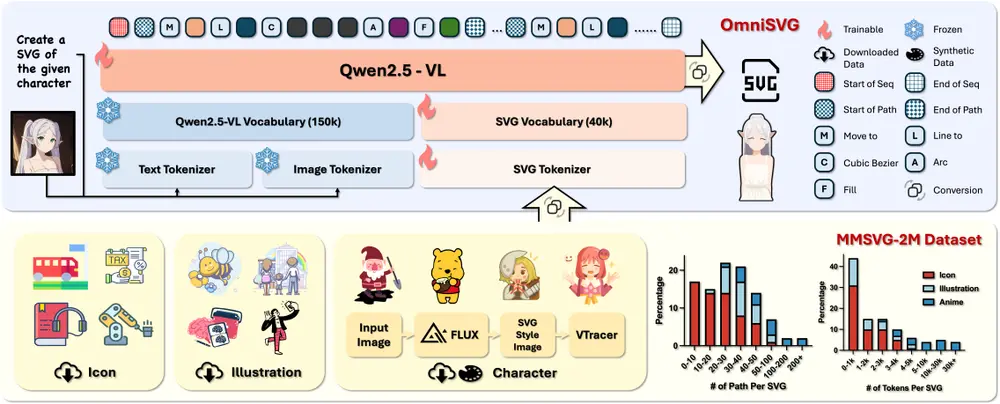
基于视觉语言模型的端到端多模态 SVG 生成框架OmniSVG:能够生成从简单图标到复杂动漫角色的高质量 SVG 图形复旦大学和阶跃星辰的研究人员推出基于视觉语言模型(VLMs)的端到端多模态 SVG 生成框架OmniSVG,能够生成从简单图标到复杂动漫角色的高质量 SVG 图形,支持文本到 SVG、图像到 SVG ...图像模型# OmniSVG# SVG# 视觉语言模型9个月前02570
基于 Mochi 微调的开源视频模型Pusa:低成本、高性能的开源视频生成模型Pusa 是基于 Mochi 微调的开源视频模型,不仅开源了整个微调过程,还以极低的训练成本(仅 100 美元)实现了多种视频生成任务的无缝支持。 GitHub:https://github.com...视频模型# Pusa# 视频生成模型1年前02000
基于像素空间流的图像生成模型PixelFlow:根据给定的文本描述生成高质量、语义一致的图像香港大学和Adobe的研究人员推出基于像素空间流的图像生成模型PixelFlow,它直接在像素空间中进行操作,与传统的基于潜在空间(latent space)的模型不同。PixelFlow通过高效的级...图像模型# PixelFlow# 图像生成模型1年前02010
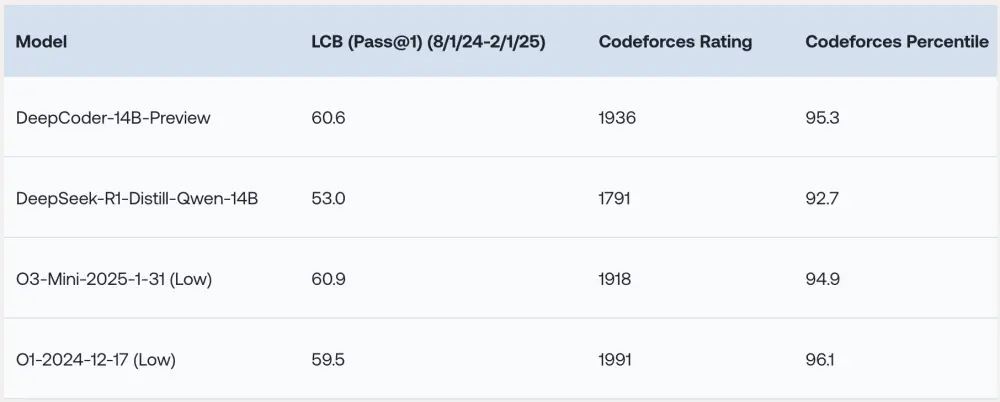
基于DeepSeek-R1构建的开源高效编码模型DeepCoder-14B由Together AI和Agentica联合推出了一款编码模型DeepCoder-14B,正以其卓越的性能和完全开源的特点,引发AI社区的广泛关注。这款基于DeepSeek-R1构建的模型,在多个编...大语言模型# DeepCoder-14B# DeepSeek-R1# 编码模型1年前02030
字节跳动推出基于Flux的通用框架UNO:支持虚拟试穿、风格化生成、产品设计等功能字节跳动近日推出了UNO,这是一个强大的通用框架,能够从单一主体到多主体进行定制化演进。UNO不仅展示了出色的泛化能力,还能将多样化的任务统一在一个模型之下,为图像生成领域带来了新的突破。 项目主页...图像模型# FLUX# UNO# 字节跳动1年前06970
智象未来开源全新的170 亿参数图像生成基础模型HiDream-I1北京智象未来科技开源了一款全新的图像生成基础模型HiDream-I1,其拥有 170 亿个参数,能够在几秒内实现顶尖的图像生成效果。这一模型提供了三种变体:Full、Dev 和 Fast,以满足不同用...图像模型# HiDream-I1# 图像生成模型# 智象未来1年前05940
英伟达发布开源大语言模型Llama-3.1 Nemotron Ultra-253B-v1:以半数参数超越DeepSeek R1英伟达今天发布了一款全新的开源大语言模型—Llama-3.1 Nemotron Ultra-253B-v1,这款拥有2530亿参数的模型在多个基准测试中表现出色,甚至超越了竞争对手DeepSeek R...大语言模型# Llama-3.1 Nemotron Ultra# Llama-3.1 Nemotron Ultra-253B-v1# 英伟达1年前02800