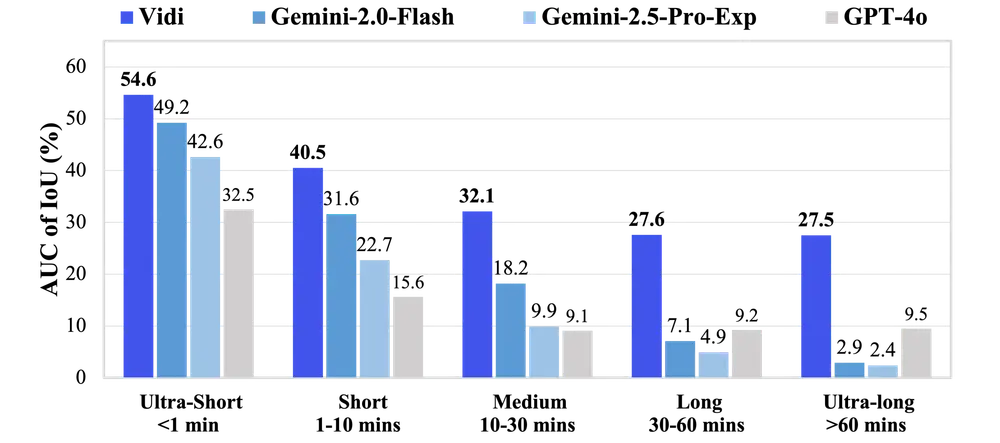
字节跳动推出多模态模型Vidi:专门用于视频理解和编辑字节跳动推出多模态模型Vidi,专门用于视频理解和编辑。Vidi 的主要目标是支持高质量、大规模视频内容的创作,通过处理原始输入材料(如未编辑的视频片段)和编辑组件(如视觉效果),帮助用户更高效地完成...多模态模型# Vidi# 多模态模型# 字节跳动12个月前02340
英伟达推出多模态大语言模型Describe Anything 3B:为图像和视频局部描述量身定制的多模态 AI 模型英伟达、加州大学伯克利分校和加州大学旧金山分校的研究人员推出了 Describe Anything 3B (DAM-3B),这是一个专门用于生成细粒度图像和视频字幕的多模态大语言模型(LLM)。DAM...多模态模型# Describe Anything 3B# 多模态大语言模型# 英伟达12个月前06210
Flex.2-preview:基于 Flux.1 Schnell 微调而成的开源 80 亿参数文生图模型Flex.2-preview 是一款开源的文本到图像扩散模型,具有 80 亿参数,支持通用控制和图像修复功能。它基于 Flux.1 Schnell 微调而成,旨在为用户提供更灵活、更强大的图像生成能力...图像模型# Flex.2-preview# FLUX.1 [schnell]# 文生图模型12个月前07560
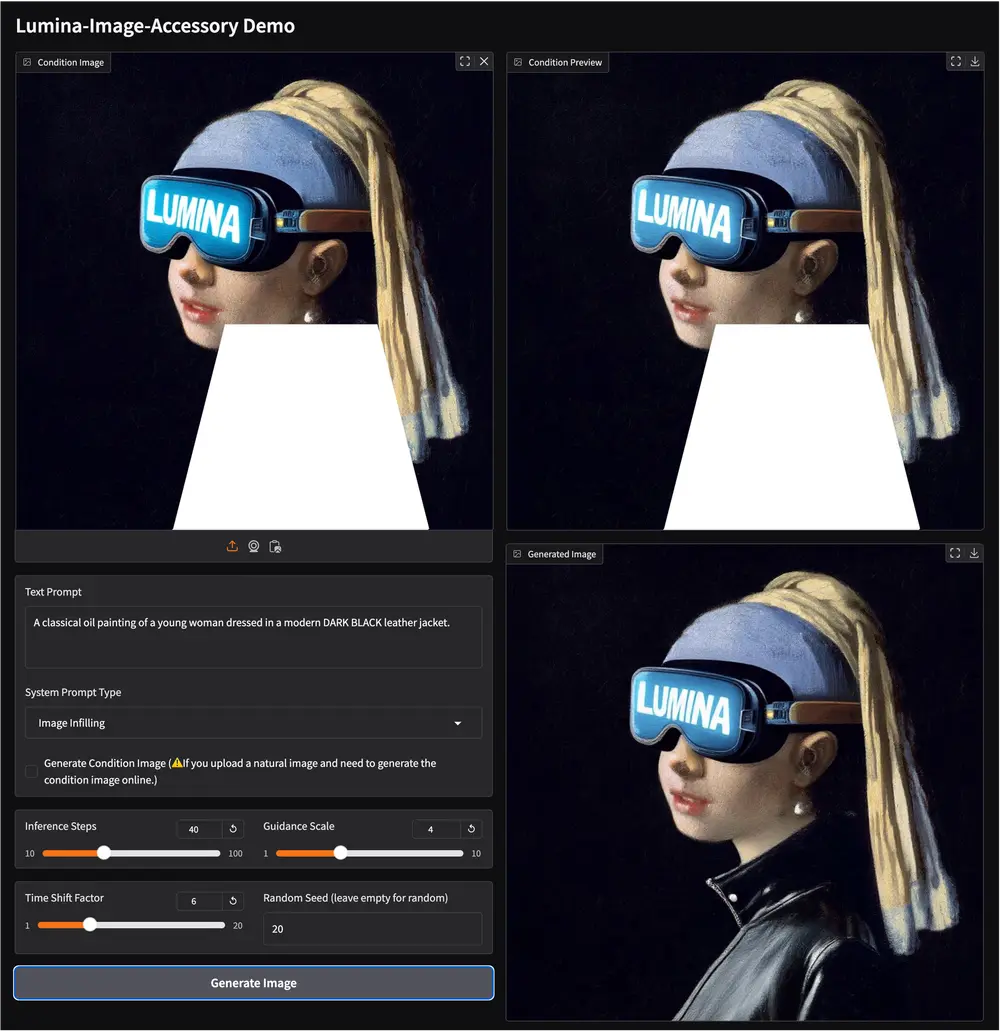
Lumina-Accessory:专为 Lumina 系列模型设计的多任务指令微调框架Lumina-Accessory 是一个专为 Lumina 系列模型设计的多任务指令微调框架,目前支持 Lumina-Image-2.0。该框架通过一系列创新设计,为图像生成和编辑任务提供了强大的支持...图像模型# Lumina-Accessory# Lumina-Image 2.0# 图像生成12个月前03990
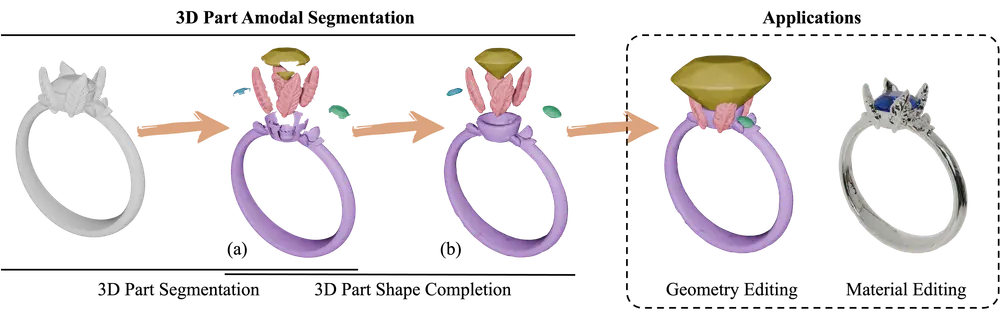
新型3D部件非模态分割模型HoloPart:将3D形状分解为完整的、语义上有意义的部件香港大学和VAST的研究人员推出新型3D部件非模态分割模型HoloPart 。该模型旨在将3D形状分解为完整的、语义上有意义的部件,即使这些部件被部分或完全遮挡。这一任务被称为 3D部件非模态分割,是...3D模型# 3D部件非模态分割模型# HoloPart12个月前05370
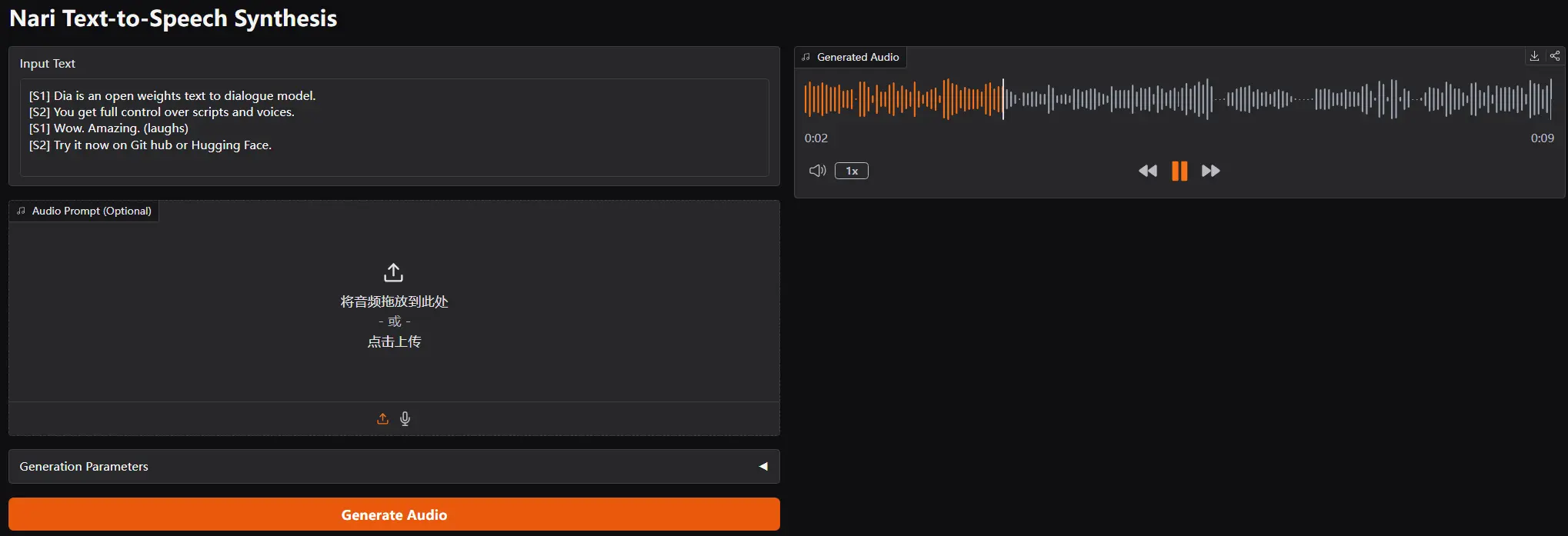
Nari Labs开源TTS模型Dia-1.6B:生成自然对话与非语言表达,支持声音克隆Nari Labs在今天开源了一个拥有16亿参数的文本转语音模型Dia-1.6B。这个模型的最大亮点在于它能够生成高度逼真的对话,并且加入了自然人声元素,比如笑声、咳嗽、清喉咙等,让语音合成更加生动自...语音模型# Dia-1.6B# Nari Labs# TTS模型12个月前02,2530
Sand AI推出新型视频生成模型MAGI-1:通过自回归预测视频块序列来生成视频MAGI-1是由Sand AI研究团队开发的一种新型视频生成模型。该模型通过自回归预测视频块序列来生成视频,每个视频块由固定长度的连续帧组成。MAGI-1的核心目标是实现高保真、实时、因果一致的视频生...视频模型# MAGI-1# Sand AI# 自回归12个月前07680
昆仑万维推出SkyReels-V2:首个基于扩散强制框架的无限长度电影生成模型近年来,视频生成领域取得了显著进展,主要得益于扩散模型和自回归框架的推动。然而,这一领域仍面临诸多关键挑战,例如提示一致性、视觉质量、动态效果和视频时长之间的权衡。为了追求更高的视觉质量,许多模型不得...视频模型# SkyReels-V2# 昆仑万维# 视频生成模型12个月前04690
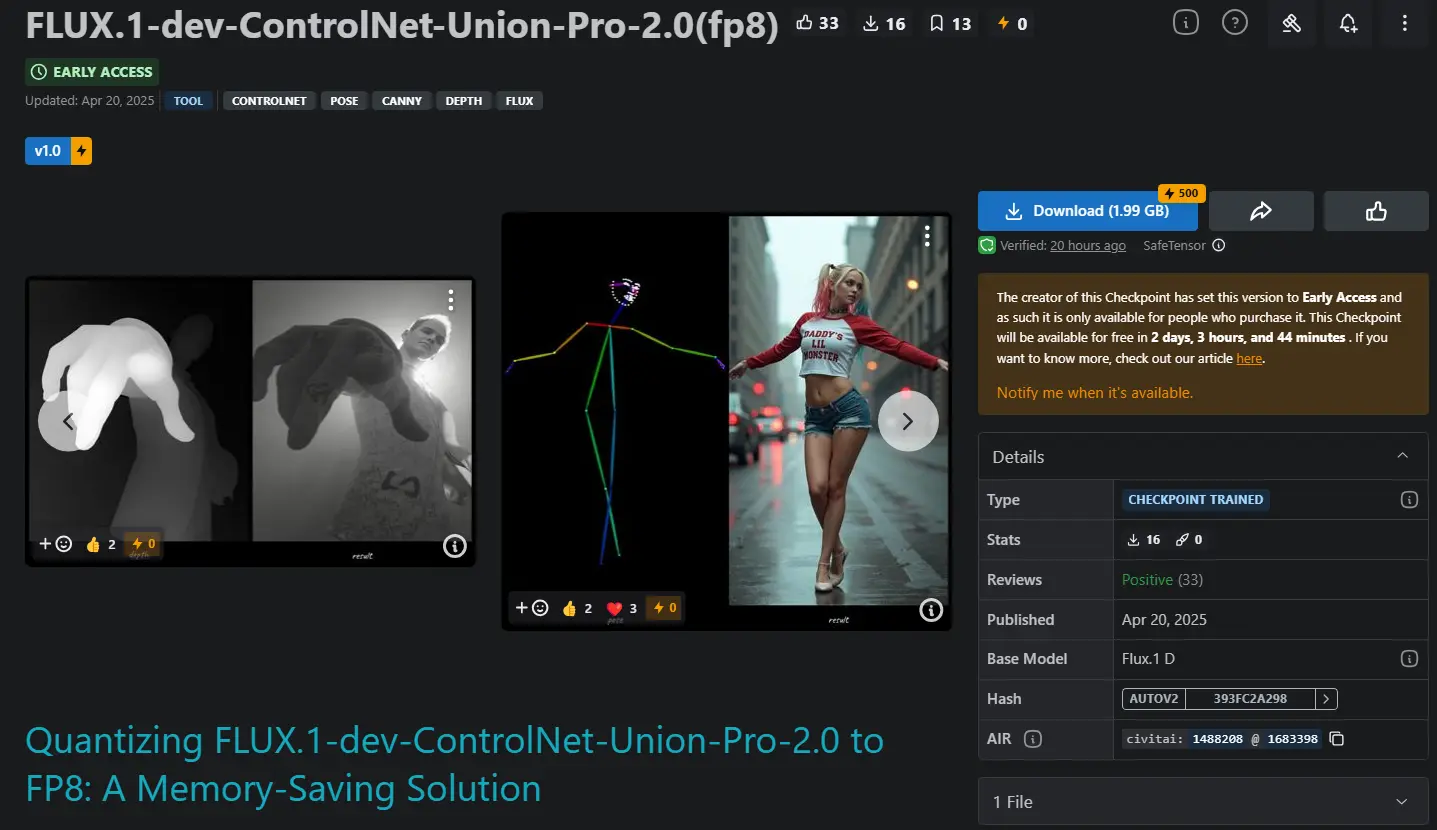
FLUX.1-dev-ControlNet-Union-Pro-2.0 FP8 量化版本:降低对于显存的需求近期Shakker Labs发布了FLUX.1-dev-ControlNet-Union-Pro-2.0,但原版模型对于显存要求过高,于是就有开发者推出了FP8 量化版本。这不是一个经过微调的模型,而...图像模型# FLUX.1-dev-ControlNet-Union-Pro-2.0# FP8 量化版本# Shakker Labs12个月前07220
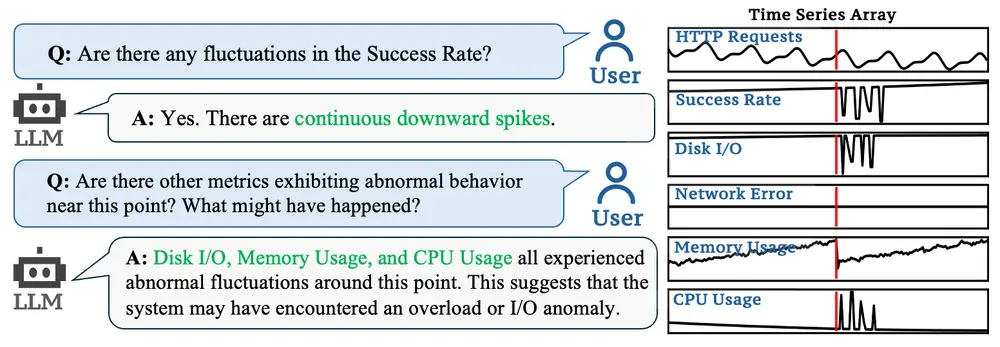
字节跳动推出多模态大语言模型ChatTS:专门用于时间序列分析清华大学和字节跳动的研究人员推出多模态大语言模型ChatTS ,专门用于时间序列分析。它通过自然语言命令帮助用户快速理解时间序列数据,执行日常任务,并处理复杂的推理问题。ChatTS 的核心优势在于其...多模态模型# ChatTS# 多模态大语言模型# 字节跳动12个月前02750
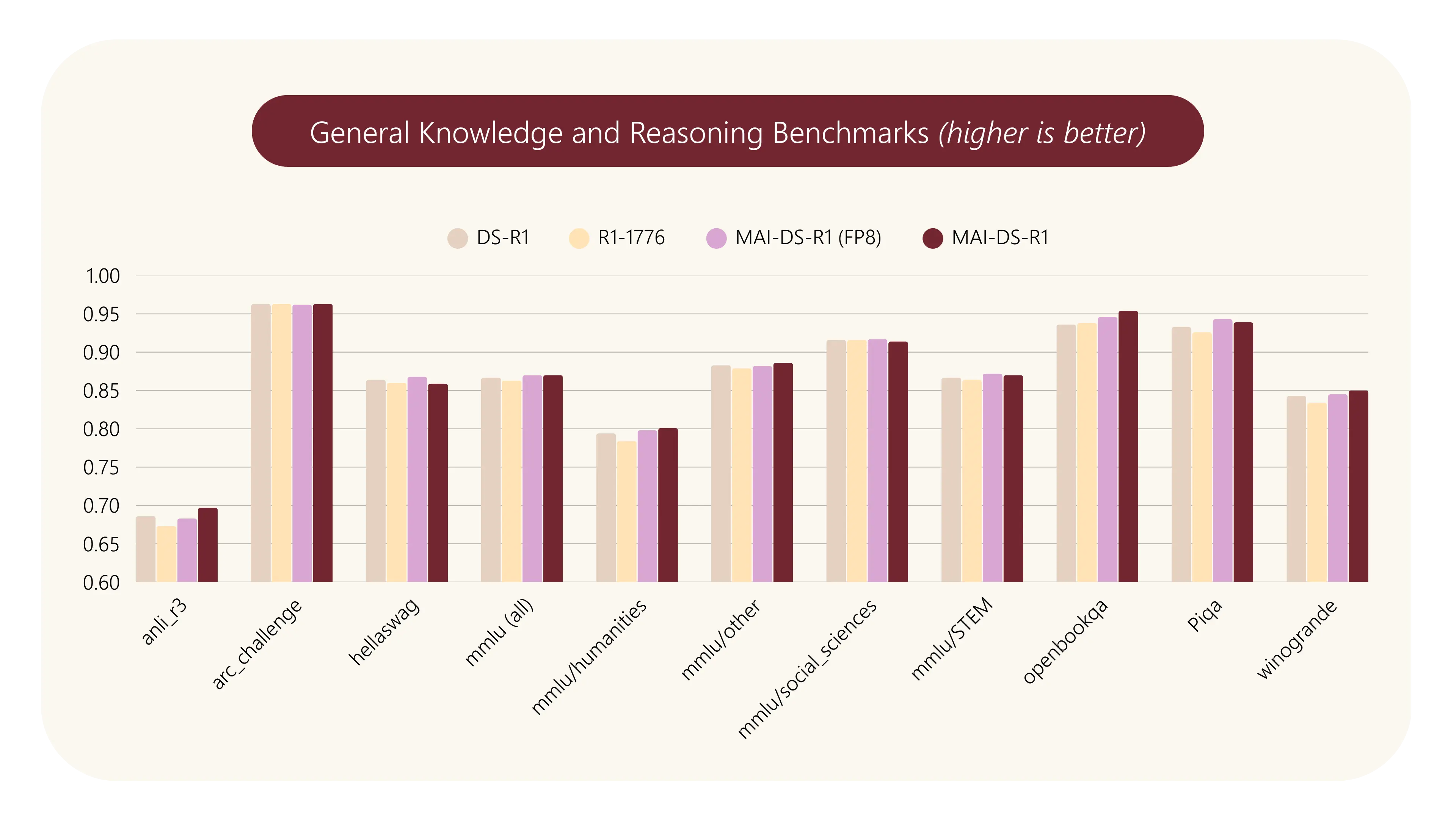
MAI-DS-R1:微软团队基于DeepSeek-R1 推理模型进行后训练的版本MAI-DS-R1 是一个由微软 AI 团队对 DeepSeek-R1 推理模型进行后训练的版本,提升其对受限话题的响应能力并改善其风险状况,同时保持推理能力和竞争力。简单来说就是把欧美的偏见加进去...大语言模型# DeepSeek-R1# MAI-DS-R1# 微软12个月前03340
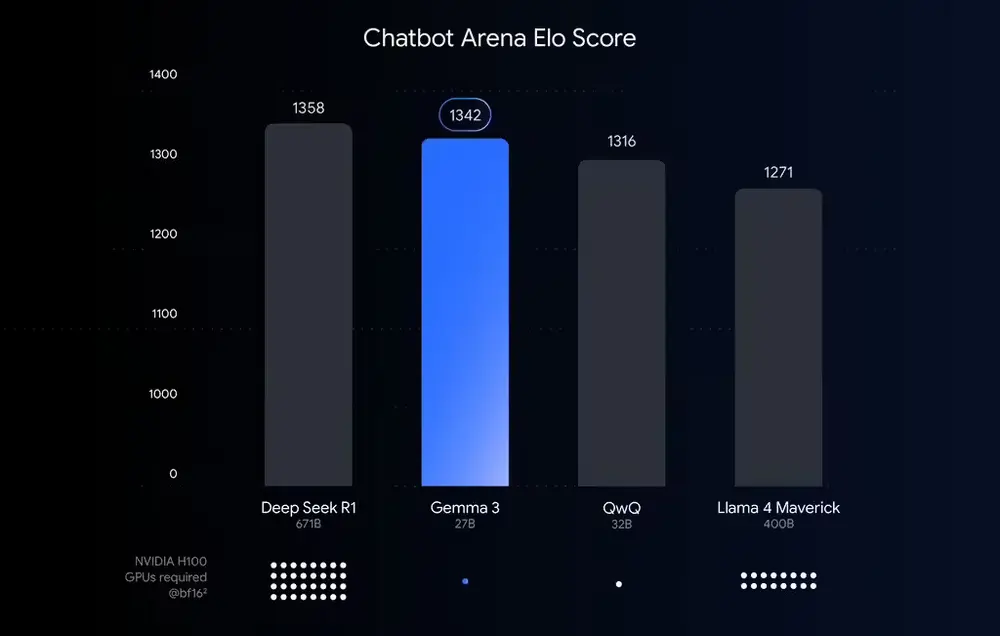
谷歌发布量化感知训练(QAT)优化版 Gemma 3 模型Gemma 3 QAT谷歌昨日(4月18日)通过官方博文发布了量化感知训练(QAT)优化版的Gemma 3模型。这一版本在保持高质量输出的同时,显著降低了对硬件内存的需求,为本地部署和普通硬件用户带来了福音。 MLX 版本...大语言模型# Gemma 3# Gemma 3 QAT# 谷歌12个月前02190